
一 前端页面的组成分析详解
1 常见标签
标签语言,常见的标签有:
a: 超链接
img: 图片
input:输入框、文件上传
button:按钮
select:下拉框
iframe:窗体
p:文字
。。。。。
2 标签语法
页面元素 == 标签
标签的基本格式:
<tagName attribute1="xxxx" attribute2="www">text</tagName>
标签还有另一种简单的写法
<tagName1 attribute1="xxxx" attribute2 />
3 需要注意的的点
- 页面元素是在视觉上有欺骗效果
css提供元素样式,但元素定位时,我们关键是看标签的名字。 - 属性和text的区别
尖括号外面的是text,尖括号里面的是属性 - 元素定位,就等于定位页面标签
二 页面元素定位详解
1. ID元素定位
基于元素属性中的id的值来进行定位,id是一个标签的唯一属性值,可以通过id属性来唯一定位一个元素,是首选的元素定位方式,动态ID不做考虑。
driver.find_element_by_id('id')
driver.find_element(By.ID, 'id')
2. name元素定位
基于元素属性中的name的值来进行定位,但name并不是唯一的,很可能会出现重名。
driver.find_element_by_name('name')
driver.find_element(By.NAME,'name')
3. class_name元素定位
基于元素class样式来定位,非常容易遇到重复的,这个方法的参数只能是一个class值,列如:class属性有空格隔开两个class的值时,只能选取其中一个进行定位。
driver.find_element_by_class_name('class_name')
driver.find_element(By.CLASS_NAME,'class_name')
4. tag_name元素定位
通过元素的标签名来定位元素,如:input标签、span标签;标签名来进行定位元素,重复度最高,只有在需要定位后进行二次筛选的情况下使用。
···
driver.find_element_by_tag_name(‘tag_name’)
driver.find_element(By.TAG_NAME, ‘tag_name’)
···
5. css_selector元素定位
css可以通过元素的id、class、属性、子元素、后代元素、index、兄弟元素等多种方式进行元素定位.
5.1通过ID定位,如:input id=”kw”
driver.find_element_by_css_selector('div#kw')
driver.find_element(By.CSS_SELECTOR, 'div#kw')
5.2 通过class定位,如:input class=”is_put”
driver.find_element_by_css_selector('input.is_put')
driver.find_element(By.CSS_SELECTOR, 'input.is_put')
5.3 通过属性定位,如:input name=”kw”
driver.find_element_by_css_selector('input[name=kw]')
driver.find_element(By.CSS_SELECTOR, 'input[name=kw]')
5.4 通过子元素定位
与xpath不同,css中用”>”右箭头代表子元素,而xpath中用的”/”单斜杠表示
driver.find_element_by_css_selector('div#kw>a')
driver.find_element(By.CSS_SELECTOR, 'div#kw>a')
5.5 通过后代元素定位
driver.find_element_by_css_selector('div#kw a')
driver.find_element(By.CSS_SELECTOR, 'div#kw a')
5.6 通过元素的index值定位元素
driver.find_element_by_css_selector('div#kw>a:nth-child(1)')
driver.find_element(By.CSS_SELECTOR, 'div#kw>a:nth-child(1)')
5.7 通过元素兄弟元素定位元素
css的定位到的是兄弟元素下面的兄弟元素,而且只是下面的第1个元素(如:span元素id为”kw”有很多input兄弟元素,它只定位到它下面的第1个兄弟元素);而xpath不同的是可以定位到所有兄弟元素;
driver.find_element_by_css_selector('span#kw+input)')
driver.find_element(By.CSS_SELECTOR, 'span#kw+input')
5.8 CSS常见语法一览表

6. link_text元素定位
主要用于超链接进行定位,全部匹配文本值,使用在链接位置处,例如:a标签
driver.find_element_by_link_text('link_text')
driver.find_element(By.LINK_TEXT, 'link_text')
7. partial_link_text元素定位
基于链接的部分文字来定位,link text模糊匹配,模糊查询匹配到多个符合调节的元素,选取第一个,同样也只使用在链接位置处,例如:a标签
driver.find_element_by_partial_link_text('partial_link_text')
driver.find_element(By.PARTIAL_LINK_TEXT, 'partial_link_text')
8. xpath元素定位
xpath是一门在xml文档中查找信息的语言。xpath可用来在xml文档中对元素和属性进行遍历。由于html的层次结构与xml的层次结构天然一致,所以使用xpath也能够进行html元素的定位。xpath的功能非常强大,通过xpath的各种方式组合,能够解决selenium自动化测试中界面元素定位的绝大部分问题。
8.1 xpath通过绝对路径定位元素
将 Xpath 表达式从 html 的最外层节点,逐层填写,最后定位到操作元素,这种方法,一旦路径有变化会导致定位失败,所以不推荐使用该方式。
driver.find_element_by_xpath('/html/body/div[4]/div[1]/a')
driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/a')
8.2 xpath通过相对路径定位元素
绝对路径与相对路径的差别与文件系统中的绝对和相对路径类似,相对路径是只给出元素路径的部分信息,在html的任意层次中寻找符合条件的元素,语句以//开始。
driver.find_element_by_xpath('//form/span')
driver.find_element(By.XPATH, '//form/span')
8.3 xpath通过元素属性定位元素
单属性定位://input[@name=’pwd’]表示name属性为pwd的input
driver.find_element_by_xpath("//input[@name='pwd']")
driver.find_element(By.XPATH, "//input[@name='pwd']")
多属性定位://a[@title=”tutorial” and @rel=”follow”]
driver.find_element_by_xpath('//a[@title="tutorial" and @rel="follow"]')
driver.find_element(By.XPATH, '//a[@title="tutorial" and @rel="follow"]')
8.4 xpath通过属性值模糊匹配定位元素
xpath模糊匹配的函数有两种:starts-with和contains
starts-with://label[starts-with(@class,’btn’)],class属性值以btn开头的label元素
driver.find_element_by_xpath("//label[starts-with(@class,'btn')]")
driver.find_element(By.XPATH, "//label[starts-with(@class,'btn')]")
contains://label[contains(@class,’btn’)],通过属性值包含btn的label元素
driver.find_element_by_xpath("//label[contains(@class,'btn')]")
driver.find_element(By.XPATH, "//label[contains(@class,'btn')]")
8.5 xpath通过文本定位元素
文本内容的定位是利用html的text字段进行定位的方法,//span[text()=’下一步’],由于 “下一步” 这几个字是浏览器界面就可以看到的, “所见即所得”,这种特征改的可能性非常小,优先推荐使用。与属性值类似,文本内容也支持starts-with和contains模糊匹配。
driver.find_element_by_xpath("//span[text()='下一步']")
driver.find_element(By.XPATH, "//span[text()='下一步']")
driver.find_element(By.XPATH, "//span[starts-with(text(),'下一步')]")
driver.find_element(By.XPATH, "//span[contains(text(),'下一步')]")
8.6 xpath常见语法一览表

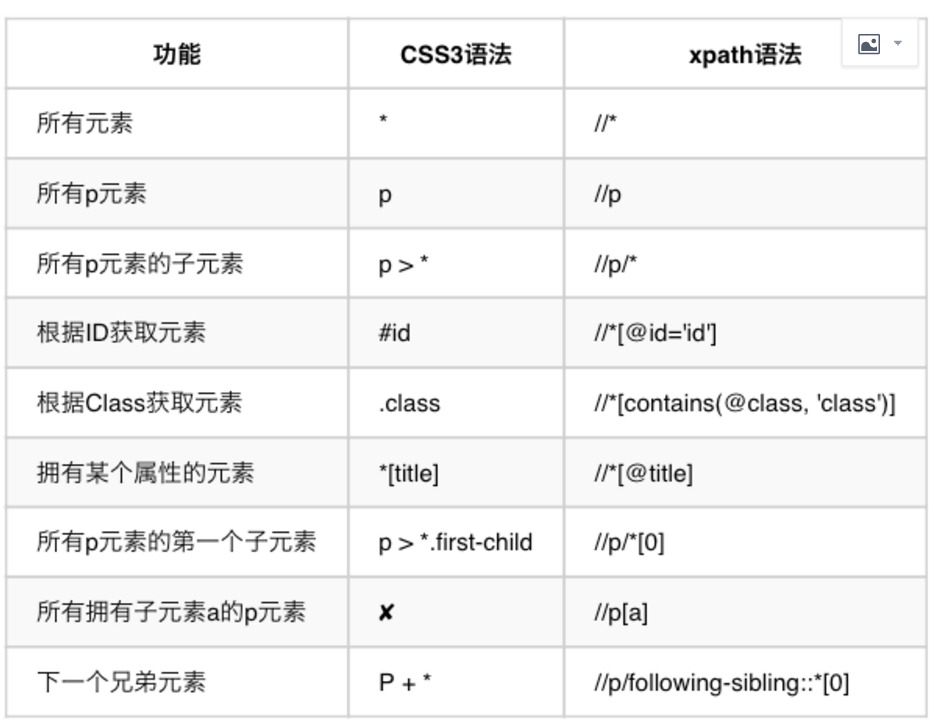
9. XPATH 和 CSS 基本语法对比
10. Selenium4.0 Relative Locators (网格定位/相对定位)
Selenium 4引入了Relative Locators(相对定位器方法),以前称为Friendly Locators。当不容易构造所需元素的定位器,但容易在空间上描述元素与具有容易构造定位器的元素的关系时,这些定位器是有帮助的。Relative Locators(相对定位器方法)可以将先前定位的元素引用或另一个定位器作为原点的参数。
我们以下面的登陆为案例来理解相对定位
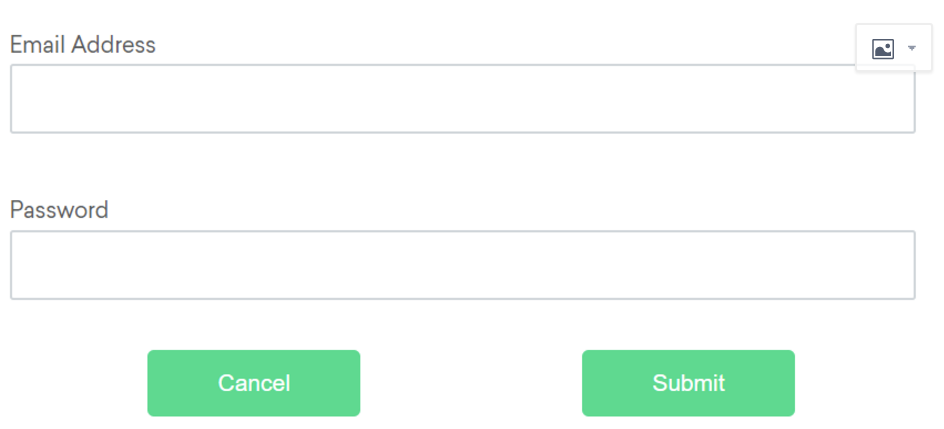
10.1 Above(上方)
如果由于某种原因,电子邮件文本字段元素不容易识别,而密码文本字段元素容易识别,那么我们可以使用“输入”元素位于密码元素“上方”的事实来定位文本字段元素。
email_locator = locate_with(By.TAG_NAME, "input").above({By.ID: "password"})
10.2 Below (下方)
如果由于某种原因,密码文本字段元素不容易识别,而电子邮件文本字段元素容易识别,那么我们可以使用它是电子邮件元素“下方”的“输入”元素这一事实来定位文本字段元素。
password_locator = locate_with(By.TAG_NAME, "input").below({By.ID: "email"})
10.3 Left of (左边)
如果由于某种原因取消按钮不容易识别,而提交按钮元素容易识别,那么我们可以利用它是提交元素“左侧”的一个“按钮”元素来定位取消按钮元素。
cancel_locator = locate_with(By.TAG_NAME, "button").to_left_of({By.ID: "submit"})
10.4 Right of (右边)
如果提交按钮由于某种原因不容易识别,而取消按钮元素容易识别,那么我们可以使用“取消”元素右侧的“按钮”元素来定位提交按钮元素。
submit_locator = locate_with(By.TAG_NAME, "button").to_right_of({By.ID: "cancel"})
10.5 Near(附近)
如果相对定位不明显,或者它根据窗口大小而变化,则可以使用near方法来标识距离所提供的定位器最多50px的元素。使用这种方法的一个很好的例子是,一个表单元素没有一个容易构造的定位器,但它的相关输入标签元素有。
email_locator = locate_with(By.TAG_NAME, "input").near({By.ID: "lbl-email"})
10.5 Chaining relative locators (链接定位)
如果需要,您也可以链接定位器。有时,元素最容易被识别为一个元素的上方/下方和另一个元素的左右。
submit_locator = locate_with(By.TAG_NAME, "button").below({By.ID: "email"}).to_right_of({By.ID: "cancel"})
11 元素定位不同定位方式
除了常规元素匹配,还有一些特殊的元素定位方式
我们以下面的HTML代码为案例来进行讲解
<ol id="vegetables">
<li class="potatoes">…
<li class="onions">…
<li class="tomatoes"><span>Tomato is a Vegetable</span>…
</ol>
<ul id="fruits">
<li class="bananas">…
<li class="apples">…
<li class="tomatoes"><span>Tomato is a Fruit</span>…
</ul>
11.1 All matching elements (匹配所有元素/组元素)
有几个用例需要获取与定位器匹配的所有元素的引用,而不仅仅是第一个。复数find elements方法返回元素引用的集合。如果没有匹配,则返回一个空列表。在这种情况下,对所有水果和蔬菜列表项的引用将在一个集合中返回。
plants = driver.find_elements(By.TAG_NAME, "li")
通常,您获得了一个元素集合,但希望使用特定的元素,这意味着您需要遍历该集合并标识您想要的元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
# Navigate to Url
driver.get("https://www.example.com")
# Get all the elements available with tag name 'p'
elements = driver.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)
11.2 Find Elements From Element (元素内定位/元素链接定位)
它用于在父元素的上下文中查找匹配子元素的列表。为了实现这一点,父元素被链接到’ findElements ‘来访问子元素
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.example.com")
# Get element with tag name 'div'
element = driver.find_element(By.TAG_NAME, 'div')
# Get all the elements available with tag name 'p'
elements = element.find_elements(By.TAG_NAME, 'p')
for e in elements:
print(e.text)
11.3 Get Active Element (活动元素定位)
它用于跟踪(或)找到当前浏览上下文中焦点所在的DOM元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element(By.XPATH, '//input[@id="kw"]').send_keys("展昭老师")
# 获取当前活动元素的属性
attr = driver.switch_to.active_element.get_attribute("name")
print(attr)
12 关于网络元素的信息(结果检查需要用)
可以查询有关特定元素的许多详细信息
12.1 是否显示
此方法用于检查连接的元素是否正确 显示在网页上. 返回一个 Boolean 值, 如果连接的元素显示在当前的浏览器上下文中, 则为True 否则返回false.
# Navigate to the url
driver.get("https://www.google.com")
# Get boolean value for is element display
is_button_visible = driver.find_element(By.CSS_SELECTOR, "[name='login']").is_displayed()
12.2 元素是否被选定
此方法确定是否 已选择 引用的元素. 此方法广泛用于复选框, 单选按钮, 输入元素和选项元素.
返回一个布尔值, 如果在当前浏览上下文中 已选择 引用的元素, 则返回 True, 否则返回 False.
# Navigate to url
driver.get("https://the-internet.herokuapp.com/checkboxes")
# Returns true if element is checked else returns false
value = driver.find_element(By.CSS_SELECTOR, "input[type='checkbox']:first-of-type").is_selected()
12.3 获取元素标签名
此方法用于获取在当前浏览上下文中 具有焦点的被引用元素的 TagName .
# Navigate to url
driver.get("https://www.example.com")
# Returns TagName of the element
attr = driver.find_element(By.CSS_SELECTOR, "h1").tag_name
12.4 获取元素矩形
用于获取参考元素的尺寸和坐标.
提取的数据主体包含以下详细信息:
元素左上角的X轴位置
元素左上角的y轴位置
元素的高度
元素宽度
# Navigate to url
driver.get("https://www.example.com")
# Returns height, width, x and y coordinates referenced element
res = driver.find_element(By.CSS_SELECTOR, "h1").rect
12.5 获取元素CSS值
获取当前浏览上下文中元素的特定计算样式属性的值.
# Navigate to Url
driver.get('https://www.example.com')
# Retrieves the computed style property 'color' of linktext
cssValue = driver.findElement(By.LINK_TEXT, "More information...").value_of_css_property('color')
12.6 获取元素文本
获取特定元素渲染后的文本.
# Navigate to url
driver.get("https://www.example.com")
# Retrieves the text of the element
text = driver.find_element(By.CSS_SELECTOR, "h1").text
原文地址:http://www.cnblogs.com/cekailsf/p/16800385.html