
RabbitMQ 可以通过 3 种方式实现分布式部署:集群、Federation 和 Shovel。这 3 种方式不是互斥的,可以根据需要选择其中的一种或者以几种方式的组合来达到分布式部署的目的。Federation 和 Shovel 可以为 RabbitMQ 的分布式部署提供更高的灵活性,但同时也提高了部署的复杂性。
一、Federation
Federation 插件的设计目标是使 RabbitMQ 在不同的 Broker 节点之间进行消息传递而无须建立集群,该功能在很多场景下都非常有用。
Federation 插件能够在不同管理域(可能设置了不同的用户和 vhost,也可能运行在不同版本的 RabbitMQ 和 Erlang 上)中的 Broker 或者集群之间传递消息。
Federation 插件基于 AMQP 0-9-1 协议在不同的 Broker 之间进行通信,并设计成能够容忍不稳定的网络连接情况。
一个 Broker 节点中可以同时存在联邦交换器(或队列)或者本地交换器(或队列),只需要对特定的交换器(或队列)创建 Federation 连接(Federation link)。
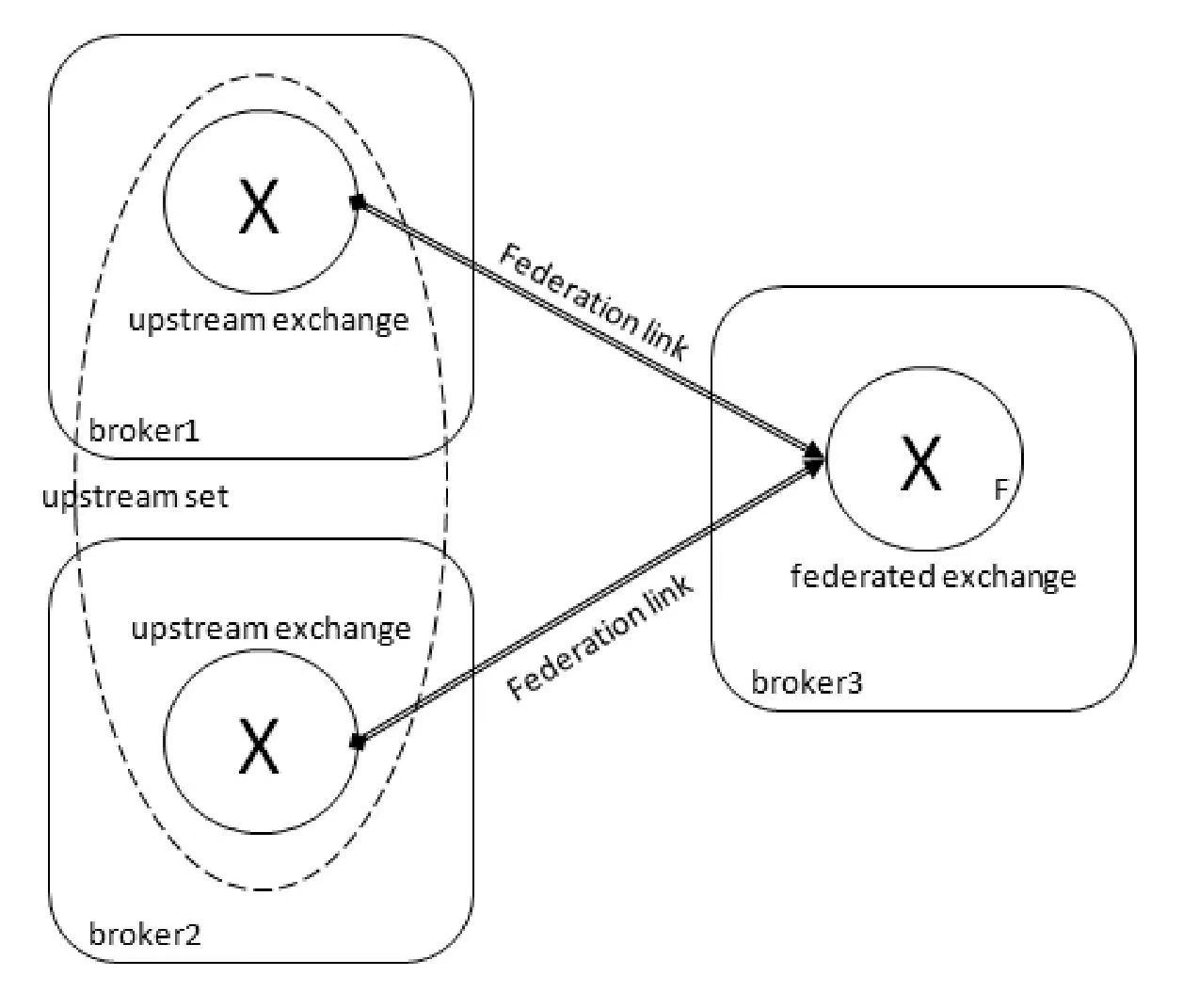
一个联邦交换器(federated exchange)或者一个联邦队列(federated queue)接收上游(upstream)的消息,这里的上游是指位于其他 Broker 上的交换器或者队列。联邦交换器能够将原本发送给上游交换器(upstream exchange)的消息路由到本地的某个队列中;联邦队列则允许一个本地消费者接收到来自上游队列(upstream queue)的消息。
1. 联邦交换器
问题描述:
broker1 部署在北京,broker2 部署在上海,而 broker3 部署在广州
北京(broker1) ClientB 需要发送消息到广州(broker3)exchangeA(broker3 中的队列 queueA 通过“rkA”与 exchangeA 进行了绑定)
解决方案:
在 broker3 中为交换器 exchangeA 与北京的 broker1 之间建立一条单向的 Federation link。(在消息接收方建立连接)
实现原理:
此时 Federation 插件会在 broker1 上建立一个同名的交换器 exchangeA(这个名称可以配置,默认同名),同时建立一个内部的交换器“exchangeA→broker3 B”,并通过路由键“rkA”将这两个交换器绑定起来。
与此同时 Federation 插件还会在 broker1 上建立一个队列“federation:exchangeA→broker3 B”,并与交换器“exchangeA→broker3 B”进行绑定。Federation 插件会在队列“federation:exchangeA→broker3 B”与 broker3 中的交换器 exchangeA 之间建立一条 AMQP 连接来实时地消费队列“federation:exchangeA→broker3 B”中的数据。这些操作都是内部的,对外部业务客户端来说这条 Federation link 建立在 broker1 的 exchangeA 和 broker3 的 exchangeA 之间。
如图:
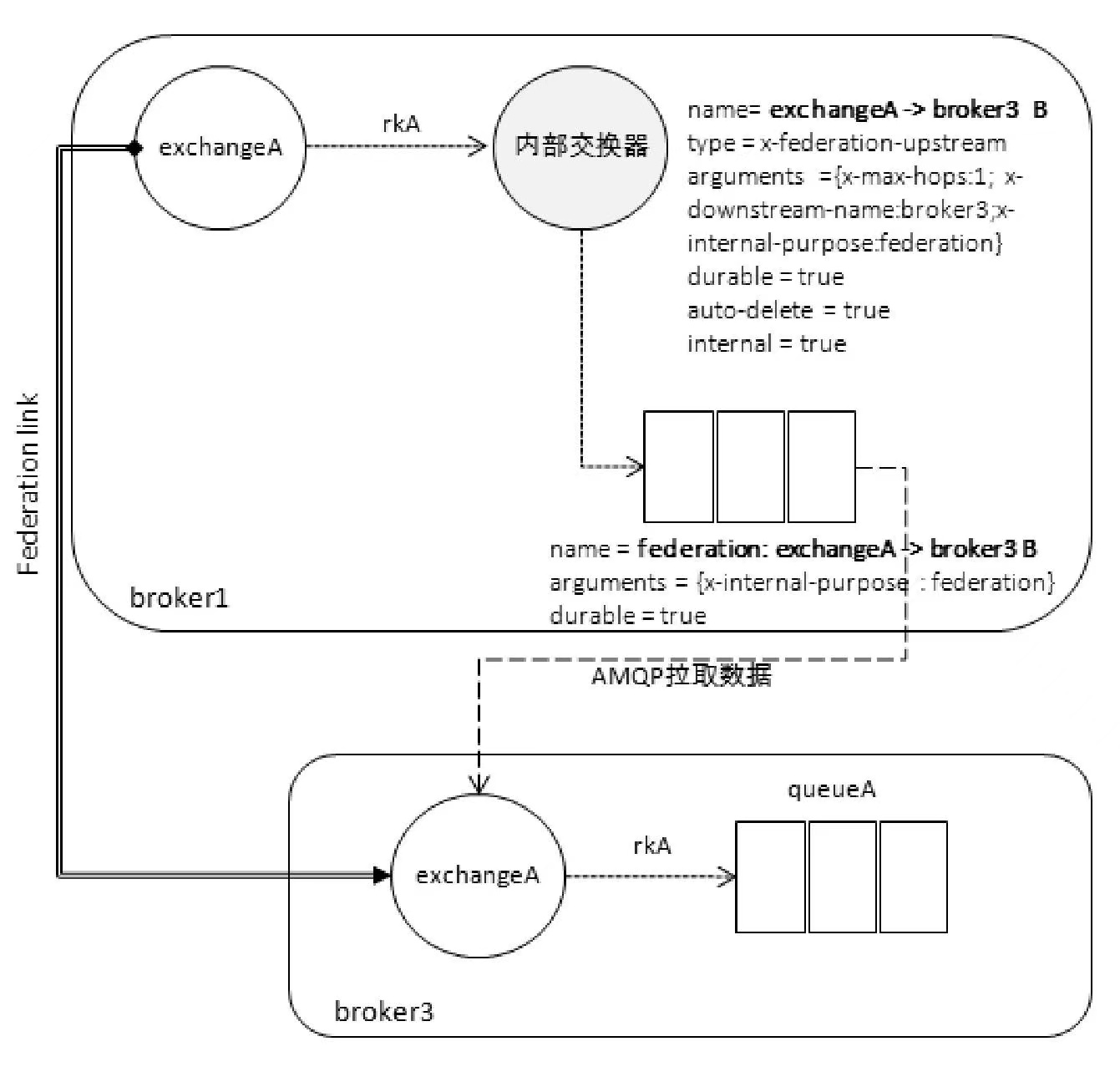
broker1 的队列“federation:exchangeA→broker3 B”是一个相对普通的队列,可以直接通过客户端进行消费。
达成效果:
部署在北京的业务 ClientB 可以连接 broker1 并向 exchangeA 发送消息,这样 ClientB 可以迅速发送完消息并收到确认信息,而之后消息会通过 Federation link 转发到 broker3 的交换器 exchangeA 中。最终消息会存入与 exchangeA 绑定的队列 queueA 中,消费者最终可以消费队列 queueA 中的消息。经过 Federation link 转发的消息会带有特殊的 headers 属性标记。
Federation 使得生产者和消费者可以异地部署而又让这两方感受不到过多的差异。
对于“异地均摊消费”这种特殊需求,队列“federation:exchangeA→broker3 B”这种天生特性提供了支持。对于 broker1 的交换器 exchangeA 而言,它是一个普通的交换器,可以创建一个新的队列绑定它,对它的用法没有什么特殊之处。
一个 federated exchange 同样可以成为另一个交换器的 upstream exchange。甚至两方的交换器可以互为 federated exchange 和 upstream exchange。
对于默认的交换器(每个 vhost 下都会默认创建一个名为“”的交换器)和内部交换器而言,不能对其使用 Federation 的功能。
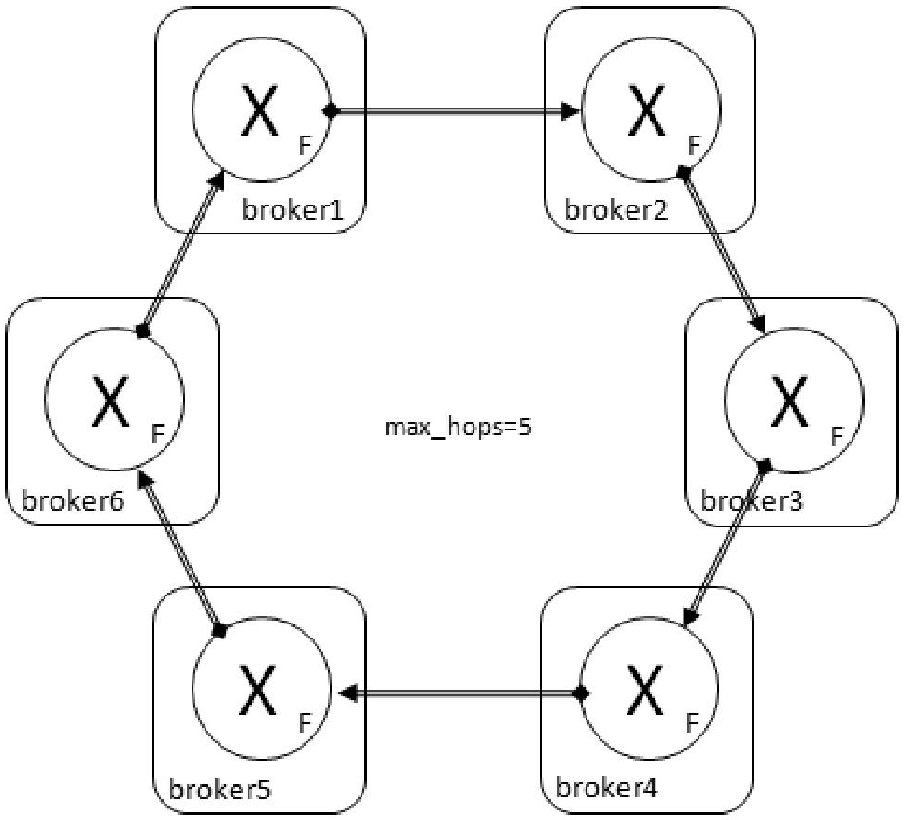
对于联邦交换器而言,还有更复杂的拓扑逻辑部署方式。例如:





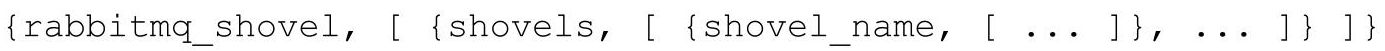


2. 联邦队列
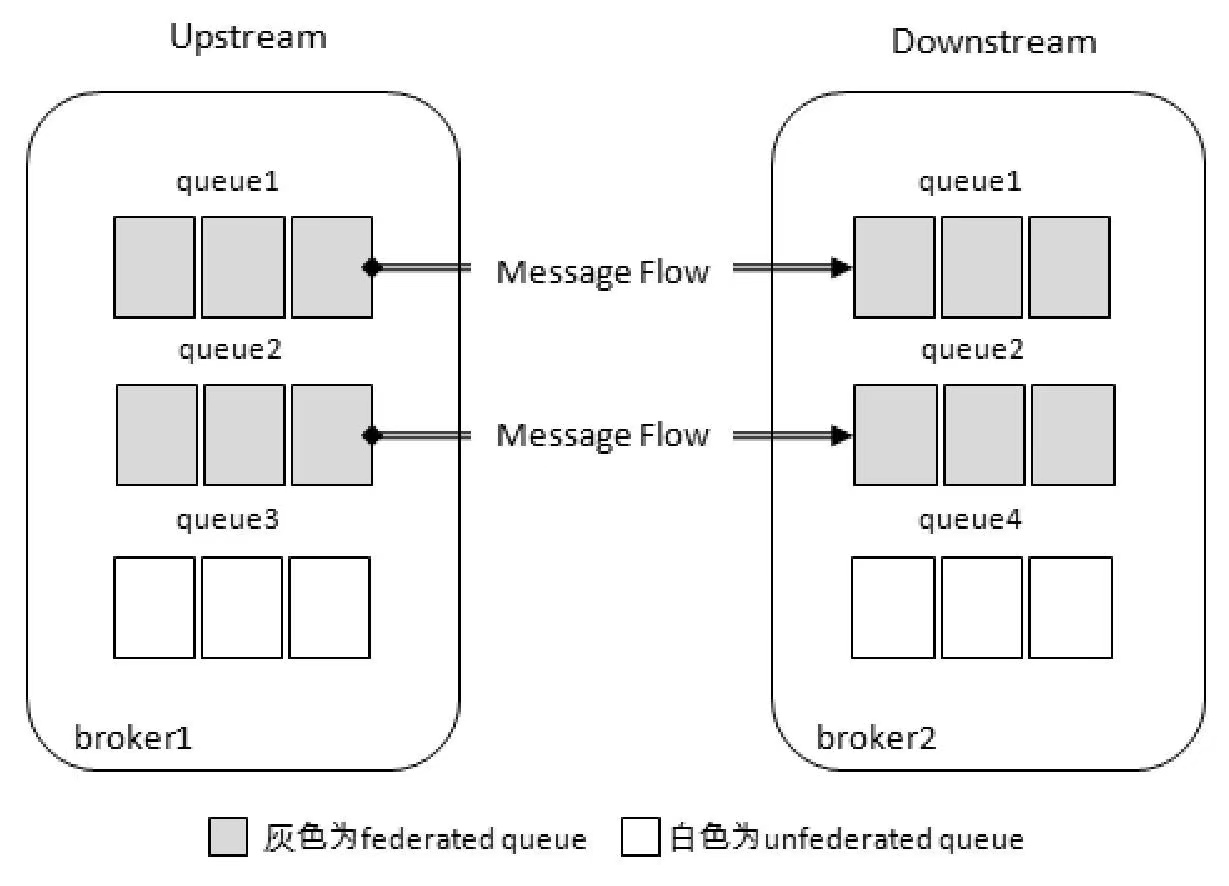
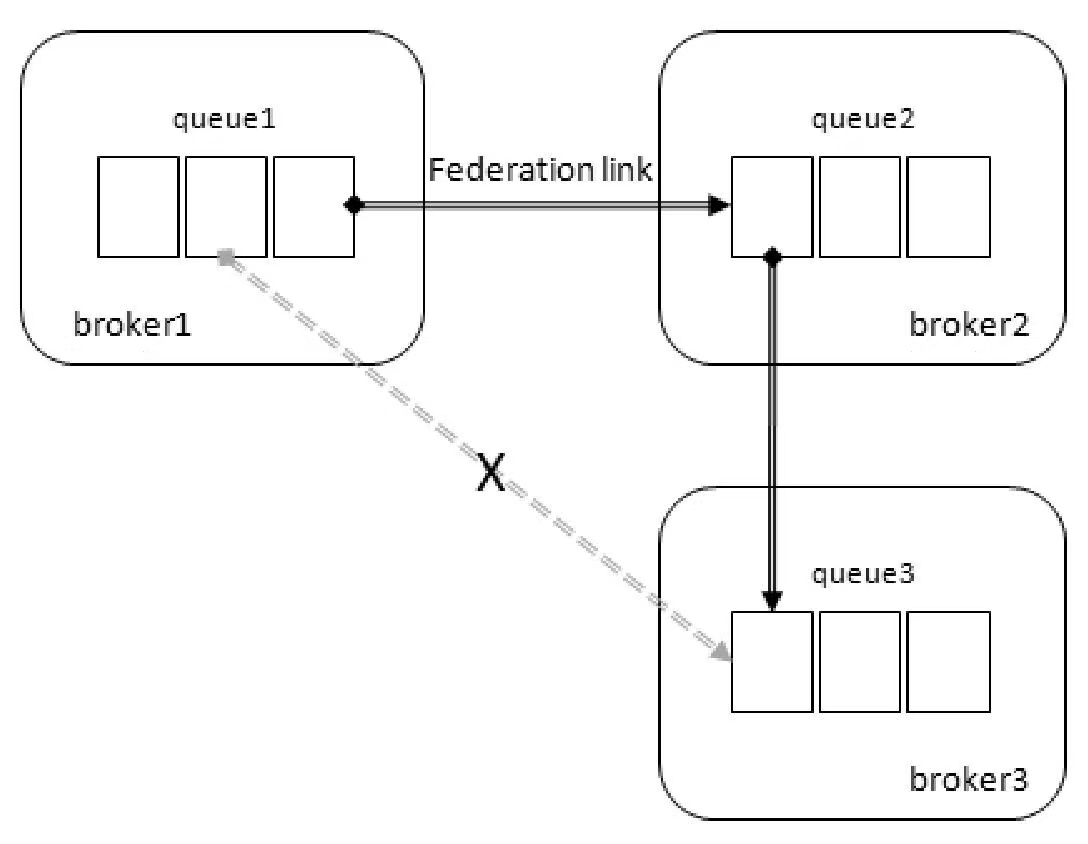
除了联邦交换器,RabbitMQ 还可以支持联邦队列(federated queue)。联邦队列可以在多个 Broker 节点(或者集群)之间为单个队列提供均衡负载的功能。一个联邦队列可以连接一个或者多个上游队列(upstream queue),并从这些上游队列中获取消息以满足本地消费者消费消息的需求。
当有消费者 ClinetA 连接 broker2 并通过 Basic.Consume 消费队列 queue1(或queue2)中的消息时,如果队列 queue1(或queue2)中本身有若干消息堆积,那么 ClientA 直接消费这些消息,此时 broker2 中的 queue1(或queue2)并不会拉取 broker1 中的 queue1(或queue2)的消息;如果队列 queue1(或queue2)中没有消息堆积或者消息被消费完了,那么它会通过 Federation link 拉取在 broker1 中的上游队列 queue1(或queue2)中的消息(如果有消息),然后存储到本地,之后再被消费者 ClientA 进行消费。(本地队列消息消费完才会拉取上游队列的消息)
消费者既可以消费 broker2 中的队列,又可以消费 broker1 中的队列,Federation 的这种分布式队列的部署可以提升单个队列的容量。
如果在 broker1 一端部署的消费者来不及消费队列 queue1 中的消息,那么 broker2 一端部署的消费者可以为其分担消费,也可以达到某种意义上的负载均衡。
和 federated exchange 不同,一条消息可以在联邦队列间转发无限次。两个队列 queue 互为联邦队列:队列中的消息除了被消费,还会转向有多余消费能力的一方,如果这种“多余的消费能力”在 broker1 和 broker2 中来回切换,那么消费也会在 broker1 和 broker2 中的队列中来回转发。
broker2 的队列 queue2 没有消息堆积或者消息被消费完之后并不能通过 Basic.Get 来获取 broker1 中队列 queue1 的消息。因为 Basic.Get 是一个异步的方法,如果要从 broker1 中队列 queue1 拉取消息,必须要阻塞等待通过 Federation link 拉取消息存入 broker2 中的队列 queue2 之后再消费消息,所以对于 federated queue 而言只能使用 Basic.Consume 进行消费。
federated queue并不具备传递性。如上图,队列 queue2 作为 federated queue 与队列 queue1 进行联邦,而队列 queue2 又作为队列 queue3 的 upstream queue,但是这样队列 queue1 与 queue3 之间并没有产生任何联邦的关系。如果队列 queue1 中有消息堆积,消费者连接 broker3 消 费 queue3 中的消息,无论 queue3 处于何种状态,这些消费者都消费不到 queue1 中的消息,除非 queue2 有消费者。
理论上可以将一个 federated queue 与一个 federated exchange 绑定起来,不过这样会导致一些不可预测的结果,如果对结果评估不足,建议慎用这种搭配方式。
3. Federation 的使用
以本文第一个例子为例,步骤如下:
第一步
在 broker1 和 broker3 中开启 rabbitmq_federation 插件,最好同时开启 rabbitmq_federation_management 插件。
(1)开启 Federation 功能
rabbitmq-plugins enable rabbitmq_federation
Federation 内部基于AMQP协议拉取数据,所以在开启 rabbitmq_federation 插件的时候,默认会开启 amqp_client 插件。
(2)开启 Federation 的管理插件
rabbitmq-plugins enable rabbitmq_federation_management
开启 rabbitmq_federation_management 插件之后,在 RabbitMQ 的管理界面中“Admin”的右侧会多出“Federation Status”和“Federation Upstreams”两个 Tab 页。
rabbitmq_federation_management 插件依附于 rabbitmq_management 插件,所以开启 rabbitmq_federation_management 插件的同时默认也会开启 rabbitmq_management 插件。
当需要在集群中使用 Federation 功能的时候,集群中所有的节点都应该开启 Federation 插件。
第二步
在 broker3 中定义一个 upstream:
也可以通过调用 HTTP API 接口或 Web 管理页面定义。
upstream 定义有不少参数,其中几个举例如下:
(1)Prefetch count(prefetch_count):定义 Federation 内部缓存的消息条数,即在收到上游消息之后且在发送到下游之前缓存的消息条数。
(2)Reconnect delay(reconnect-delay):Federation link 由于某种原因断开之后,需要等待多少秒开始重新建立连接。
(3)Acknowledgement Mode(ack-mode):定义 Federation link 的消息确认方式。共有3种:
<1>on-confirm:表示在接收到下游的确认消息(需要等待下游的 Basic.Ack)之后再向上游发送消息确认,这个选项可以确保网络失败或者 Broker 宕机时不会丢失消息,但也是处理速度最慢的选项。
<2>on-publish:表示消息发送到下游后(不需要等待下游的 Basic.Ack)再向上游发送消息确认,这个选项可以确保在网络失败的情况下不会丢失消息,但不能确保 Broker 宕机时不会丢失消息。
<3>no-ack:表示无须进行消息确认,这个选项处理速度最快,但也最容易丢失消息。
另外还可以设置消息过期时间等。
第三步
定义一个 Policy 用于匹配交换器 exchangeA,并使用第二步中所创建的 upstream。
也可以通过调用 HTTP API 接口或 Web 管理页面定义。
这样就创建了一个 Federation link。
查看 Federation link 状态:
rabbitmqctl eval ′rabbit_federation_status:status().′
创建 federated queue 的 Federation link:
实践
(1)在 Broker 节点 rabbit@wjt-node-1 192.168.10.4 和 rabbit@wjt-node-3 192.168.10.6 开启 federation 功能:
(2)在 Broker 节点 rabbit@wjt-node-3 192.168.10.6 创建交换器 exchangeA 和队列 queueA,使用路由键 eA2qA 进行绑定。
(3)在 Broker 节点 rabbit@wjt-node-3 192.168.10.6 定义一个 upstream:
rabbitmqctl set_parameter federation-upstream fu1 '{"uri":"amqp://root:shiajun666@192.168.10.4:5672","ack-mode":"on-confirm"}'
![]()
(4)在 Broker 节点 rabbit@wjt-node-3 192.168.10.6 定义一个 Policy 用于匹配交换器 exchangeA,并使用第三步中所创建的 upstream:
rabbitmqctl set_policy --apply-to exchanges policy1 "exchangeA" '{"federation-upstream":"fu1"}'
![]()
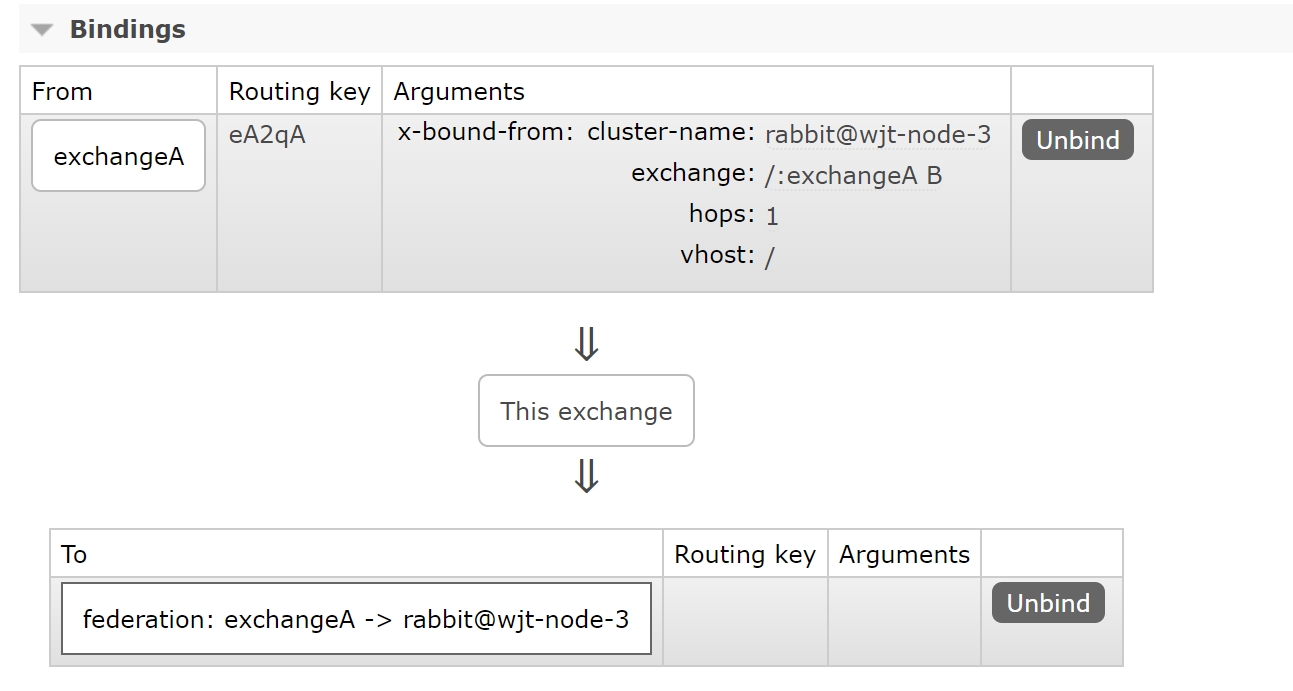
执行成功可以看到 Broker 节点 rabbit@wjt-node-1 192.168.10.4 上创建了同名交换器 exchangeA,以及两个同名的交换器和队列 federation: exchangeA -> rabbit@wjt-node-3 B,三者绑定关系如下:
中间的 exchange 为交换器 federation: exchangeA -> rabbit@wjt-node-3 B。
(5)验证:生产者往节点 rabbit@wjt-node-1 192.168.10.4 交换器 exchangeA 发送消息,消费者在节点 rabbit@wjt-node-3 192.168.10.6 队列 queueA 能成功收到消息。
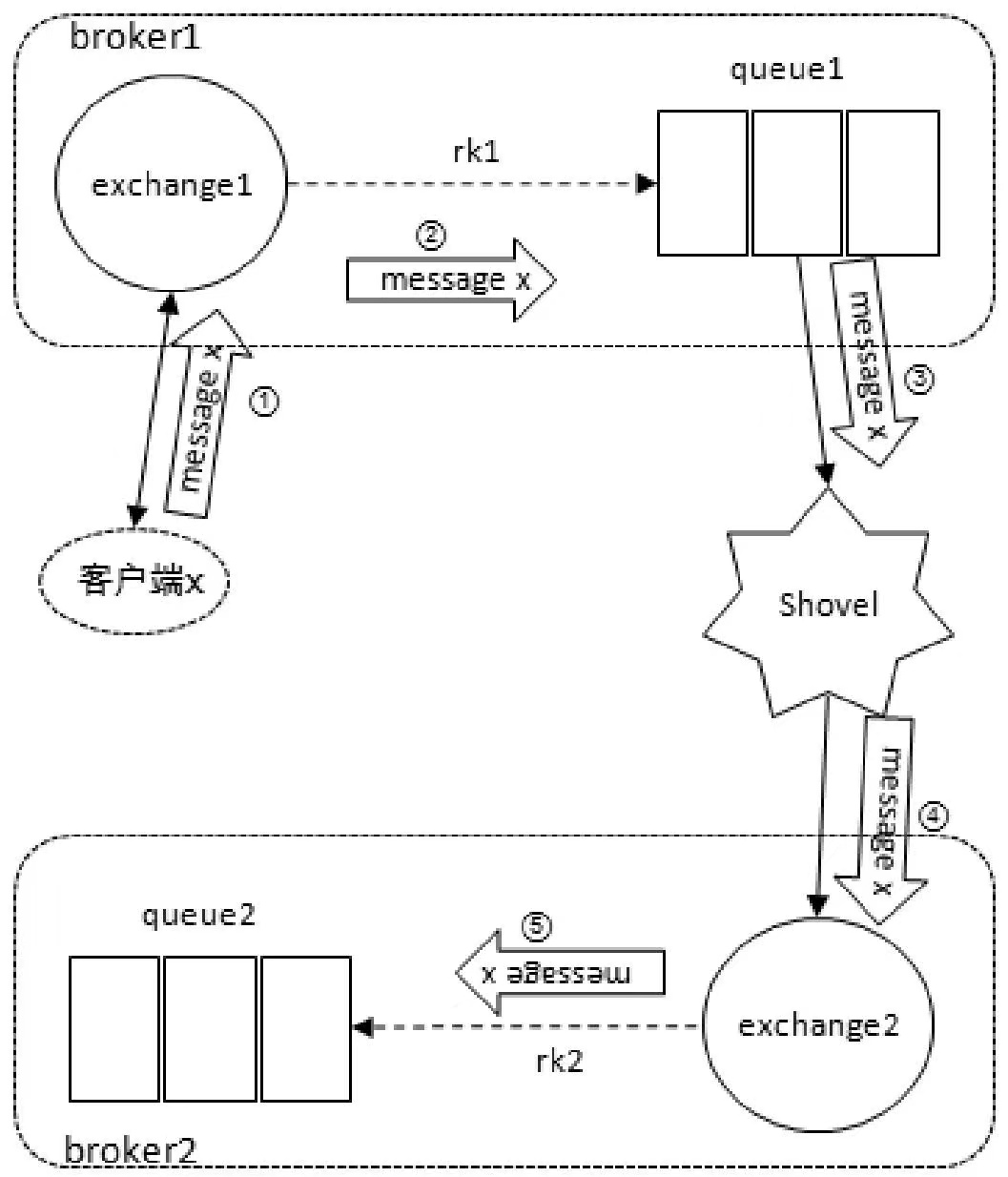
二、Shovel
与 Federation 具备的数据转发功能类似,Shovel 能够可靠、持续地从一个 Broker 中的队列拉取数据并转发至另一个 Broker 中的交换器。作为源端的队列和作为目的端的交换器可以同时位于同一个 Broker 上,也可以位于不同的 Broker 上。
Shovel 的主要优势:
(1)松耦合。Shovel 可以移动位于不同管理域中的 Broker(或者集群)上的消息,这些 Broker(或者集群)可以包含不同的用户和 vhost,也可以使用不同的 RabbitMQ 和 Erlang 版本。
(2)支持广域网。Shovel 插件同样基于 AMQP 协议在 Broker 之间进行通信,被设计成可以容忍时断时续的连通情形,并且能够保证消息的可靠性。
(3)高度定制。当 Shovel 成功连接后,可以对其进行配置以执行相关的 AMQP 命令。
1. Shovel 的原理
如上图,在 broker1 队列 queue1 和 broker2 交换器 exchange2 之间配置一个 Shovel link,客户端将消息发送到 broker1 exchange1,经流转后最终将存储到 broker2 queue2 中。
如果在配置 Shovel link 时设置了 add_forward_headers 参数为 true,则在消费到队列 queue2 中这条消息的时候会有特殊的 headers 属性标记(x-shovelled)。
通常情况下,使用 Shovel 时配置队列作为源端,交换器作为目的端。同样可以将队列配置为目的端,如上图所示。虽然看起来队列 queue1 是通过 Shovel link 直接将消息转发至 queue2 的,其实中间也是经由 broker2 的交换器转发,只不过这个交换器是默认的交换器而已。
配置交换器为源端也是可行的,如上图所示。虽然看起来交换器 exchange1 是通过 Shovel link 直接将消息转发至 exchange2 上的,实际上在 broker1 中会新建一个队列(名称由 RabbitMQ 自定义)并绑定 exchange1,消息从交换器 exchange1 过来先存储在这个队列中,然后 Shovel 再从这个队列中拉取消息进而转发至交换器 exchange2。
后面这两种使用方法本质上也是队列为源,交换器为目的。
源端与目的端的交换器和队列并不一定需要在 Shovel link 建立之前创建。Shovel 可以为源端或者目的端配置多个 Broker 的地址,这样可以使得源端或者目的端的 Broker 失效后能够尝试重连到其他 Broker之上(随机挑选)。可以设置 reconnect_delay 参数以避免由于重连行为导致的网络泛洪,或者可以在重连失败后直接停止连接。针对源端和目的端的所有配置声明会在重连成功之后被重新发送。
2. Shovel 的使用
第一步
(1)开启 Shovel 功能
rabbitmq-plugins enable rabbitmq_shovel
默认也会开启 amqp_client 插件。
(2)开启 Shovel 管理插件
rabbitmq-plugins enable rabbitmq_shovel_management
默认也会开启 rabbitmq_management 插件。
第二步
Shovel 既可以部署在源端,也可以部署在目的端。有两种方式可以部署 Shovel:静态方式(static)和动态方式(dynamic)。静态方式是指在 rabbitmq.config 配置文件中设置,而动态方式是指通过 Runtime Parameter 设置。
(1)静态方式
在 rabbitmq.config 配置文件中针对 Shovel 插件的配置信息是一种 Erlang 项式,由单条 Shovel 条目构成(shovels 部分的下一层):
每一条 Shovel 条目定义了源端与目的端的转发关系,其名称(shovel_name)必须是独一无二的。每一条 Shovel 的定义都像下面这样:
(2)动态方式
与 Federation upstream 类似,Shovel 动态部署方式的配置信息会被保存到 RabbitMQ 的 Mnesia 数据库中,包括权限信息、用户信息和队列信息等内容。
也可以使用 HTTP API 接口或 Web 管理页面进行部署。
实践
(1)在 Broker 节点 rabbit@wjt-node-1 192.168.10.4 和 rabbit@wjt-node-3 192.168.10.6 开启 shovel 功能:
(2)在 Broker 节点 rabbit@wjt-node-1 192.168.10.4 创建交换器 exchange1 和队列 queue1,使用路由键 rk1 进行绑定;在 Broker 节点 rabbit@wjt-node-3 192.168.10.6 创建交换器 exchange2 和队列 queue2,使用路由键 rk2 进行绑定。
(3)在 Broker 节点 rabbit@wjt-node-3 192.168.10.6 部署 Shovel:在 节点 rabbit@wjt-node-1 192.168.10.4 队列 queue1 和 节点 rabbit@wjt-node-3 192.168.10.6 交换器 exchange2 之间配置一个 Shovel link。
rabbitmqctl set_parameter shovel test_shovel '{"src-uri":"amqp://root:shiajun666@192.168.10.4:5672","src-queue":"queue1","dest-uri":"amqp://root:shiajun666@192.168.10.6:5672","src-exchange-key":"rk2","prefetch-count":64,"reconnect-delay":5,"publish-properties":[],"add-forward-headers":true,"ack-mode":"on-confirm"}'

(4)验证:生产者往节点 rabbit@wjt-node-1 192.168.10.4 交换器 exchange1 发送消息,消费者在节点 rabbit@wjt-node-1 192.168.10.4 队列 queue2 能成功收到消息。
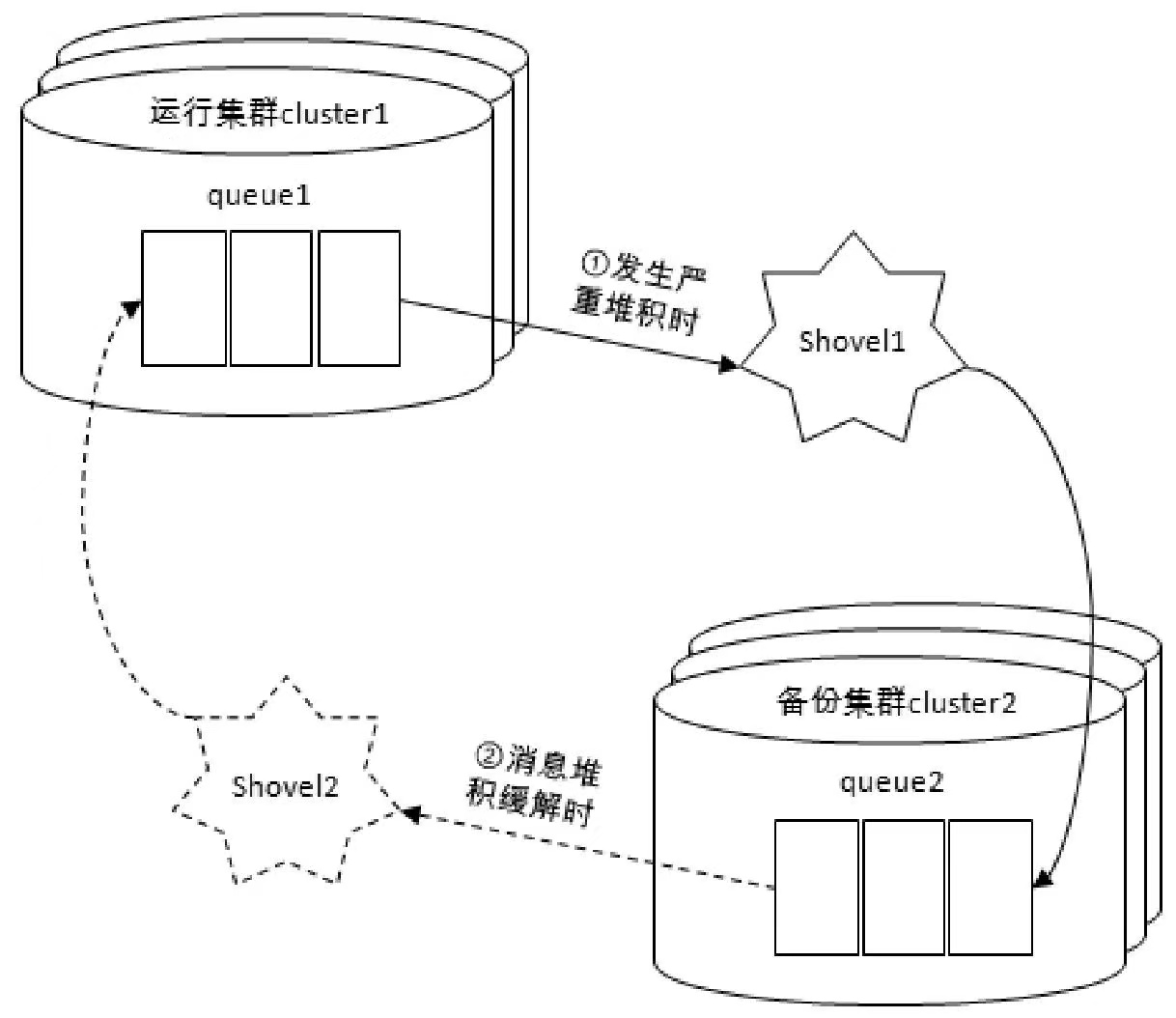
3. Shovel 应用案例:消息堆积的治理
(1)当检测到当前运行集群 cluster1 中的队列 queue1 中有严重消息堆积,就启用 shovel1 将队列 queue1 中的消息转发至备份集群 cluster2 中的队列 queue2。
(2)当检测到队列 queue1 中的消息个数低于 1 百万或者消息占用大小低于 1 GB时就停止 shovel1,然后让原本队列 queue1 中的消费者慢慢处理剩余的堆积。
(3)当检测到队列 queue1 中的消息个数低于 10 万或者消息占用大小低于 100MB 时,就开启 shovel2 将队列 queue2 中暂存的消息返还给队列 queue1。
(4)当检测到队列 queue1 中的消息个数超过 1 百万或者消息占用大小高于 1GB 时就将 shovel2 停掉。
对于一台普通的服务器来说,在一个队列中堆积 1 万至 10 万条消息,丝毫不会影响什么。但是如果这个队列中堆积超过 1 千万乃至一亿条消息时,可能会引起一些严重的问题,比如引起内存或者磁盘告警而造成所有 Connection 阻塞。
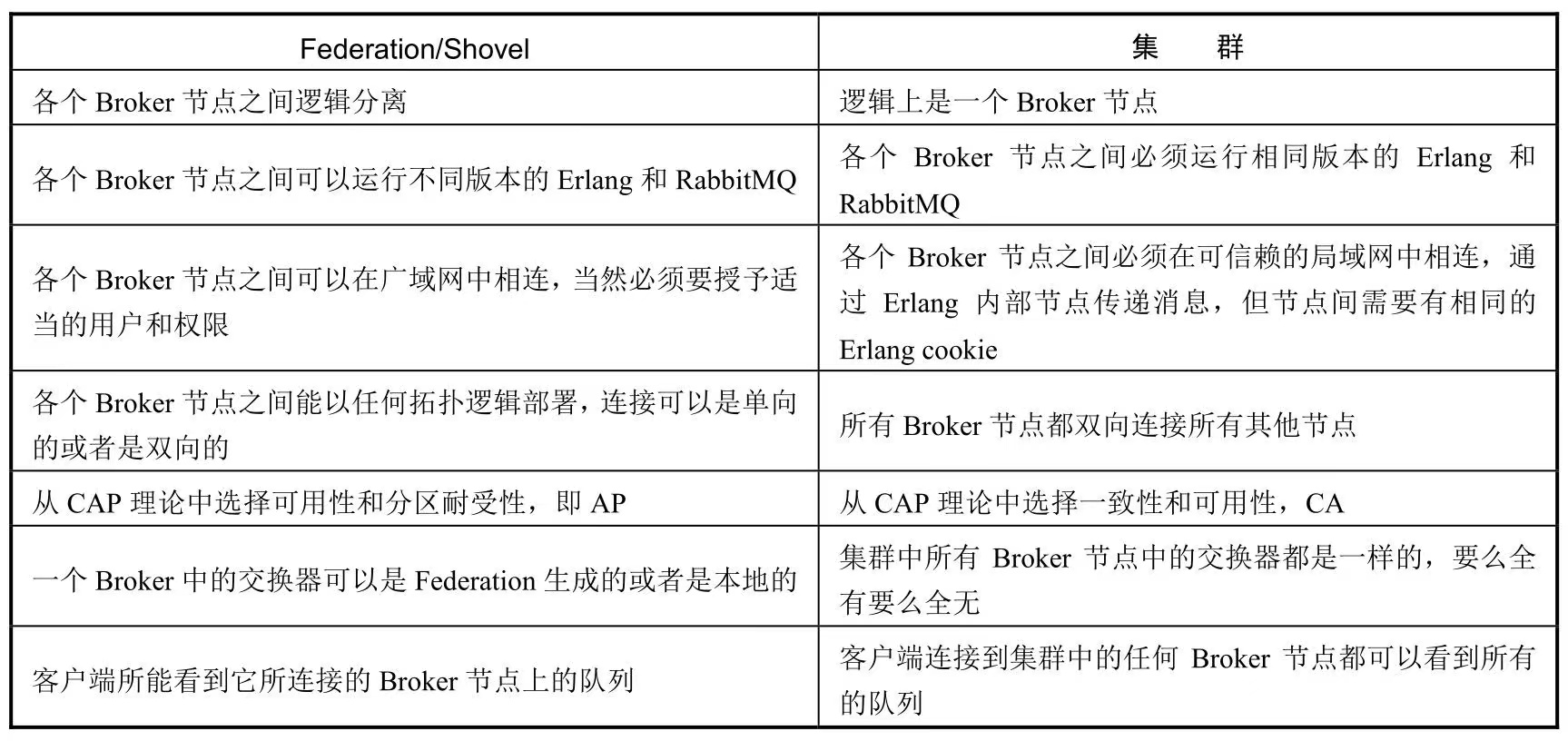
Federation/Shovel 与 集群的区别与联系:
通过 Shovel 来连接各个 RabbitMQ Broker,概念上与 Federation 的情形类似,不过 Shovel 工作在更低一层。鉴于 Federation 从一个交换器中转发消息到另一个交换器,Shovel 只是简单地从某个 Broker 上的队列中消费消息,然后转发消息到另一个 Broker 上的交换器而已。Shovel 也可以在单独的一台服务器上去转发消息,比如将一个队列中的数据移动到另一个队列中。如果想获得比 Federation 更多的控制,可以在广域网中使用 Shovel 连接各个 RabbitMQ Broker 来生产或消费消息。
原文地址:http://www.cnblogs.com/wujuntian/p/16784506.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性