
为什么要扩容?
无论如何优化性能,能达到的最大值是有限的。对于一个用户量大的应用,可以对服务器进行各种优化,诸如限流、资源隔离,但是上限还是在那里,这时候就应该改变我们的硬件,例如使用更强的CPU、更大的内存。
扩容策略
扩容策略可以分为两种, 一种是对单机整体扩容,也就是机器内部包含CPU、内存、存储设备等,另一种是扩容对应的组件,例如扩内存、扩磁盘、扩CPU。
整机硬件
整机扩容的好处是,有很多专业的服务器硬件供应商,例如IBM、浪潮、DELL、HP等,专业的硬件供应商,他们组装以及搭配方面可能经验更加丰富,另外有些公司会对组件进行一些优化,从而服务器更加稳定,可以类比为买电脑,有的人可能选择买淘宝卖家已经组装好的台式,有的人可能自己买各种硬件自己回家组装,对于一般人而言,选择前者是较为靠谱的选择,因为你即使懂硬件的一些参数,也难保自己搭配的机器是否能发挥各个部件最大性能。
组件
对于一些技术能力强悍的公司,更多的是自己买各种组件组装,这样成本更低,因为节省了组装等费用,并且可以根据业务个性化定制,例如有的公司是计算密集型的,那么主要是更换更强的CPU,有的IO密集型,那么扩容的应该是内存等,有的公司需要存储大量的数据,那么可能扩容的是硬盘等存储设备。
组件包含:
-
cpu:Intel、Amd ,参考频率、线程数等
-
网卡:百兆->千兆 -> 万兆
-
内存:ECC校验
-
磁盘:SCSI HDD(机械)、HHD(混合)、SATA SSD、PCI-e SSD、 MVMe SSD
AKF拆分原则
对于一个应用,如果单机不足以支撑服务请求,那么可以建立诸如主主、主从等模式的集群:
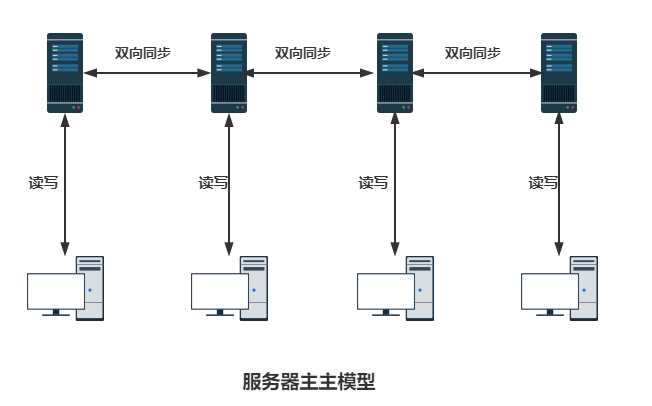
这个叫AKF原则X轴扩展,目的是将请求分流在多台机器上,但是多台机器中间要解决数据同步性的问题,越多的机器数据不同步的可能性越大,这也就意味着没法无限整体复制扩容。所以可以整理搜集服务器内热点的业务请求,将业务分离出来,只对热点业务进行扩容,这就是AKF原则的Y轴拆分:
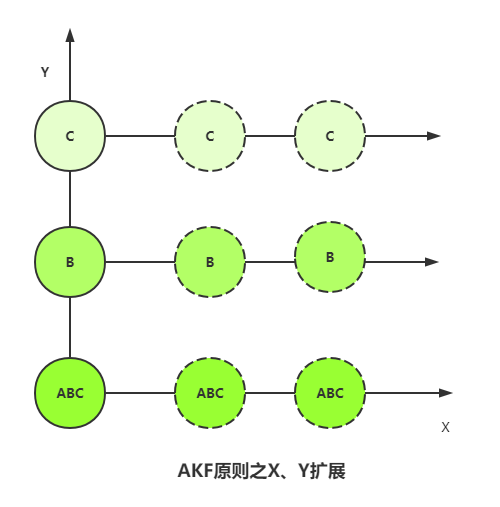
对业务拆分之后,某个业务还可能太热点,也就是Y轴拆分后水平复制还是不足以支撑数据请求,那么可以将业务的数据进行拆分, 具体来说就是,某个业务的数据,可以放在多个地方,例如在湖北、北京、上海部署机房,各地的人们需要请求数据时,由离得近的服务器提供服务。
拆分扩容后存在的问题
随着业务的增长,系统变得越来越庞大, 根据系统功能拆分成独立而又互通的项目, 比如交易系统、财务系统、生产流程系统、物流系统、网站系统等等,但是分布式结构会存在很多问题。
1、数据共享问题
所有的服务之间数据如何共享同步,这是一个需要考虑的问题,微服务架构中,数据不可能只有一份,没法避免机器损坏等原因造成的数据丢失,多份数据之间如何同步?目前可供参考的解决思路是建立数据中心、搭建数据库集群。
2、接口调用问题
不同的服务器之间进行调用遵循远程调用协议RPC
JAVA RMI:Java远程方法调用,即Java RMI(Java Remote Method Invocation)是Java编程语言里,一种用于实现远程过程调用的应用程序编程接口。 它使客户机上运行的程序可以调用远程服务器上的对象。
dubbo:提供了面向接口代理的高性能RPC调用
3、持久化数据雪崩问题
- 数据库分库分表
- 资源隔离
- 缓存设定数据持久化策略
4、高并发问题
缓存:诸如缓存击穿、穿透、雪崩等
数据闭环:为了便于理解,举个例子,对于淘宝而言,有网页版、IOS版、安卓版、还有什么一淘等等,虽然客户端不一样,但是展示的商品信息是相同的,也就是一件商品,无论是哪个端用的数据是一样的,需要一套方案来解决并发下根据相同数据在不同端进行不同展示的问题,这就叫数据闭环。
5、数据一致性问题
这是一个难点,大意就是多个服务器之间数据如何保证一致性,同样的商品在不同客户端服务端端价格应该是一样的, 通常使用分布式锁。
数据库扩容:集群
先简单说一下分布式与集群的区别,这两个词儿经常一起出现,但是意义却有所不同,分布式会缩短单个任务的执行时间来提升工作效率,而集群强调的是提高单位时间内执行操作数的增加来提高效率。更简单的来说,分布式是将步骤分到每台电脑上,不考虑依赖关系,集群方案是指几个任务同时在处理。
单一数据库存储难以满足业务需求时,采取集群的方式,将数据存储在不同的服务器,这可以是主主或者主从,主从中主负责写,从负责读,将与数据库有关的压力进行分解到多台机器上。
分布式ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。很容易想到的是利用自增,但是自增有很多问题,例如ID有太强的规律,可能会被恶意查询搜集,面对数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,这样数据库的自增ID显然不能满足需求;特别一点的如商品、订单、用户也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。概括下来,那业务系统对ID号的要求有哪些呢?
分布式ID要求
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
上述123对应三类不同的场景,但是3和4的需求是互斥的,也就是无法使用同一个方案满足。除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,整个与数据有关的动作都无法执行,会带来一场灾难。
由此总结下一个ID生成系统最少应该做到如下几点:
- 平均延迟和TP999延迟都要尽可能低;
- 可用性5个9(这是美团的要求,有些企业例如阿里要求6个9);
- 高QPS。
分布式ID生成策略
目前业界常用的ID生成策略有很多,例如UUID、雪花生成算法、Redis、Zookeeper等。点击查看更多
弹性扩容
就是让集群根据计划在某一段时间自动对资源进行扩容,并在设置的计划还原时间时释放资源。这样能解决规律性的资源峰谷需求,达到充分合理利用资源的目的。
但是弹性扩容也有一些问题:
第一,虚拟机弹性能力较弱。使用虚拟机部署业务,在弹性扩容时,需要经过申请虚拟机、创建和部署虚拟机、配置业务环境、启动业务实例这几个步骤。前面的几个步骤属于私有云平台,后面的步骤属于业务工程师。一次扩容需要多部门配合完成,扩容时间以小时计,过程难以实现自动化。如果可以实现自动化“一键快速扩容”,将极大地提高业务弹性效率,释放更多的人力,同时也消除了人工操作导致事故的隐患。
第二,IT成本高。由于虚拟机弹性能力较弱,业务部门为了应对流量高峰和突发流量,普遍采用预留大量机器和服务实例的做法。即先部署好大量的虚拟机或物理机,按照业务高峰时所需资源做预留,一般是非高峰时段资源需求的两倍。资源预留的办法带来非常高的IT成本,在非高峰时段,这些机器资源处于空闲状态,也是巨大的浪费。
原文地址:http://www.cnblogs.com/zhaojinhui/p/16801970.html