
704.二分查找
1. 题目
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
2. 分析
关键词:有序、升序、整型数组、不重复—>得出结论:使用二分查找法
因为使用二分查找法的前提就是有序无重复的数组。如果一旦有重复元素,二分查找法的返回就不唯一了。
**重点: ** 注意把握二分法的区间定义。
二分法区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。
写法1:[left, right]
定义 target 是在一个左闭右闭的区间里即[left, right]
🔸左闭右闭,left == right是有意义的,所以while (left <= right) 要使用 <=
🔸if (nums[middle] > target) right 要赋值为 middle – 1,因为当前这个nums[middle]一定不是target,那么接下来要查找的左区间结束下标位置就是 middle – 1
例如在数组:1,2,3,4,7,9,10中查找元素2,如图所示:
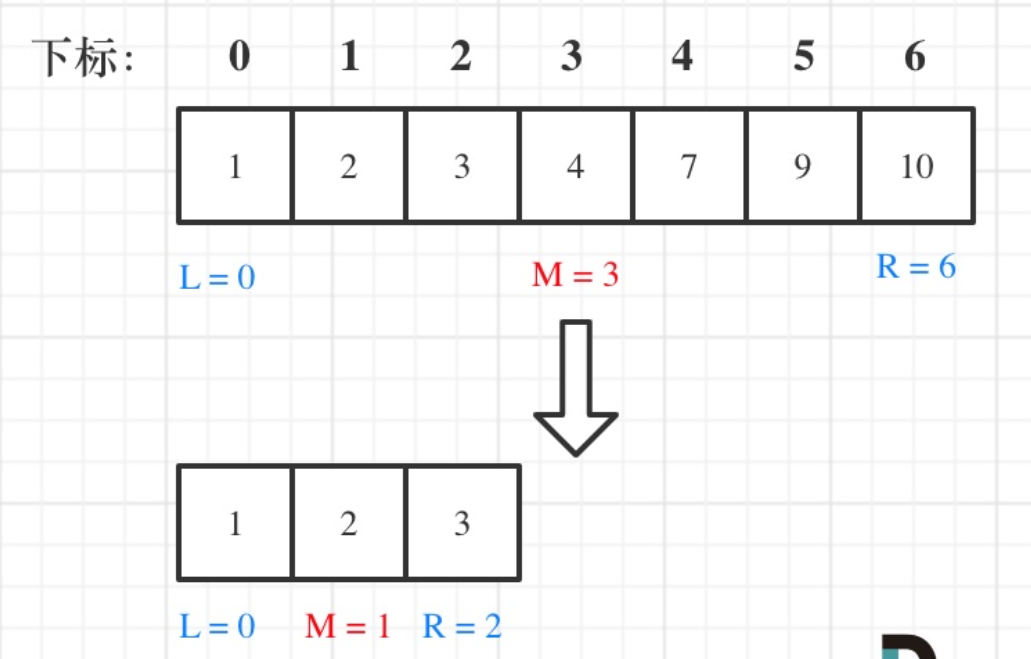
程序
int search(int* nums, int numsSize, int target)//数组,数组大小,要找的目标值target.最终返回target的下标
{
int left=0;//左下标
int right=numsSize-1;//右下标,定义target在左闭右闭的区间里,即:[left, right],所以numsSize-1
int mid=0;//中点下标
while(left<=right)//当left==right,区间[left, right]依然有效,所以用 <=
{
mid=(left+right)/2;
if(nums[mid]==target)
{
return mid;// 数组中找到目标值,直接返回下标
}
else if(nums[mid]>target)
{
right=mid-1; // target 在左区间,所以[left, middle - 1]
}
else
{
left=mid+1;// target 在右区间,所以[middle + 1, right]
}
}
return -1;
}
写法2:[left, right)
定义 target 是在一个左闭右开的区间里即[left, right)
🔸左闭右开,left == right是无意义的,所以while (left < right) 要使用 <=
🔸if (nums[middle] > target) right 更新为 middle,因为当前nums[middle]不等于target,去左区间继续寻找,而寻找区间是左闭右开区间,所以right更新为middle,即:下一个查询区间不会去比较nums[middle]
例如在数组:1,2,3,4,7,9,10中查找元素2,如图所示:
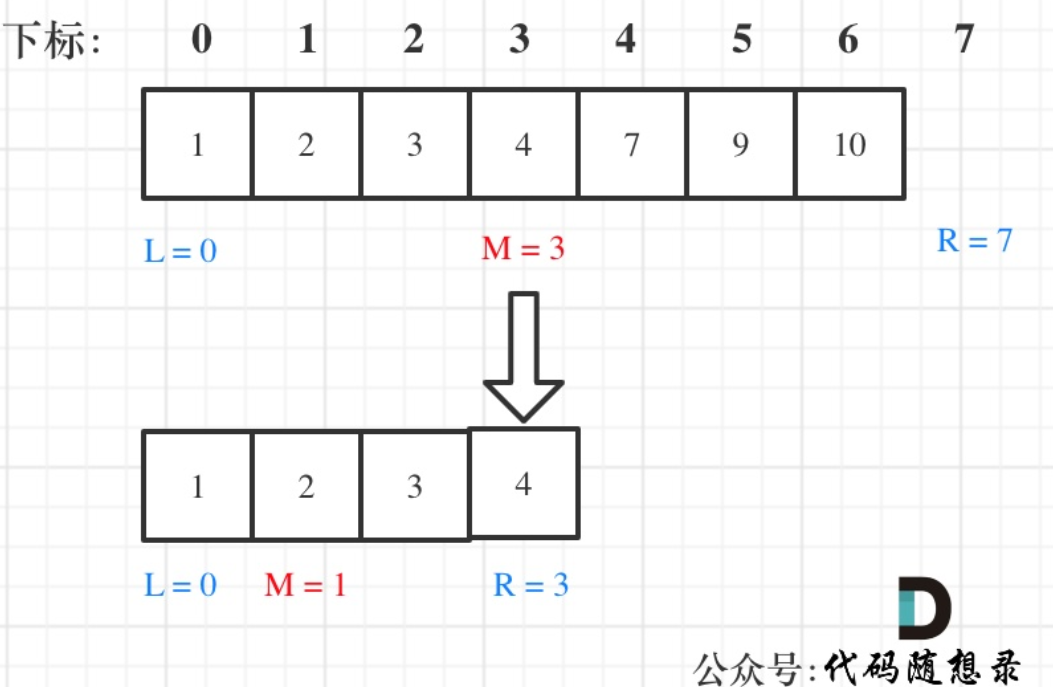
程序
int search(int* nums, int numsSize, int target)//数组,数组大小,要找的目标值target.最终返回target的下标
{
int left=0;//左下标
int right=numsSize;//右下标,定义target在左闭右开的区间里,即:[left, right),所以直接等于numsSize
int mid=0;//中点下标
while(left<right)//当left==right,区间[left, right)无效,所以用 <
{
mid=(left+right)/2;
if(nums[mid]==target)
{
return mid;// 数组中找到目标值,直接返回下标
}
else if(nums[mid]>target)
{
right=mid; // target 在左区间,所以[left, middle)
}
else
{
left=mid+1;// target 在右区间,所以[middle + 1, right)
}
}
return -1;
}
27. 移除元素
1. 题目
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
2. 分析
数组的元素在内存地址中是连续的,不能单独删除数组中的某个元素,只能覆盖。
写法1 暴力法
双重for循环
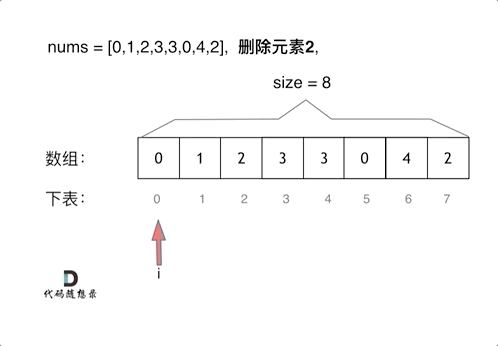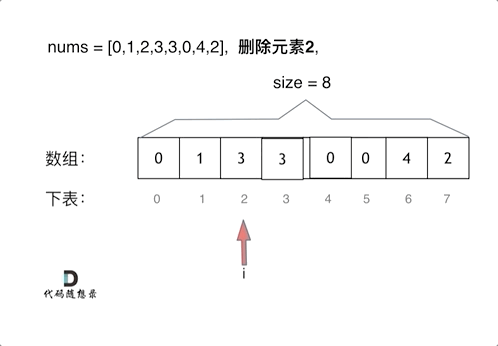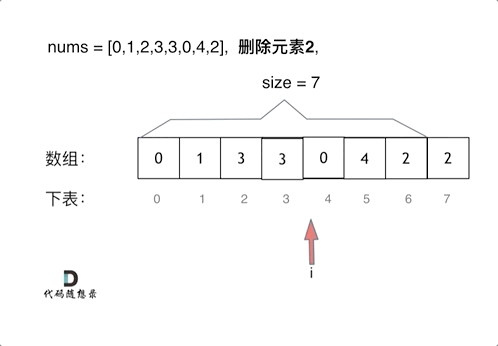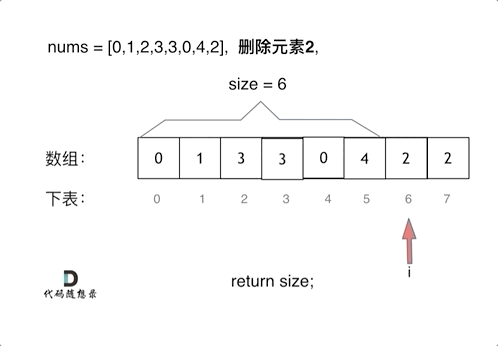
int removeElement(int* nums, int numsSize, int val)
{
int i;
int j;
for(i=0;i<numsSize;i++)
{
if(nums[i]==val)// 发现需要移除的元素,就将数组集体向前移动一位
{
for(j=i;j<numsSize-1;j++)//注意动图中从前往后覆盖的范围,止于numsSize-1
{
nums[j]=nums[j+1];
}
i--;//因为下标i以后的数值都向前移动了一位,所以i也向前移动一位
numsSize--;//修改numsSize为numsSize-1
}
}
return numsSize;
}
易错点:
漏加i–。不加的话会造成连续的两个val值出现的时候,只能删除一个。
i应该指向于被删除的目标值的前面一个数。
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
写法2 双指针法(快慢指针法)–重点
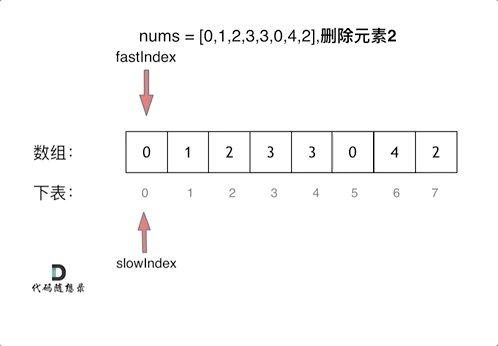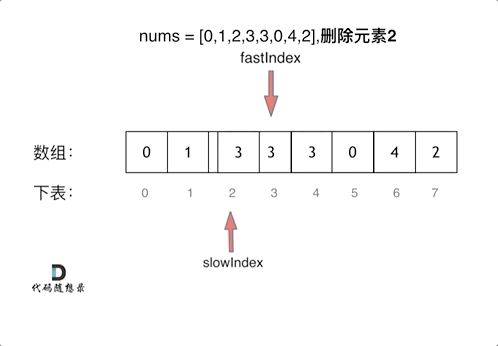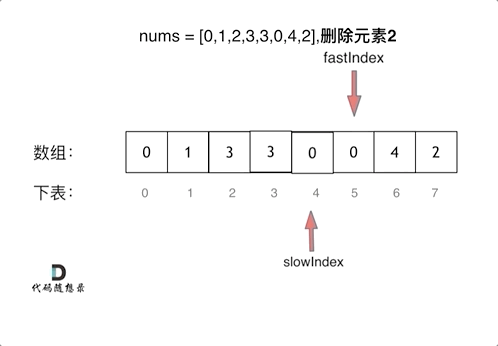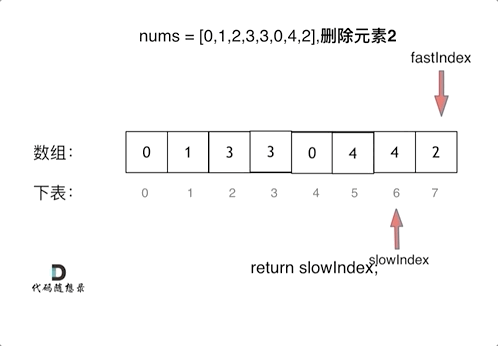
双指针法(快慢指针法)在数组和链表的操作中是非常常见的,很多考察数组、链表、字符串等操作的面试题,都使用双指针法。
如果快指针指向的值不是要删除的对象,那么就把快指针指向的值赋给慢指针指向的位置,slow和fast同时+1.
看动图就很清晰了,要能在脑中动态想象一遍这个过程。
程序
int removeElement(int* nums, int numsSize, int val)
{
int slow=0;
int fast;
for(fast=0;fast<numsSize;fast++)
{
if(nums[fast]!=val)//若快指针的位置的元素不是要删除的元素
{
nums[slow]=nums[fast];//就把快指针指向的值赋给慢指针指向的位置
slow++;//快指针和慢指针同时向后移动,slow+1
}
}
return slow;//slow就是新数组的大小
}
- 时间复杂度:O(n)
- 空间复杂度:O(1)
977.有序数组的平方
1. 题目
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
2. 分析
写法1:暴力排序
直接平方后排序。注意这里不可以用冒泡排序,冒泡排序双循环,复杂度n^2。这里要用qosrt
重点:调用qsort函数
调用qsort函数,要先写出cmp函数的定义。固定格式。
int cmp(const void * _a,const void *_b)
{
return (*(int*)_a - *(int*)_b);
}
int* sortedSquares(int* nums, int numsSize, int* returnSize){
int i,j;
(*returnSize)=numsSize;
int temp;
int* ans = (int*)malloc(sizeof(int) * numsSize);
for(i=0;i<numsSize;i++)
{
ans[i]=nums[i]*nums[i];
}
qsort(ans,numsSize,sizeof(int),cmp);
return ans;
}
for循环的复杂度是n,qsort的复杂度是nlogn,可以把整体的复杂度看出nlogn。
写法2:双指针法
数组其实是有序的, 只不过负数平方之后可能成为最大数了。
那么数组平方的最大值就在数组的两端,不是最左边就是最右边,不可能是中间。
此时可以考虑双指针法了,i指向起始位置,j指向终止位置。
定义一个新数组result,和A数组一样的大小,让k指向result数组终止位置。
如果A[i] * A[i] < A[j] * A[j] 那么result[k--] = A[j] * A[j]; 。
如果A[i] * A[i] >= A[j] * A[j] 那么result[k--] = A[i] * A[i]; 。
如动画所示:

int* sortedSquares(int* nums, int numsSize, int* returnSize){
(*returnSize)=numsSize;
int left,right;
left=0;right=numsSize-1;
int index;
//首先要设立三个指针:左指针,右指针,和新数组ans的指针
int *ans=(int*)malloc(sizeof(int)*numsSize);
//新建数组ans,并开辟一份空间
for(index=numsSize-1;index>=0;index--)
{
if(nums[left]*nums[left]<nums[right]*nums[right])//左指针平方比右指针的平方小
{
ans[index]=nums[right]*nums[right];//把右指针的平方赋给新数组
right--;//右指针左移
}
else//否则
{
ans[index]=nums[left]*nums[left];//把左指针的平方赋给新数组
left++;//左指针右移
}
}
return ans;//返回新的数组
}
209.长度最小的子数组
1. 题目
给定一个含有 n 个正整数的数组和一个正整数 target 。
找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
示例 1:
输入:target = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
示例 2:
输入:target = 4, nums = [1,4,4]
输出:1
示例 3:
输入:target = 11, nums = [1,1,1,1,1,1,1,1]
输出:0
2. 分析
写法1:暴力排序(O(n^2),不会通过)
int minSubArrayLen(int target, int* nums, int numsSize){
int sum;
int i,j;
int len=65535;
for(i=0;i<numsSize;i++)
{
sum=0;
for(j=i;j<numsSize;j++)
{
sum=sum+nums[j];
if(sum>=target&&(j-i+1)<=len)//连续子数组的和如果大于target且长度小于上一个len
{//j-i+1 是子序列的长度
len=j-i+1;//那么更新len
break;//并且跳出
}
}
}
if(len==65535) len=0;//如果len没有被更新过,说明没有满足条件的连续数组
return len;
}

写法2:滑动窗口
滑动窗口和双指针的思想类似。
滑动窗口,就是不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果。
滑动窗口如何用一个for循环来完成这个操作呢。
首先要思考 如果用一个for循环,那么应该表示 滑动窗口的起始位置,还是终止位置。
只用一个for循环,那么这个循环的索引,一定是表示 滑动窗口的终止位置。
那么问题来了, 滑动窗口的起始位置如何移动呢?
这里还是以题目中的示例来举例,s=7, 数组是 2,3,1,2,4,3,来看一下查找的过程
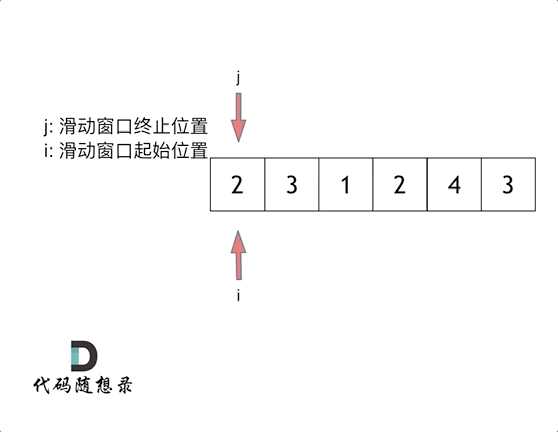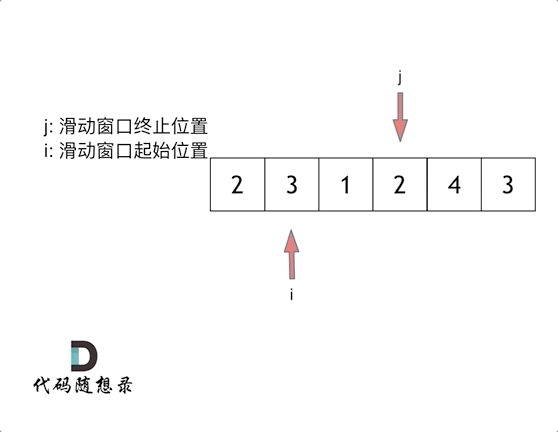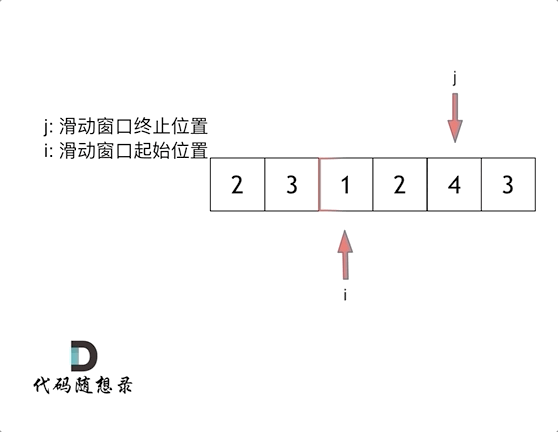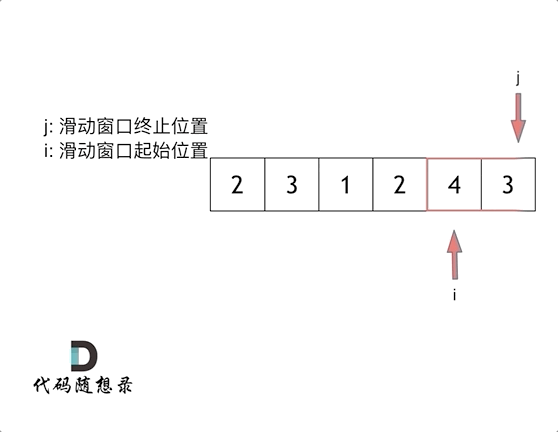
最后找到 4,3 是最短距离。
在本题中实现滑动窗口,主要确定如下三点:
- 窗口内是什么?
- 如何移动窗口的起始位置?
- 如何移动窗口的结束位置?
窗口就是 满足其和 ≥ s 的长度最小的 连续 子数组。
窗口的起始位置如何移动:如果当前窗口的值大于s了,窗口就要向前移动了(也就是该缩小了)。
窗口的结束位置如何移动:窗口的结束位置就是遍历数组的指针,也就是for循环里的索引。
int minSubArrayLen(int target, int* nums, int numsSize){
int start,end;
//滑动窗口的起始位置和终止位置
start=0;end=0;
int sum=0;
int len=INT_MAX;//易错点
for(;end<numsSize;end++)//只需要一层对end指针的循环,即滑动窗口的终止位置的索引
{
sum+=nums[end];//sum:对窗口内的值累加
while(sum>=target)//当窗口满足大于等于target的值就要缩小窗口了。
{//注意用的是while。
if(len>=end-start+1)//end-start+1 是子序列的长度,即窗口的长度
{
len=end-start+1;//更新长度,直到最小长度
}
sum=sum-nums[start];//缩小窗口的同时要把sum也缩小了
start++;//起始位置右移
}
}
if(len==INT_MAX) len=0;//如果len没有被更新过,说明没有满足条件的连续数组
return len;
}
程序中加了while的复杂度不一定会是O(n^2)。需要关注每个元素被操作的次数。
此程序中,每个元素在滑动窗后进来操作一次,出去操作一次,每个元素都是被操作两次,所以时间复杂度是 2 × n 也就是O(n)。
易错点:len=INT_MAX是稳定的写法,自己写的65535会报错
C中常量INT_MAX和INT_MIN分别表示最大、最小整数,定义在头文件limits.h中。
-
INT_MAX,INT_MIN数值大小:
因为int占4字节32位,根据二进制编码的规则,INT_MAX = 2^31-1,INT_MIN= -2^31 -
关于INT_MAX INT_MIN的运算
由于二进制编码按原码、补码和反码的规则进行运算,所有程序中对INT_MAX和INT_MIN的运算应当格外注意,在出现溢出的时候,不遵循数学规则。
INT_MAX + 1 = INT_MIN
INT_MIN – 1 = INT_MAX
abs(INT_MIN) = INT_MIN
比较有趣的是,INT_MAX + 1 < INT_MAX, INT_MIN – 1 > INT_MIN, abs(INT_MIN) < 0.
版权声明:本文为CSDN博主「zhusf16」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012604810/article/details/80290706
59. 螺旋矩阵 II
1. 题目
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
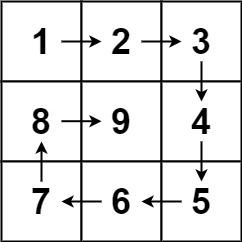
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
2. 分析
可以总结出一圈下来,需要画四条边。这四条边都要用固定的规则来遍历!
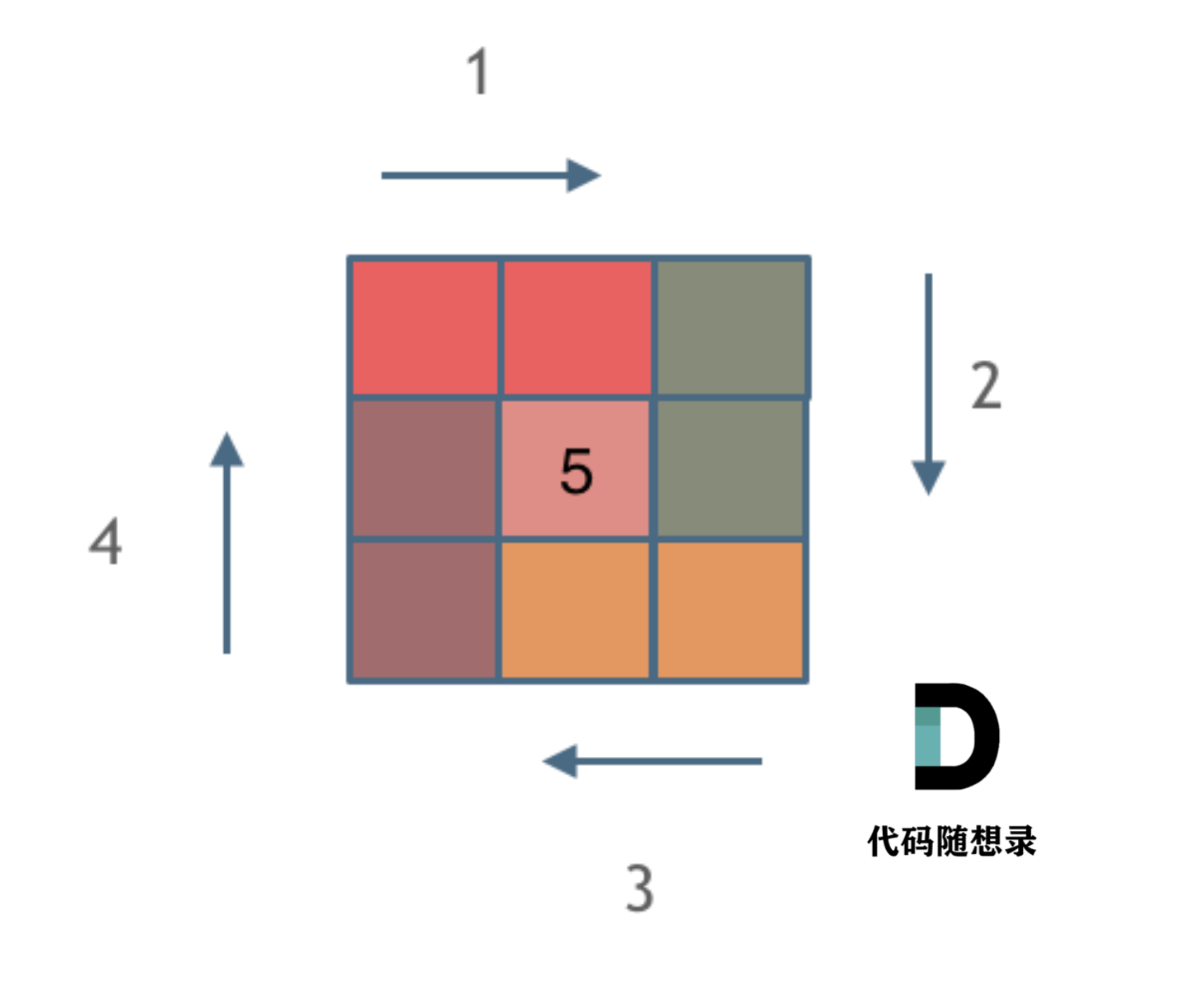
-
经过观察,比如n=3时,每条边可以划分为边长为2的边。所以需要考虑边界的判定条件。边界条件需要依据循环不变量的原则,统一实行左闭右开。
-
其次,当n=4时,我们可以观察到需要画两圈。所以n不同,循环圈数也不同。设置变量循环圈数loop。loop=n/2。
-
在第二圈的时候,初始位置从(0,0)变成了(1,1)。所以需要设置变量startX,startY确定初始位置。在进入下一圈前,startX+1,startY+1。
-
当n=4时,在第二圈的时候,边长比第一圈-1了。所以需要设置偏移量offset。在进入下一圈前,offset+1。
-
每一圈的操作都是模拟顺时针画矩阵的过程:
-
填充上行从左到右
-
填充右列从上到下
-
填充下行从右到左
-
填充左列从下到上
所以while循环的判定条件是按圈来的。while(loop–)。
循环结束的最后,把最后一个值写入矩阵的最中间的值。这个部分需要最后另外写入。
3.知识补充:二维数组开辟存储空间
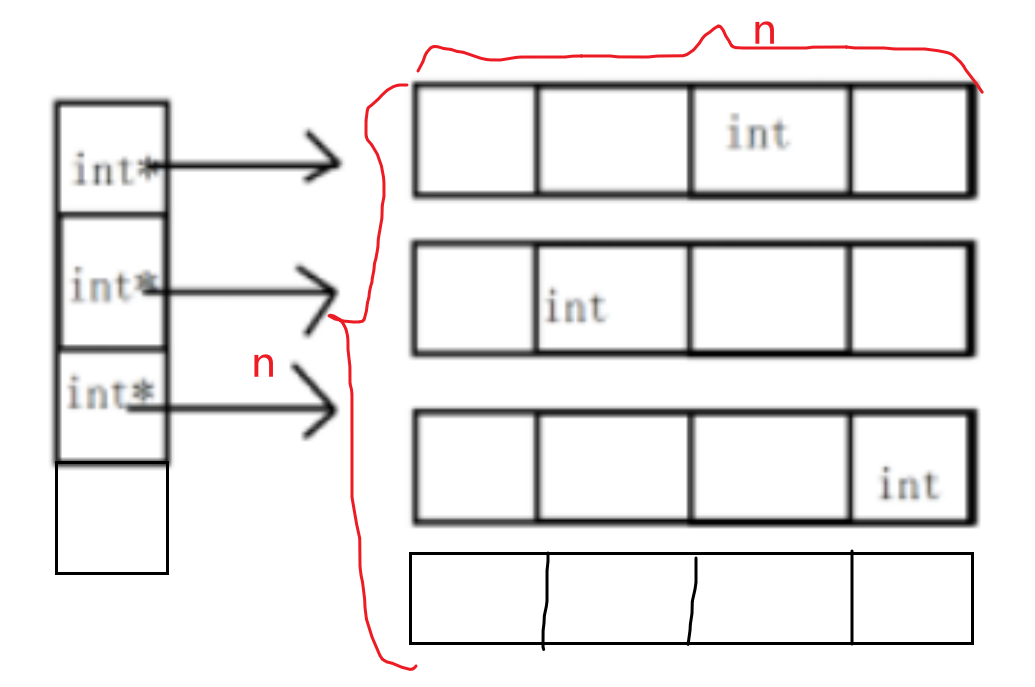
先看一下用malloc申请一维数组:
int *p=(int *)malloc(n*sizeof(int));//开辟n个内存空间
首先申请n个指针数组(不是数组指针)int *,既然是指针数组,存放的都是指针,那么我们就可以在此基础上继续开辟n个内存空间。由此构成了n * n的二维数组空间。
int **ans=(int*)malloc(sizeof(int*)*n);//申请指针数组
for(i=0;i<n;i++)
{
ans[i]=(int*)malloc(sizeof(int)*n);//再申请n个内存空间
}
参考博客:
(14条消息) 用malloc开辟二维数组的三种办法_张淑芬~的博客-CSDN博客_malloc二维数组
/**
* Return an array of arrays of size *returnSize.
* The sizes of the arrays are returned as *returnColumnSizes array.
* Note: Both returned array and *columnSizes array must be malloced, assume caller calls free().
*/
int** generateMatrix(int n, int* returnSize, int** returnColumnSizes){
(*returnSize)=n;
(*returnColumnSizes)=(int*)malloc(sizeof(int)*n);
int **ans=(int*)malloc(sizeof(int*)*n);//开辟新空间
int i,j;
for(i=0;i<n;i++)
{
ans[i]=(int*)malloc(sizeof(int)*n);
(*returnColumnSizes)[i]=n;
}
int startX = 0;
int startY = 0;
int loop=n/2;//循环圈数
int offset=1;//每一圈的边长都需要调整,所以需要offset偏移数
int mid=n/2;//中间值的坐标。中间值需要最后另外写入
int count=1;//待写入的数值
while(loop--)
{
i=startX;
j=startY;
//上行:从左到右
for(j=startY;j<n-offset;j++)
ans[i][j]=count++;
//右列:从上到下
for(i=startX;i<n-offset;i++)
ans[i][j]=count++;
//下行:从右到左
for(;j>startY;j--)
ans[i][j]=count++;
//左列:从上到下
for(;i>startX;i--)
ans[i][j]=count++;
//从第二圈开始,起始位置都要+1
//例如,第一圈起始位置(0,0)第二圈起始位置(1,1)
startX++;
startY++;
//第二圈开始,边长-1,所以要修正
offset +=1;
}
if(n%2)
ans[mid][mid]=count;
return ans;
}
203.移除链表元素
1. 题目
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
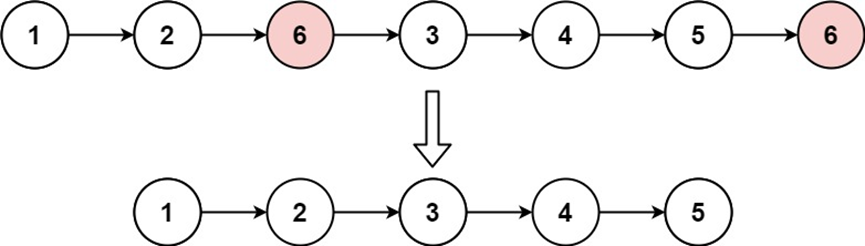
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
2. 分析
写法1:暴力排序
注意:使用C语言和C++需要在内存中删除释放掉移除的节点。
写法1:直接使用原来的链表来进行删除操作
头节点的移除和移除其他节点是不一样的
(1) 移除头节点
(2) 移除其他节点
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode *temp;
//1. 释放头指针
while(head&&head->val==val)//当头指针不为空且头指针的值是需要被移除的对象时
{
temp=head;//把原头节点赋给temp
head=head->next;// 将新的头结点设置为head->next并删除原来的头结点
free(temp);//释放temp,即释放掉原来的头指针的内存
}
//2. 释放其他指针
struct ListNode* cur=head;
while(cur&&(temp=cur->next))
{
if(temp->val==val)//如果当前cur的下一个val是要被删除的目标
{
cur->next=temp->next;//那么就跳过。temp->next其实就是cur->next->next
free(temp);//释放temp,即释放掉了要删除的目标的内存
}
else
{
cur=cur->next;//若cur->next不等于val,则将cur后移一位
}
}
return head;
}
写法2:设置一个虚拟头结点在进行删除操作
设置一个虚拟节点,移除头节点和其他节点的操作都一样
struct ListNode* removeElements(struct ListNode* head, int val){
//设置虚拟头节点的操作
//需要记忆!!!
struct ListNode *shead;
shead=(struct ListNode *)malloc(sizeof(struct ListNode));
shead->next=head;//头节点的下一个指向head
//移除链表元素
struct ListNode *cur=shead;
struct ListNode *tmp;
while(cur->next!=NULL)
{
if(cur->next->val==val)
{
tmp=cur->next;
cur->next=cur->next->next;
free(tmp);
}
else
{
cur=cur->next;
}
}
head=shead->next;
free(shead);
return head;
}
这两种方法是处理链表的常用两种方法
707.设计链表
1. 题目
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
- get(index):获取链表中第
index个节点的值。如果索引无效,则返回-1。 - addAtHead(val):在链表的第一个元素之前添加一个值为
val的节点。插入后,新节点将成为链表的第一个节点。 - addAtTail(val):将值为
val的节点追加到链表的最后一个元素。 - addAtIndex(index,val):在链表中的第
index个节点之前添加值为val的节点。如果index等于链表的长度,则该节点将附加到链表的末尾。如果index大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。 - deleteAtIndex(index):如果索引
index有效,则删除链表中的第index个节点。
示例:
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3
linkedList.get(1); //返回2
linkedList.deleteAtIndex(1); //现在链表是1-> 3
linkedList.get(1); //返回3
2. 分析
这道题目设计链表的五个接口:
- 获取链表第index个节点的数值
- 在链表的最前面插入一个节点
- 在链表的最后面插入一个节点
- 在链表第index个节点前面插入一个节点
- 删除链表的第index个节点
链表操作的两种方式:
- 直接使用原来的链表来进行操作。
- 设置一个虚拟头结点在进行操作。
下面全篇都是默认有一个虚拟头节点的方式。
如果对头节点操作,头节点的值都被修改了,最后就无法返回头节点。
//全篇都是默认有一个虚拟头节点的方式
typedef struct aa{
int val;
struct aa* next;
}MyLinkedList;
MyLinkedList* myLinkedListCreate() {
//设置虚拟头结点的惯用操作
MyLinkedList *head;
head=(MyLinkedList *)malloc(sizeof(MyLinkedList));
head->next=NULL;
return head;
}
int myLinkedListGet(MyLinkedList* obj, int index) {
int cnt=-1;//使用了虚拟头节点。所以cnt从-1计算。相当于虚拟头节点的下标是-1
while(obj!=NULL)//遍历obj开始寻找
{
if(cnt==index)//找到了下标index的对象
{
return obj->val;//返回链表中第 index 个节点的值
break;//并且跳出
}
else
{
cnt++;//否则就下标+1
obj=obj->next;//obj指向下一个
}
}
return -1;//没找到,循环退出了,就返回-1
}
void myLinkedListAddAtHead(MyLinkedList* obj, int val) {
MyLinkedList *tmp;
tmp=(MyLinkedList *)malloc(sizeof(MyLinkedList));
tmp->val=val;
tmp->next=obj->next;//注意使用的是虚拟头节点,所以tmp->next=obj->next
obj->next=tmp;
}
void myLinkedListAddAtTail(MyLinkedList* obj, int val) {
while(obj->next != NULL){
obj = obj->next;//循环,直到最后一个
}
MyLinkedList *tmp;
tmp=(MyLinkedList *)malloc(sizeof(MyLinkedList));
tmp->val=val;
tmp->next=NULL;
obj->next=tmp;//把tmp直接插在最后
}
void myLinkedListAddAtIndex(MyLinkedList* obj, int index, int val) {
int cnt=0;
MyLinkedList *tmp;
tmp=(MyLinkedList *)malloc(sizeof(MyLinkedList));
MyLinkedList *cur;
cur=(MyLinkedList *)malloc(sizeof(MyLinkedList));
if(index==0)//index为1就是再头部插入节点
{
myLinkedListAddAtHead(obj,val);
return;
}
while(obj!=NULL)
{
if(cnt==index)//找到了下标index的对象的前一个对象。开始插入
{
tmp->val=val;
tmp->next=obj->next;
obj->next=tmp;
return;//并且跳出
}
else
{
obj=obj->next;
cnt++;//否则就下标+1
}
}
return;
}
void myLinkedListDeleteAtIndex(MyLinkedList* obj, int index) {
int cnt=0;
MyLinkedList *tmp;
tmp=(MyLinkedList *)malloc(sizeof(MyLinkedList));
if(index==0)
{
tmp=obj->next;
if(tmp!=NULL)
{
obj->next=tmp->next;
free(tmp);
}
return;
}
while(obj!=NULL)
{
if(cnt==index)//找到了下标index的对象
{
tmp=obj->next;
if(tmp!=NULL)
{
obj->next=tmp->next;
free(tmp);
}
break;//并且跳出
}
else
{
cnt++;//否则就下标+1
obj=obj->next;
}
}
return;
}
void myLinkedListFree(MyLinkedList* obj) {
//释放虚拟头节点
while(obj!=NULL)
{
MyLinkedList *tmp=obj;
obj=obj->next;
free(tmp);
}
}
206.反转链表
1. 题目
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
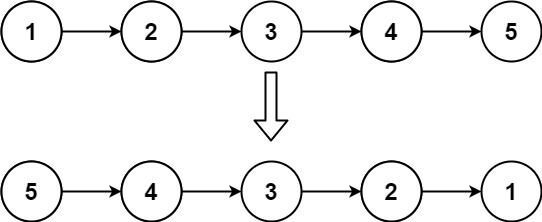
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
2.分析
如果再定义一个新的链表,实现链表元素的反转,其实这是对内存空间的浪费。
其实只需要改变链表的next指针的指向,直接将链表反转 ,而不用重新定义一个新的链表,如图所示:
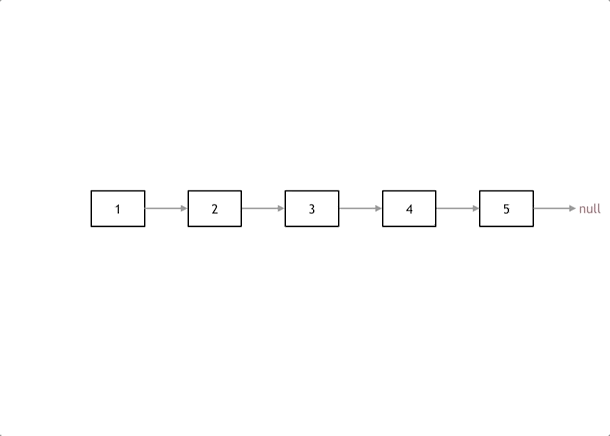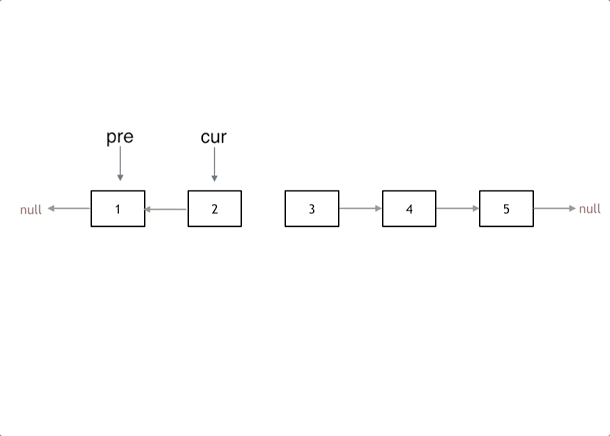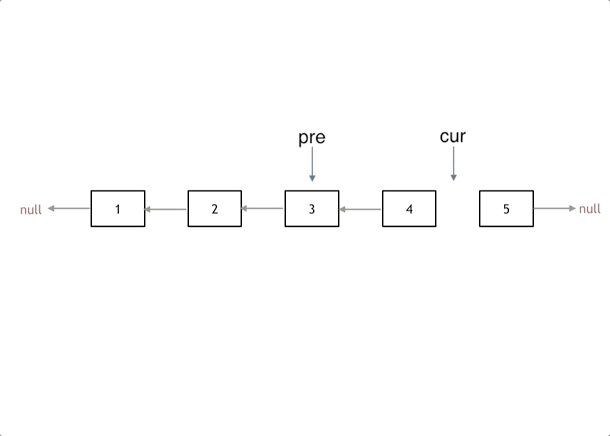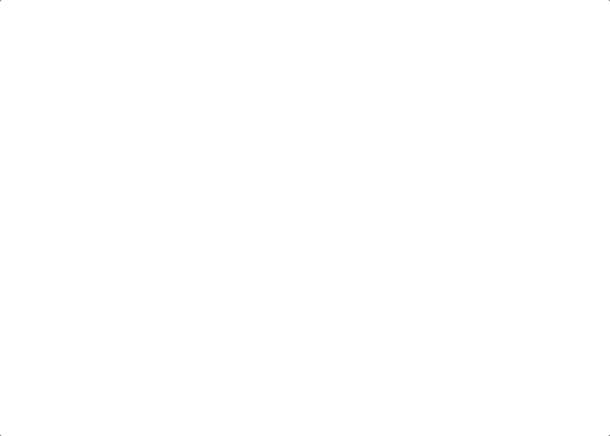
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。最后定义一个临时指针tmp来保存cur->next
以遍历cur为循环,两步操作:
- 翻转链表方向
2.全部后移
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
//首先定义一个cur指针,指向头节点
struct ListNode *cur=head;
//再定义一个pre,初始化为null
struct ListNode *pre=NULL;
//定义一个临时指针tmp来保存cur->next
struct ListNode *tmp;
while(cur!=NULL)
{
tmp=cur->next;//保留住cur->next
//1. 翻转链表方向
cur->next=pre;
//2.全部后移
pre=cur;//pre向后移
cur=tmp;//cur也向后移
}
return pre;
}
24. 两两交换链表中的节点
1.题目
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
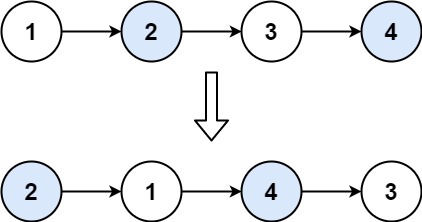
输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
2.分析
采用的还是设置一个虚拟头节点的方式
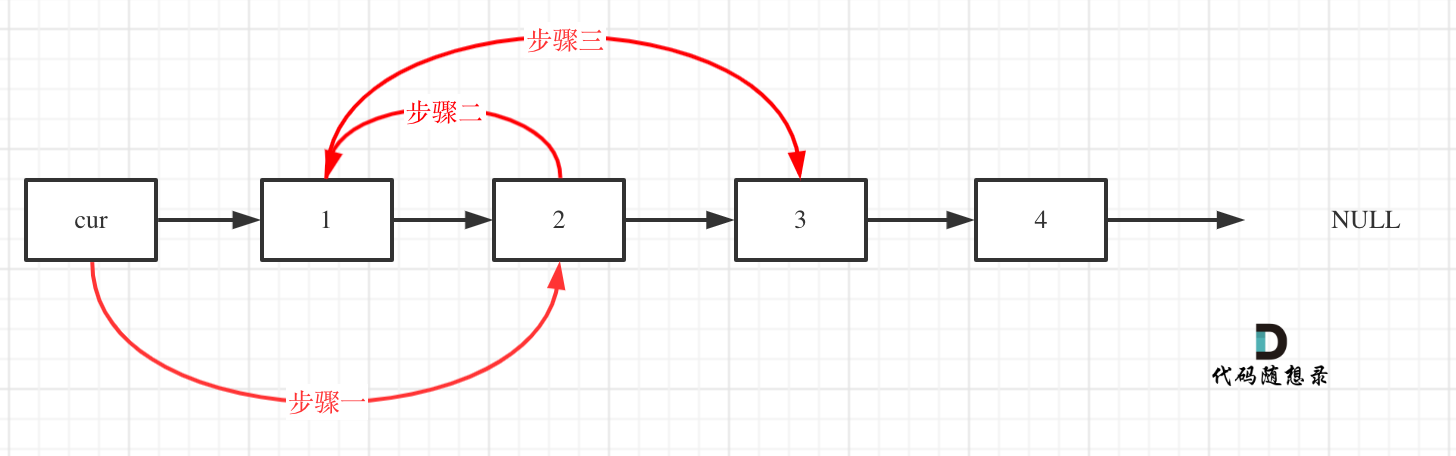
cur->next->next的前后两个节点cur->next和cur->next->next->next都断开了,为了能正确寻找到1和3,需要保存一下。设置临时保存点tmp1和tmp2。
链表需要区分奇数链表还是偶数链表:
奇数链表的最后cur->nextNULL;偶数链表cur->next->nextNULL;
以此来做判断while循环终止的条件。
注意要把cur->next!=NULL写在前面,cur->next->next!=NULL写在后面。否则容易出现空指针报错的情况。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* swapPairs(st
19. 删除链表的倒数第 N 个结点
1.题目
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
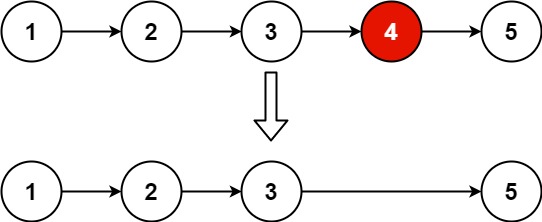
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
2.分析
- 定义fast指针和slow指针,初始值为虚拟头结点,如图:
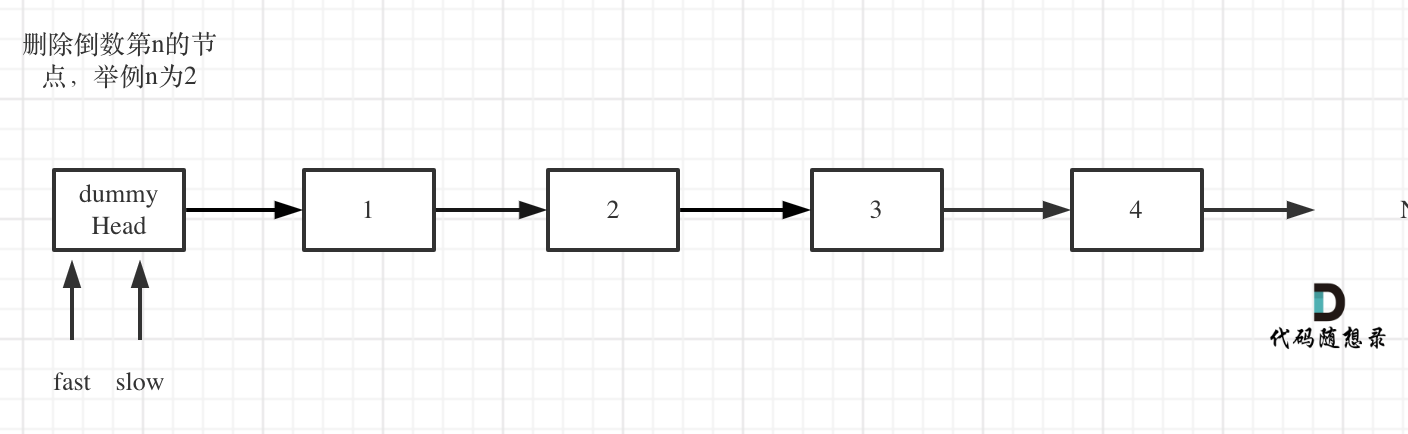
-
fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
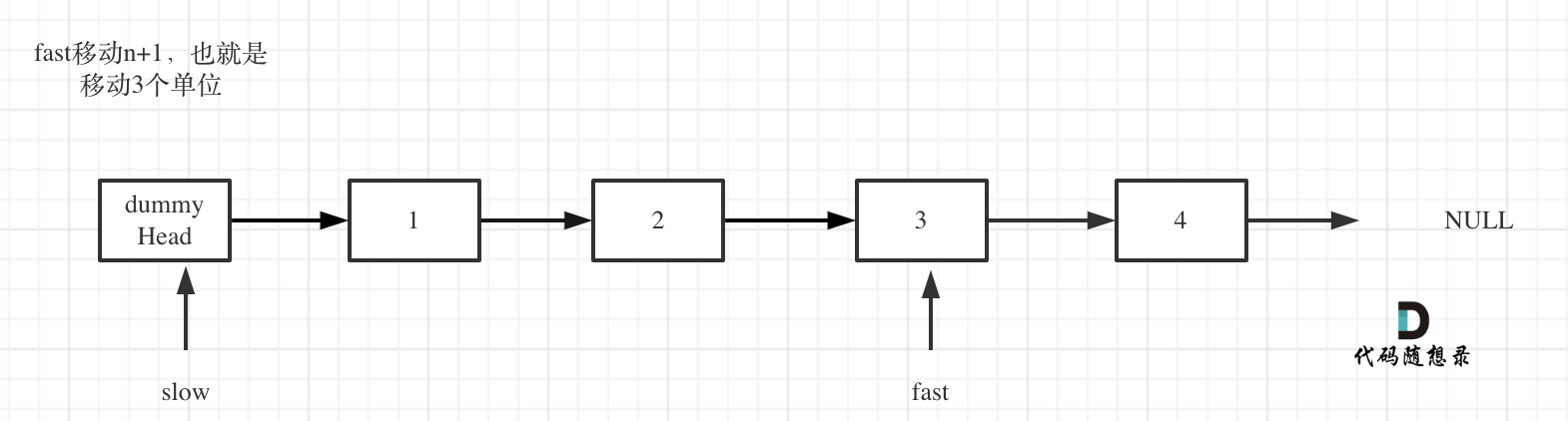
-
fast和slow同时移动,直到fast指向末尾,如题:
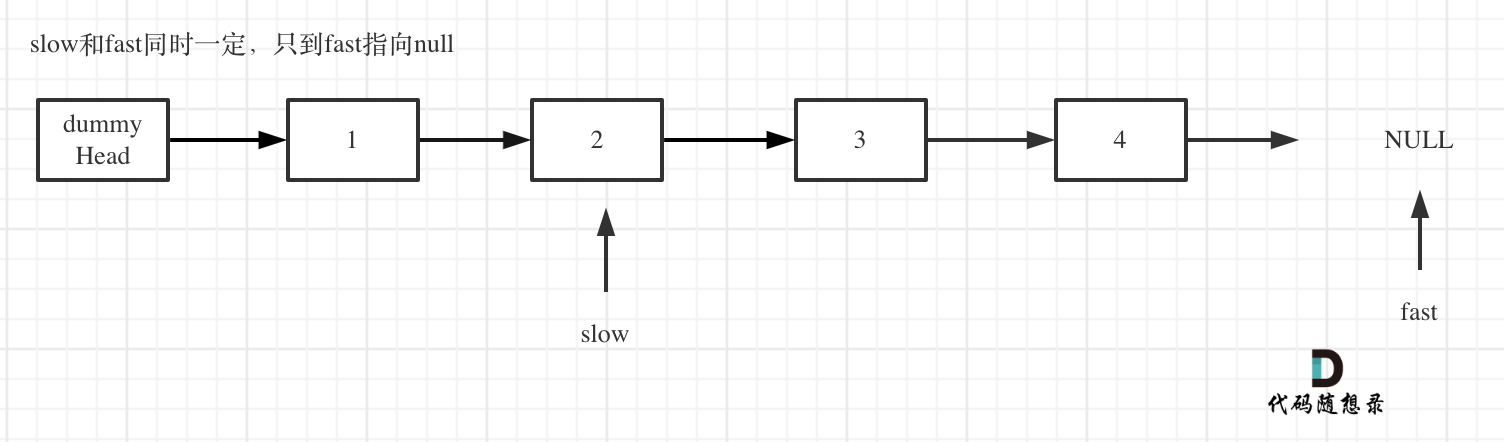
-
删除slow指向的下一个节点,如图:
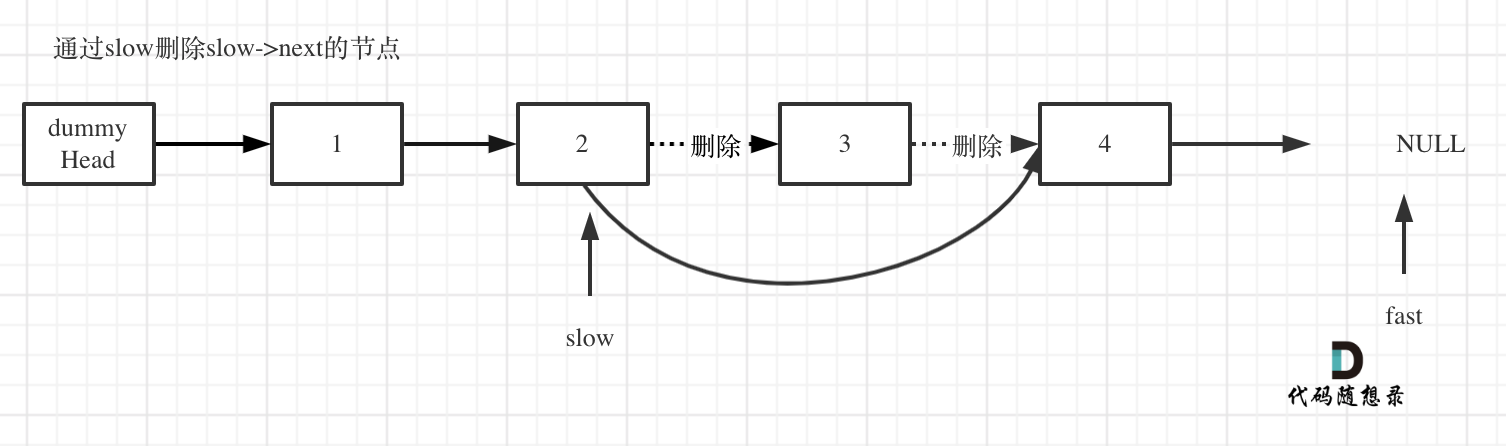
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeNthFromEnd(struct ListNode* head, int n){
//定义虚拟头节点
struct ListNode* dummy;
dummy=(struct ListNode*)malloc(sizeof(struct ListNode));
dummy->next=head;
//定义fast指针和slow指针,初始值为虚拟头结点
struct ListNode* fast;
struct ListNode* slow;
fast=dummy;
slow=dummy;
int cnt;
//定义临时存储变量tmp
struct ListNode* tmp;
//fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作)
for(cnt=0;cnt<n+1;cnt++)
{
if(fast!=NULL)
fast=fast->next;
}
while(fast!=NULL)
{
//fast和slow同时移动,直到fast指向末尾
fast=fast->next;
slow=slow->next;
}
//删除slow指向的下一个节点
tmp=slow->next;
slow->next=slow->next->next;
free(tmp);//释放内存
return dummy->next;
}
面试题 02.07. 链表相交
1.题目
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:

题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:

输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:

输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
2.分析
注意,交点不是数值相等,而是指针相等
看如下两个链表,目前curA指向链表A的头结点,curB指向链表B的头结点:
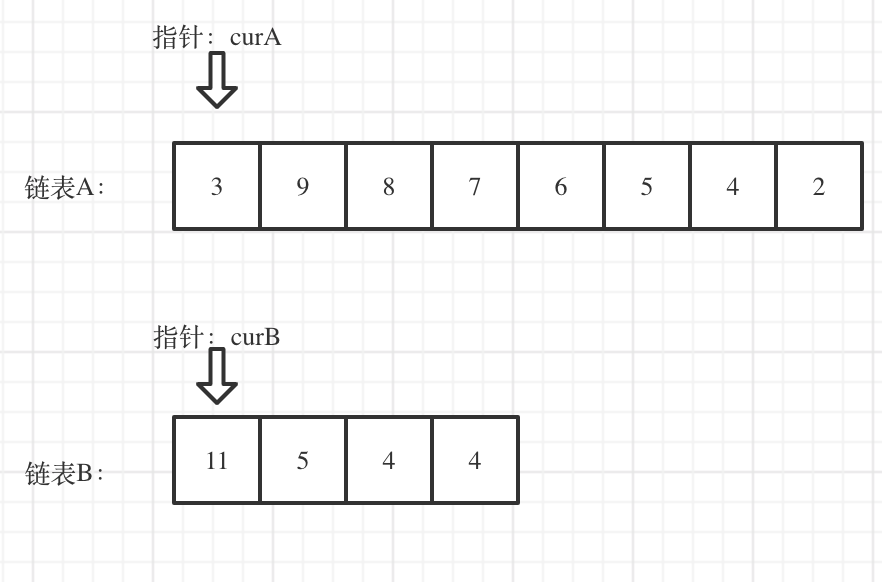
我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置,如图:
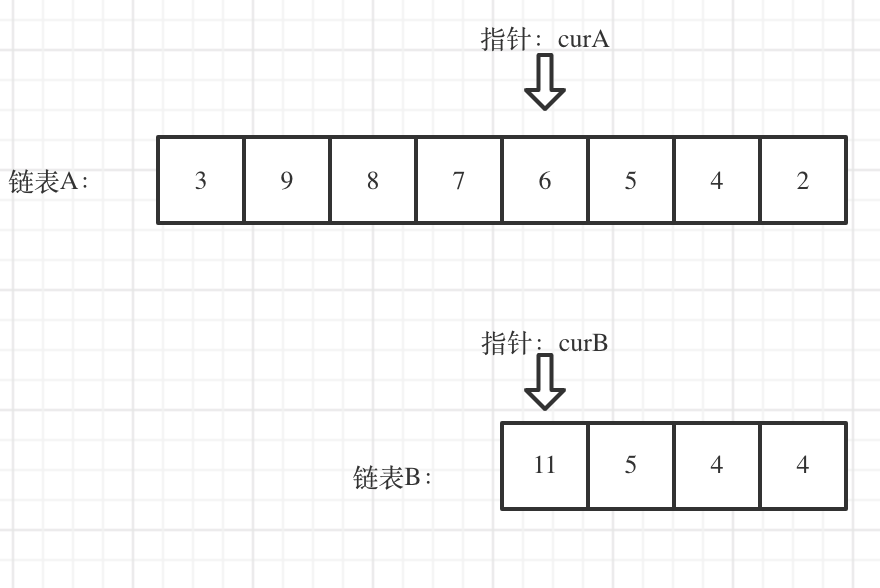
此时我们就可以比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到交点。
否则循环退出返回空指针。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode *curA=headA;
struct ListNode *curB=headB;
int cntA=0;
int cntB=0;
int cnt=0;
//我们求出两个链表的长度,并求出两个链表长度的差值,然后让curA移动到,和curB 末尾对齐的位置
//求出两个链表的长度
while(curA!=NULL)
{
curA=curA->next;
cntA++;
}
while(curB!=NULL)
{
curB=curB->next;
cntB++;
}
//求出两个链表长度的差值
curA=headA;
curB=headB;
cnt=abs(cntA-cntB);
//curA移动到,和curB 末尾对齐的位置
if(cntA-cntB>0)
{
while(cnt--)
{
curA=curA->next;
}
}
else
{
while(cnt--)
{
curB=curB->next;
}
}
// //比较curA和curB是否相同,如果不相同,同时向后移动curA和curB,如果遇到curA == curB,则找到交点。
while(curA!=NULL&&curB!=NULL)
{
if(curA==curB)//注意,交点不是数值相等,而是指针相等
{
printf("%d\n",curA->val);
return curA;
}
else
{
curA=curA->next;
curB=curB->next;
}
}
return NULL;
}
142.环形链表 II(数学推导)
1.题目
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
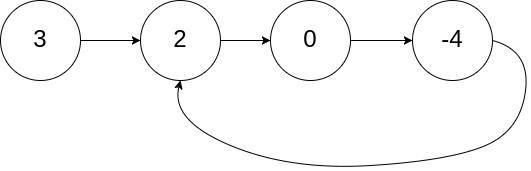
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
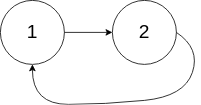
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
2.分析
这道题目,不仅考察对链表的操作,而且还需要一些数学运算。
主要考察两知识点:
- 判断链表是否环
- 如果有环,如何找到这个环的入口
#判断链表是否有环
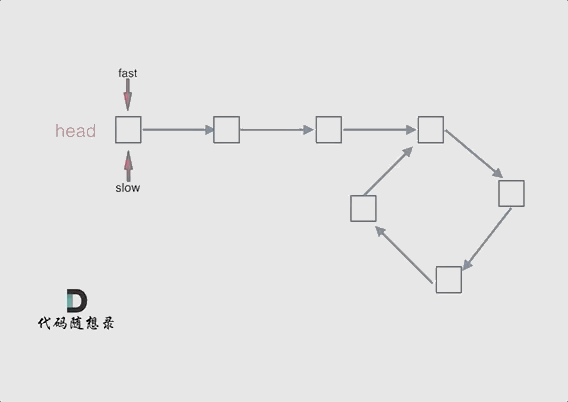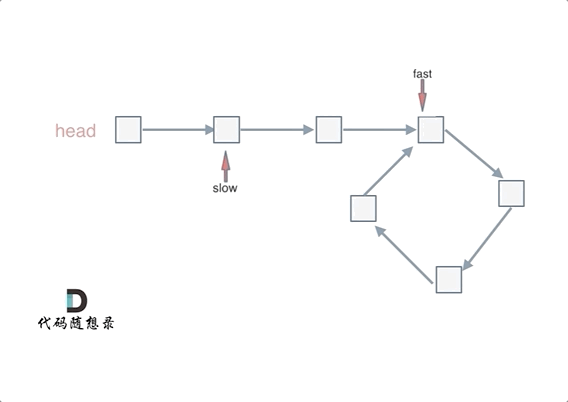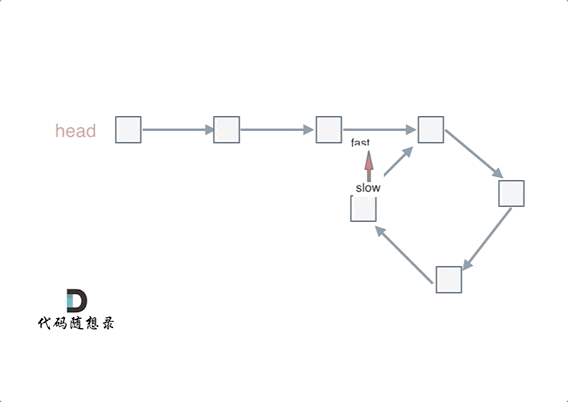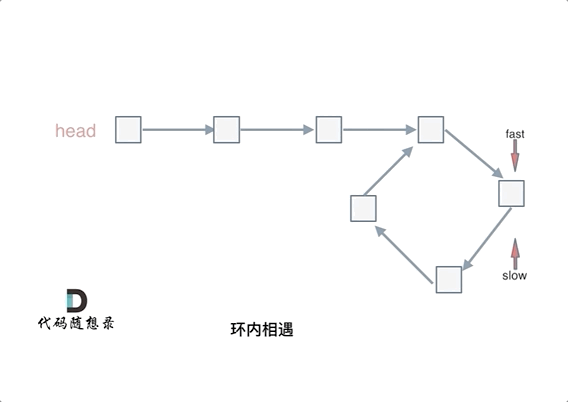
可以使用快慢指针法,分别定义 fast 和 slow 指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢
首先第一点:fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
那么来看一下,为什么fast指针和slow指针一定会相遇呢?
可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
会发现最终都是这种情况, 如下图:
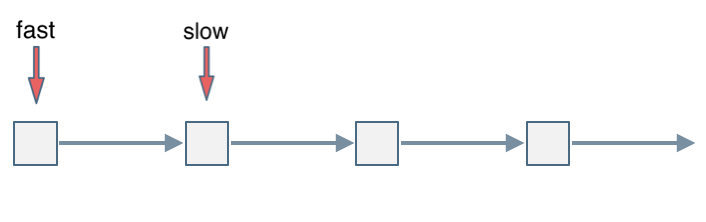
fast和slow各自再走一步, fast和slow就相遇了
这是因为fast是走两步,slow是走一步,其实相对于slow来说,fast是一个节点一个节点的靠近slow的,所以fast一定可以和slow重合。
动画如下:
#如果有环,如何找到这个环的入口
此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。
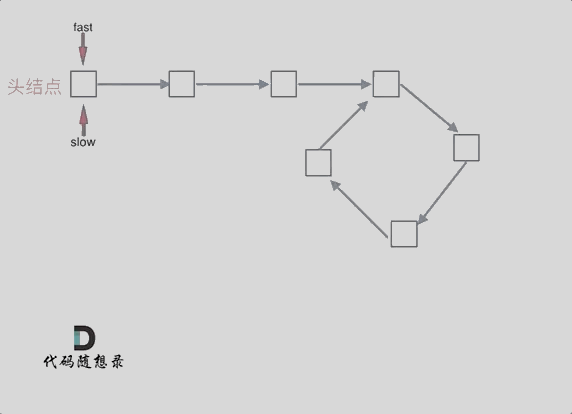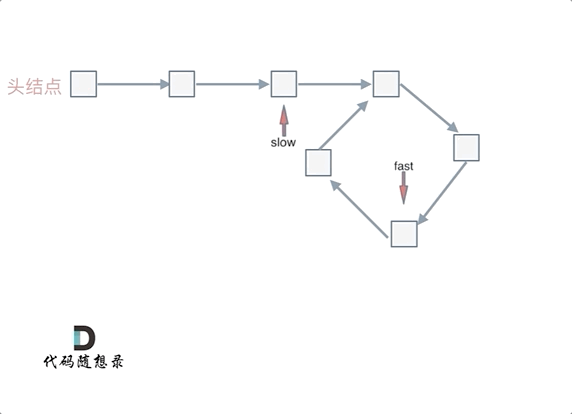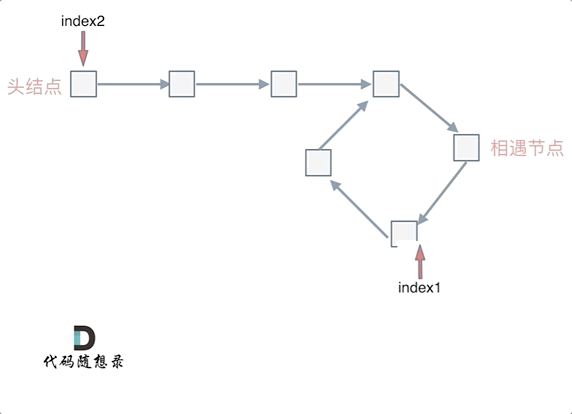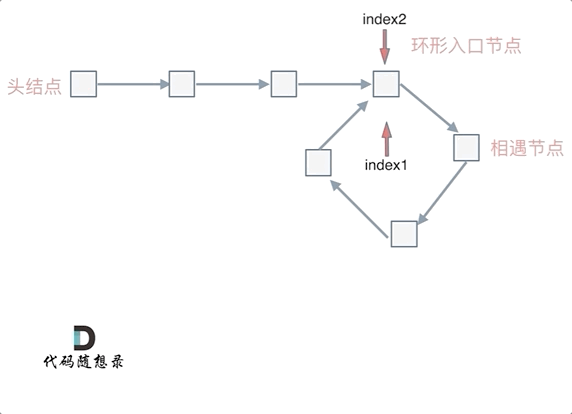
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。 如图所示:
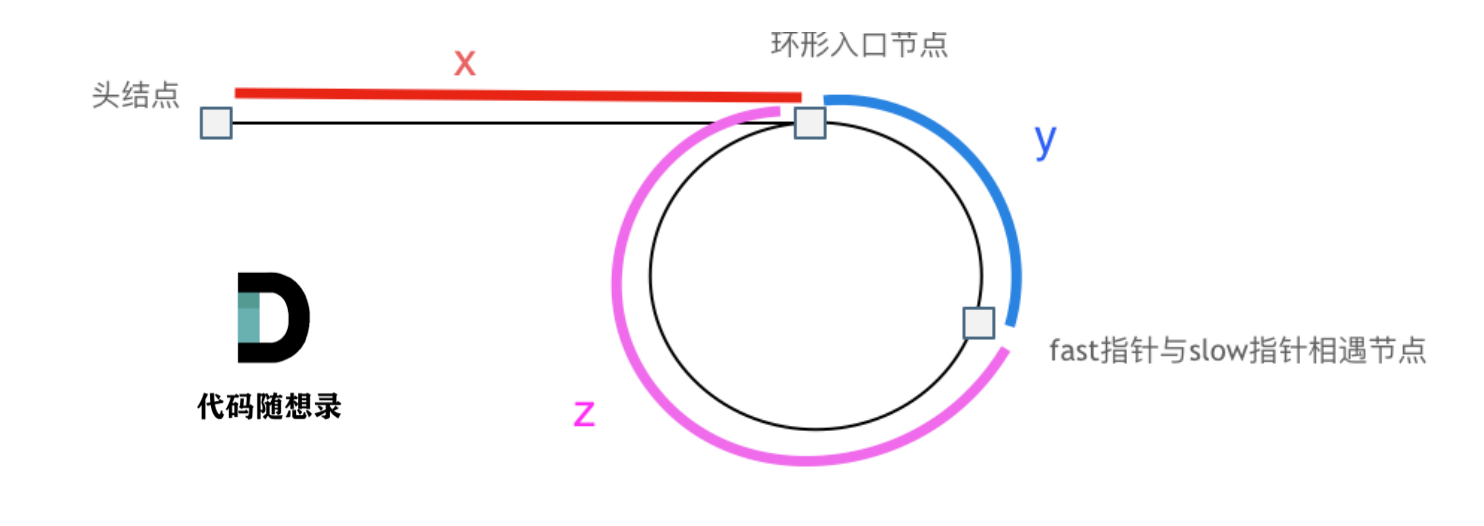
那么相遇时: slow指针走过的节点数为: x + y, fast指针走过的节点数:x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
(x + y) * 2 = x + y + n (y + z)
两边消掉一个(x+y): x + y = n (y + z)
因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:x = n (y + z) - y ,
再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:x = (n - 1) (y + z) + z 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 x = z,
这就意味着,从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
让index1和index2同时移动,每次移动一个节点, 那么他们相遇的地方就是 环形入口的节点。
动画如下:
那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
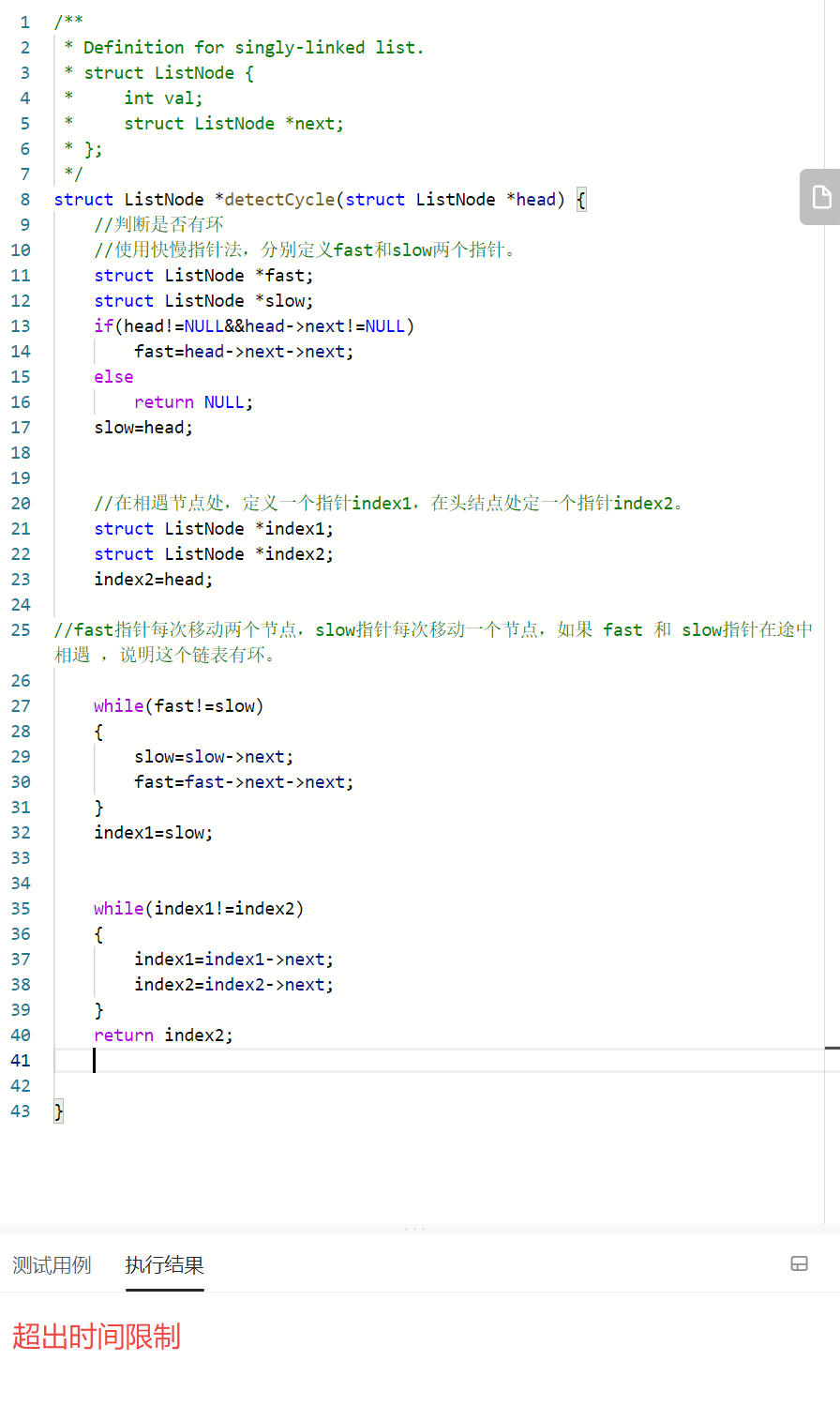
struct ListNode *detectCycle(struct ListNode *head) {
//判断是否有环
//使用快慢指针法,分别定义fast和slow两个指针。
struct ListNode *fast;
struct ListNode *slow;
fast=head;
slow=head;
//在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
struct ListNode *index1;
struct ListNode *index2;
index2=head;
//fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
while(fast!=NULL&&fast->next!=NULL)
{
slow=slow->next;
fast=fast->next->next;
if(fast==slow)
{
index1=slow;
while(index1!=index2)
{
index1=index1->next;
index2=index2->next;
}
return index2;
// printf("%d",index2->val);
}
}
return NULL;
}
原来的程序没有把握好结构的优化,超时了。
原文地址:http://www.cnblogs.com/MLcaigou/p/16804547.html