
观后感
Background
-
硬件近年来发展迅速,甚至超过了摩尔定律描述的速度。
-
互联网用户多,数据体量庞大,且传播较快较广泛。
-
AI发展迅速(其实是被大数据和高效的计算资源推着发展的)
Application
GAN-based Image
生成的fake_images有如下目标:
-
质量高,有逼真的特征细节纹理
-
种类多
DNN-based Speech
-
VC (voice conversion):可以理解为风格转换,A的内容+B的风格
-
TTS (Text to Speech)
AE-based Video
理解为逐帧进行替换(风格转换)
Decoder 分离identity and message,Encode进行一个重新添加。
问题:耗费较多训练资源,目前还需要比较多的人为调整,而调整操作必然留下痕迹,这也利于检测。
Impact
Positive
-
电影高难度动作、或者一些场景都可以进行生成
-
游戏、远程教育可以通过生成提高交互性
-
利于数字匿名化,隐藏个人的identity,可用于个人隐私保护
-
生成更具多样性的数据集
Negative(main)
-
制造假象,混淆视听,误导大众做出错误决策
-
降低公众对媒体的信任感,俗称一颗老鼠屎坏了一锅粥
-
信息量变大了,含金量并没有提高,信息流变得更为复杂。
Detection
虚假信息其实一直都存在,只是随着AI的发展,虚假信息流增强,更难以分辨且威胁性更大,由此Deep-Fake Detection愈发重要。
下图为吕思伟教授在讲座中给出的DeepFake Detection分类
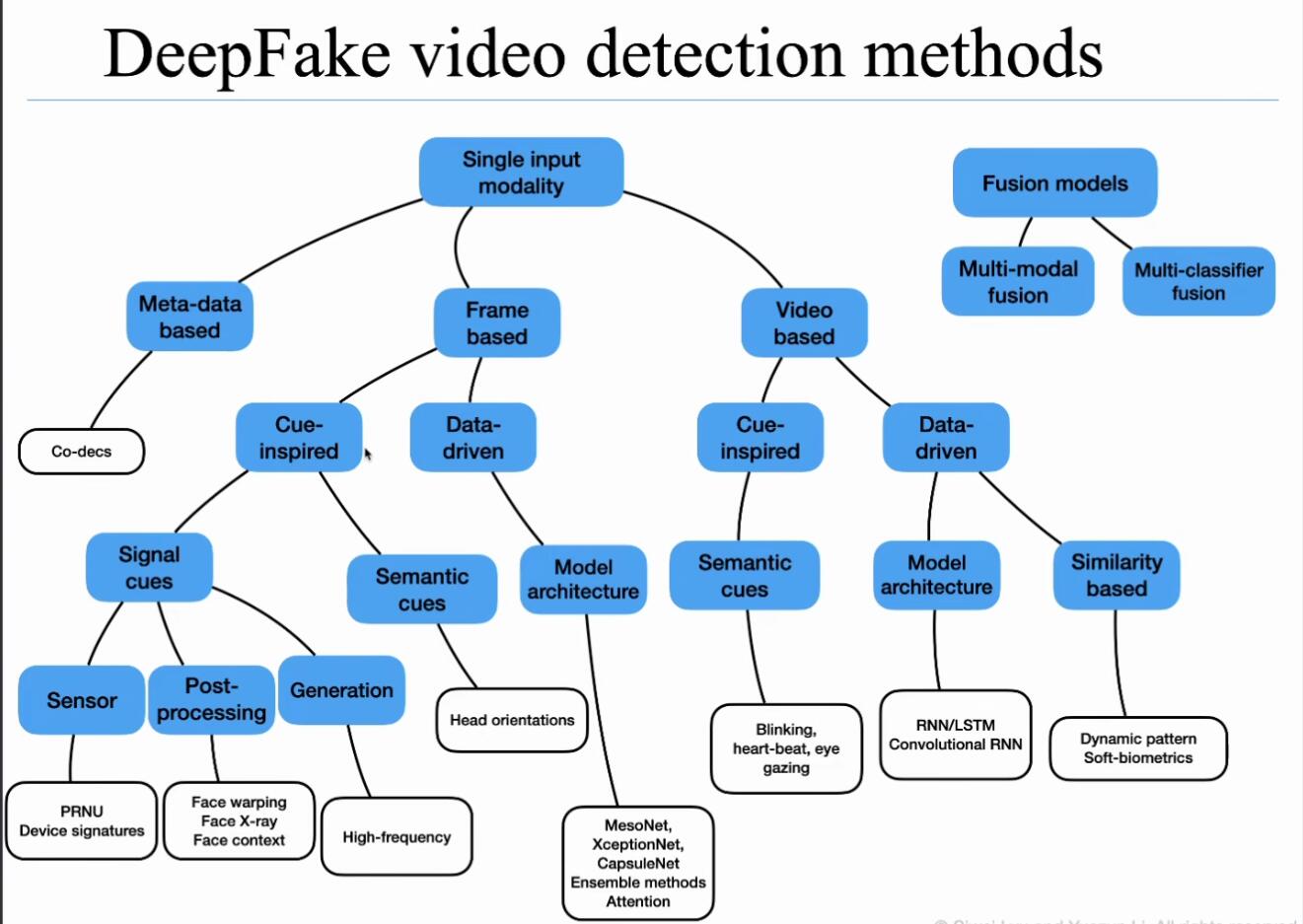
首先明确DeepFake检测是一个二分类问题。
其次可分为Single-modality 和 Multi-modality。
目前主流是Single-modality –> Frame-based –> Data-driven的检测手段。
Cue可以理解为Feature:
-
Signal cues:不关心内容,只关心数据本身构成。如Post-processing方法,即为检测生成fake_images后贴到视频里的后处理痕迹,鉴定是否为真。
-
Semantic cues:关心数据内容本身是否符合规律。如人脸各个组成的朝向是否正确,如眨眼频率。(个人感觉听起来可延展性较弱,貌似只能针对特定数据特定分布,而且开源后攻击者就可以注意到这个规律,生成符合特定规律的图像就可以骗过检测模型了)
总体感觉,没有一个普适性的、统一的、可延展的完善的检测方法,较为零碎。
Challenge
-
可解释性:随着Deep-Fake的负面影响越来越严重,除了需要检测出”鉴定为假“的结果,在实际应用中,往往不能单纯依靠机器判别,还需要给出假的理由。
-
目前检测方法从不同角度切入,种类很多,但可扩展性不强,缺乏一个统一的检测方法。攻击者可以很容易针对专门检测方法进行调整,绕过检测防御。
-
很多检测方法误判率较高。实际应用中容易影响用户体验感。
-
目前的检测手段实际上是一种事后的被动防御。现在很多人都有一致的想法,利用后门去破坏Deep-Fake的生成,进行主动防御。
Future
-
生成范围逐渐扩展。不再局限于人脸,逐渐生成四肢、全身…
-
共同生成音效+视频帧,更加逼真
-
逐步减少对数据的依赖。比如由单张图片生成动态的视频,由低维构建高维场景。
原文地址:http://www.cnblogs.com/Cyccyyycyc/p/16804732.html