
包的具体使用
虽然python3对包的要求降低了 不需要__init__.py也可以识别
但是为了兼容性考虑最好还是加上__init__.py
1.如果只想用包中某几个模块 那么还是按照之前的导入方式即可
from aaa import md1, md2
2.如果直接导入包名
import aaa
导入包其实就是导包下面的__init__.py文件,该文件内有什么名字就可以通过包点什么名字
编程思想的转变
1.面条版阶段
所有的代码全部堆叠在一起
2.函数版阶段
根据功能的不同封装不同的函数
3.模块版阶段
根据功能的不同拆分成不同的py文件
"""
第一个阶段可以看成是直接将所有数据放在C盘
视频 音频 文本 图片
第二个阶段可以看成是将C盘下的数据分类管理
视频文件夹 音频文件夹 文本文件夹 图片文件夹
第三个阶段可以看成是将C盘下的数据根据功能的不同划分分到更合适的位置
视频文件夹 C盘
视频文件夹 D盘
图片文件夹 E盘
ps:类似于开公司(工作室 小公司 上市公司)
为了资源的高效管理
"""
软件开发目录规范
1.文件及目录的名字可以变换 但是思想是不变的 分类管理
2.目录规范主要规定开发程序的过程中针对不同的文件功能需要做不同的分类
myproject项目文件
1.bin文件夹 主要存放项目启动文件
start.py 启动文件可以放在bin目录下 也可以直接在项目根目录
2.conf文件夹 主要存放项目的配置文件
settings.py 里面存放项目的默认配置 一般都是全大写
3.core文件夹 主要存放项目核心文件
src.py 里面存放项目核心功能
4.interface文件夹 主要存放项目接口文件
goods.py 根据具体业务逻辑划分对应的文件
uers.py
account.py
5.db文件夹 主要存放项目相关数据
userinfo.txt
db_handler.py 存放数据库相关操作代码
6.log文件夹 主要存放项目日志文件
log.log
7.lib文件夹 主要存放项目公共功能
common.py
8.readme文件 主要存放项目相关说明
9.requirements.txt文件 主要存放项目所需模块及版本
collections模块
1.具名元组namedtuple
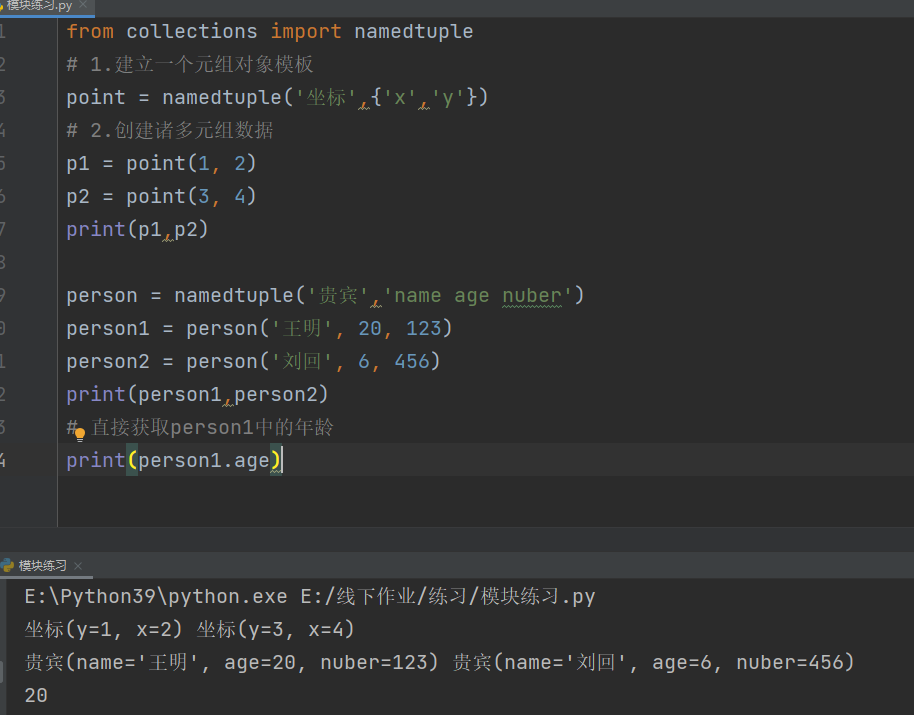
from collections import namedtuple # 使用from...import...的方式直接调用模块里面的功能
from collections import namedtuple
# 1.建立一个元组对象模板
point = namedtuple('坐标',{'x','y'})
# 2.创建诸多元组数据
p1 = point(1, 2)
p2 = point(3, 4)
print(p1,p2)
person = namedtuple('贵宾','name age nuber')
person1 = person('王明', 20, 123)
person2 = person('刘回', 6, 456)
print(person1,person2)
# 直接获取person1中的年龄
print(person1.age)
# 根据具名元组这个特性,它的使用范围也相对广泛,列如在数学领域或娱乐领域
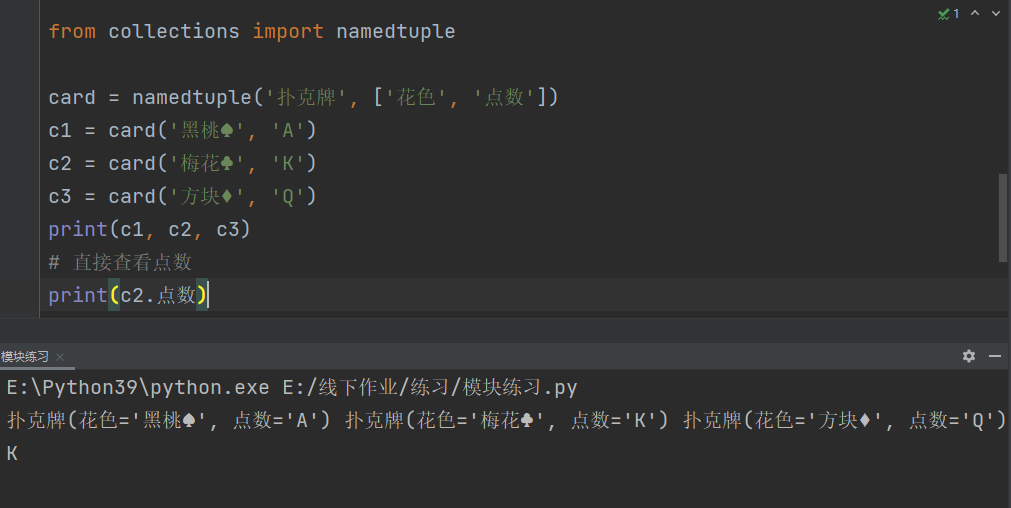
from collections import namedtuple
card = namedtuple('扑克牌', ['花色', '点数'])
c1 = card('黑桃♠', 'A')
c2 = card('梅花♣', 'K')
c3 = card('方块♦', 'Q')
print(c1, c2, c3)
# 直接查看点数
print(c2.点数)
2.双端队列deque
队列:
队列与堆栈
队列:先进先出
堆栈:先进后出
队列和堆栈都是一边只能进一边只能出
双端队列:两端都可以进出
import queue
q = queue.Queue(3) # 最多只能放三个元素
q.put(111)
q.put(222)
q.put(333)
q.put(444)
print(q.get()) # 111
print(q.get()) # 222
print(q.get()) # 333
print(q.get())
# 如果队列增加满了,继续增加程序就会原地等待

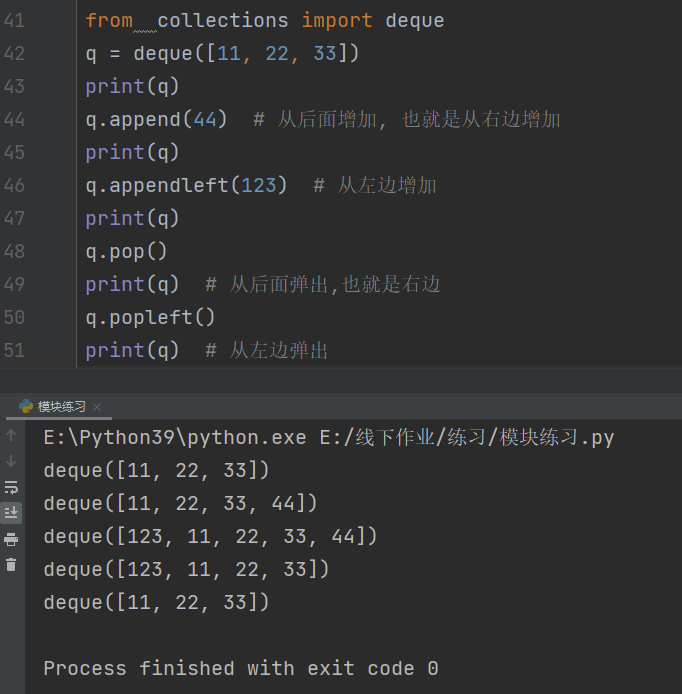
from collections import deque
q = deque([11, 22, 33])
print(q)
q.append(44) # 从后面增加, 也就是从右边增加
print(q)
q.appendleft(123) # 从左边增加
print(q)
q.pop()
print(q) # 从后面弹出,也就是右边
q.popleft()
print(q) # 从左边弹出
3.字典相关
# 字典的内部是无序的
d1 = dict([('name', 'moon'), ('pwd', 123), ('hobby', 'study')])
print(d1) # {'name': 'moon', 'pwd': 123, 'hobby': 'study'}
# 有序字典
from collections import OrderedDict
d1 = OrderedDict([('a', 1), ('b', 2),('c', 3)])
print(d1)
d1['x'] = 111
d1['y'] = 222
d1['z'] = 333
print(d1)

小练习:
"""
有如下集合
[11,22,33,44,55,67,77,88,99,999]
将所有大于 66 的值保存至字典的第一个key中 将小于 66 的值保存至第二个key的值中
"""
# 使用for循环来写
l1 = [11,22,33,44,55,66,77,88,99]
new_d = {'k1':[], 'k2':[]} # 大于66存k1,否则存k2
for i in l1:
if i > 66:
new_d['k1'].append(i)
else:
new_d['k2'].append(i)
print(new_d)
# {'k1': [67, 77, 88, 99, 999], 'k2': [11, 22, 33, 44, 55]}
# 使用defaultdict
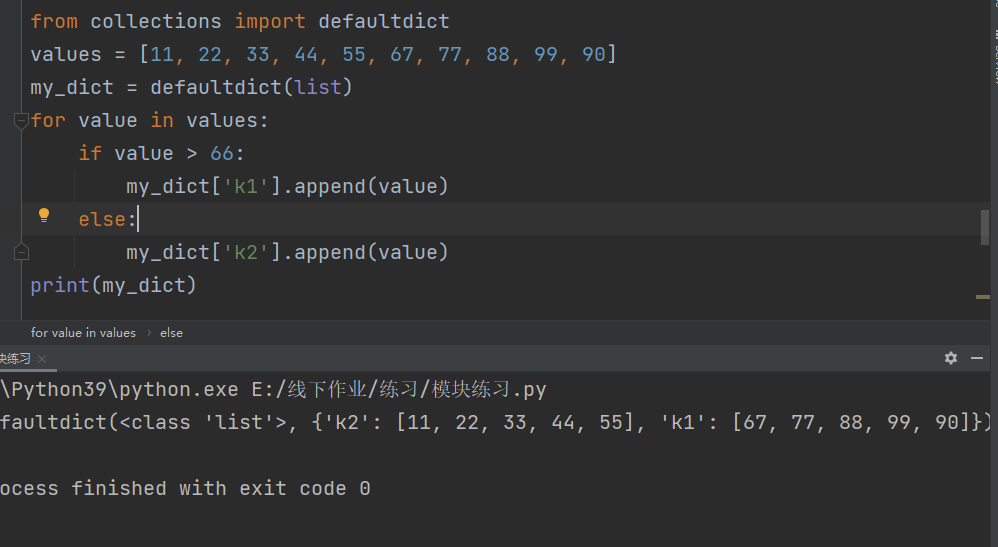
from collections import defaultdict
values = [11, 22, 33, 44, 55, 67, 77, 88, 99, 90]
my_dict = defaultdict(list)
for value in values:
if value > 66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
print(my_dict)
4.计数器 Counter
# 统计字符串里面字符出现的次数
res = 'ababbbababcab'
# 使用for循环
new_dict = {}
for i in res:
if i not in new_dict:
new_dict[i] = 1
else:
new_dict[i] += 1
print(new_dict) # {'a': 5, 'b': 7, 'c': 1}
# 使用counter
from collections import Counter
n = Counter(res)
print(n) # Counter({'b': 7, 'a': 5, 'c': 1})
print(r.get('a')) # 5
# 可以根据按key取值
time与datetime模块
1.time模块
import time
三种时间表现形式
1.时间戳
秒数
2.结构化时间
主要是给计算机看的 人看不适应
3.格式化时间
主要是给人看的
# 常用模块
1. time.sleep(secs) # secs就是推迟的秒数
推迟指定时间运行, 单位为秒
2.time.time
获取当前时间戳
# 三种用于表达时间的格式
1.时间戳
距离1970年0时0分0秒到现在的秒数
time.time()
2.结构化时间
这个时间类型主要是给计算机看的
time.localtime()
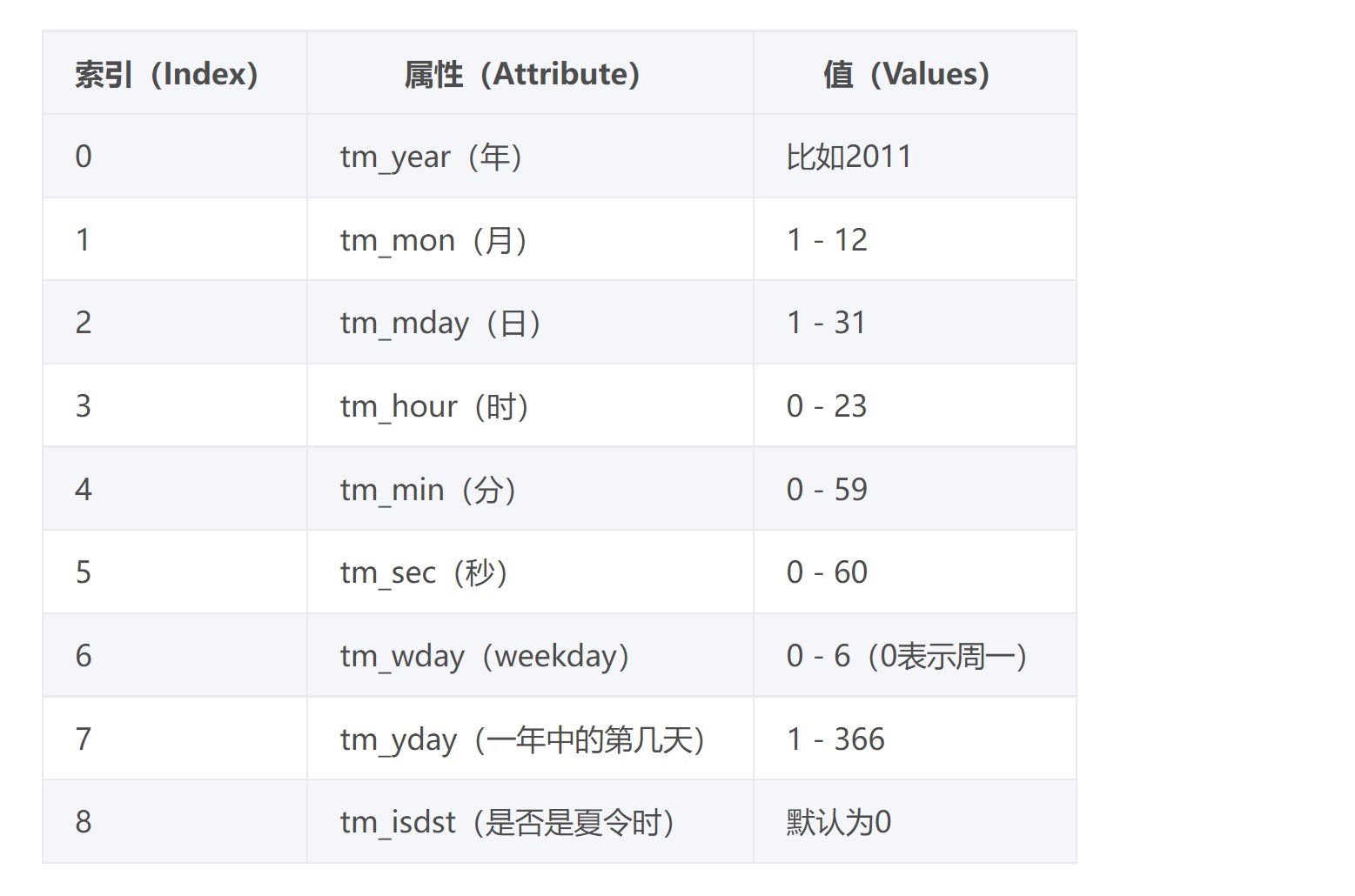
3.格式化时间
时间格式 2022-10-1 12:12:12
time.strftime()
'%Y-%m-%d %H:%M:%S' # 2022-10-1 12:12:12
'%Y-%m-%d %X' # 2022-10-1 12:12:12

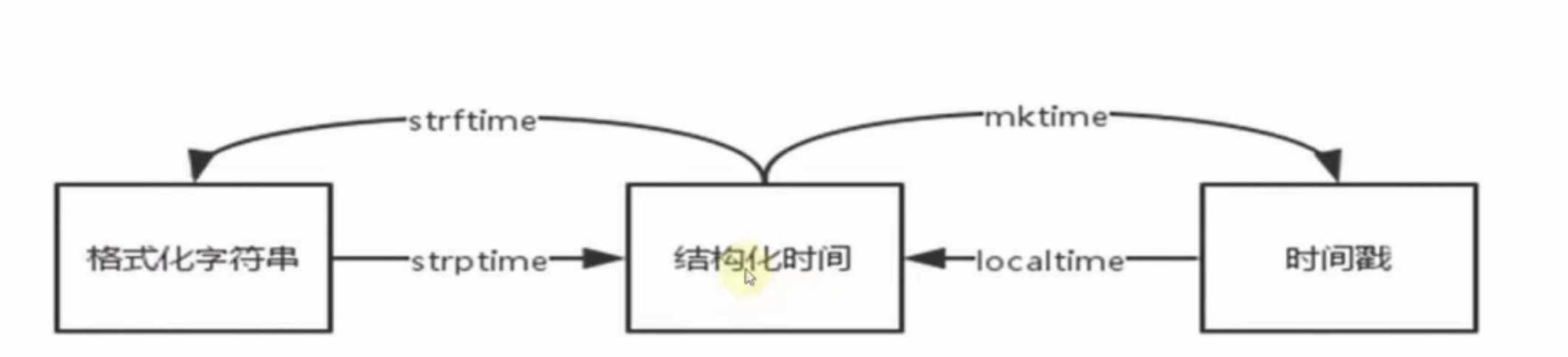
2.时间类型的转换
格式化时间 <==>结构化时间<==> 时间戳
# 时间戳<-->结构化时间
gmtime
localtime
# 结构化时间<-->格式化
strftime
strptime
time.strftime('2020-06-24')
time.strptime("2022/03","%Y/%m") 前后必须一致
ps:UTC时间比我们所在的区域时间早八个小时(时区划分)
3.datetime模块
# 调用模块
import datetime
print(datetime.date.today()) #2022-10-19
print(datetime.datetime.today()) #2022-10-19 19:08:27.356492
"""
date 获取的是年月日
datetime 获取到是年月日时分秒
"""
res = datetime.date.today()
print(res.year) #2022
print(res.month) # 10
print(res.day) # 19
print(res.weekday()) # 2 星期0-6
print(res.isoweekday()) # 3 星期1-7
"""
针对时间计算的公式
日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象
"""
ctime = datetime.date.today()
time_del = datetime.timedelta(days=3)
res = ctime + time_del
print(res - ctime)
# 3 days, 0:00:00
random模块
'''随机数模块'''
import random
print(random.random()) # 随机产生一个0到1之间的小数
print(random.uniform(2,4)) # 随机产生一个2到4之间的小数
print(random.randint(0,9)) # 随机产生一个0到9之间的整数(包含0和9)
print(random.randint(1,6)) # 掷骰子
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
random.shuffle(l) # 随机打乱一个数据集合
print(l)
l1 = ['特等奖','一等奖','二等奖','三等奖','优秀奖']
print(random.choice(l1)) # 随机抽取一个 抽奖
print(random.sample(ll, 2)) # 随机指定个数抽样
'''产生图片验证码: 每一位都可以是大写字母 小写字母 数字 4位'''
def get_code(n):
code = ''
for i in range(n):
# 1.先产生随机的大写字母 小写字母 数字
random_upper = chr(random.randint(65, 90))
random_lower = chr(random.randint(97, 122))
random_int = str(random.randint(0, 9))
# 2.随机三选一
temp = random.choice([random_upper, random_lower, random_int])
code += temp
return code
res = get_code(10)
print(res)
res = get_code(4)
print(res)
原文地址:http://www.cnblogs.com/super-xz/p/16807478.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性