
Hadoop集群安装配置教程
1.大数据环境配置统一
当Hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。这时,数据就可以分布到多个节点上,不同数据节点上的数据计算可以并行执行,这时的MapReduce分布式计算能力才能真正发挥作用。
为了降低分布式模式部署难度,本教程简单使用三个节点来搭建集群环境。
首先进行虚拟机克隆
1)使用VMware加载资料中虚拟机node1
2)克隆虚拟机,注意克隆虚拟机的时候,虚拟机必须是关闭状态
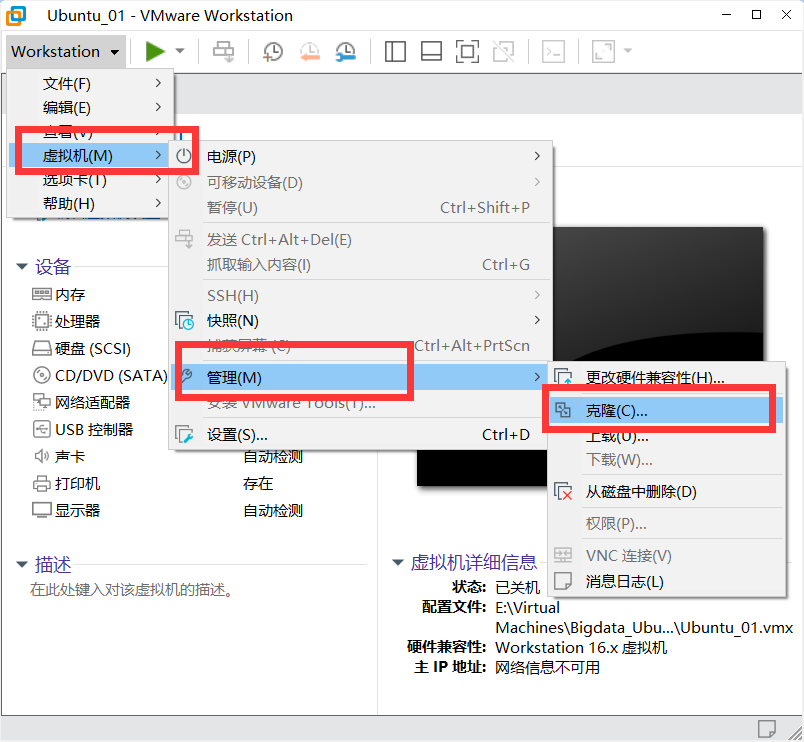
下一步

下一步

创建完整克隆
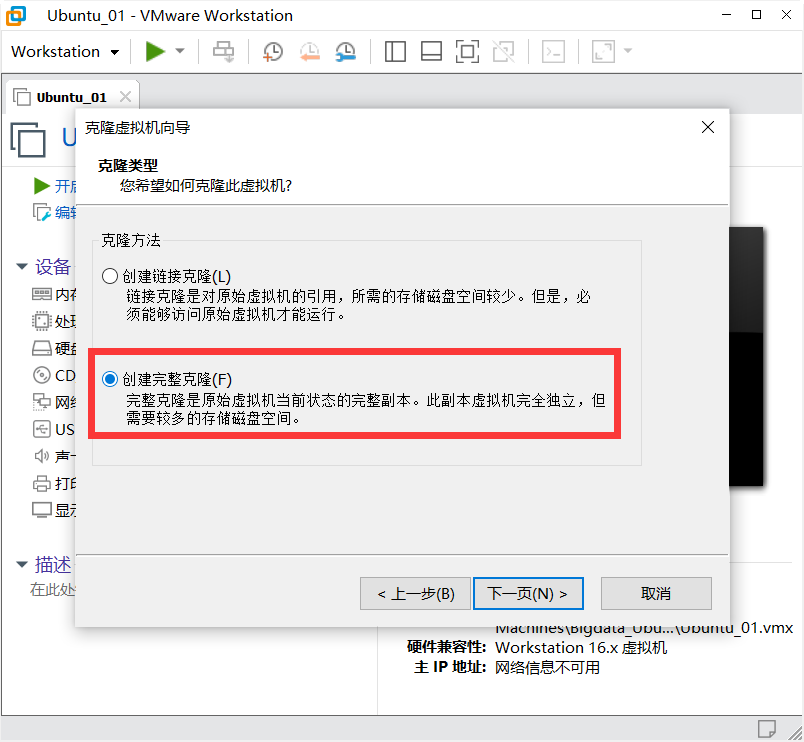
完成
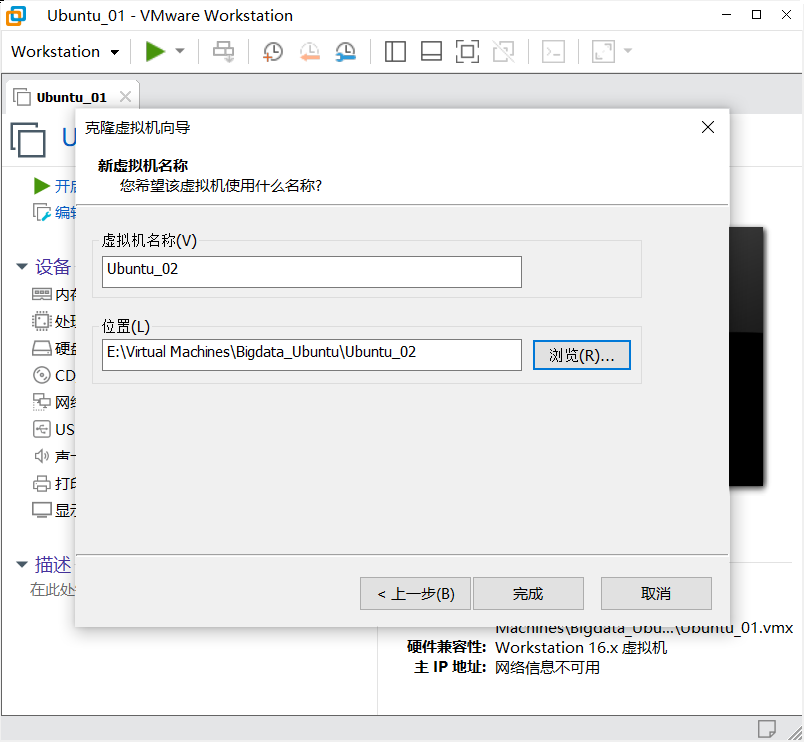
虚拟机三重复以上操作
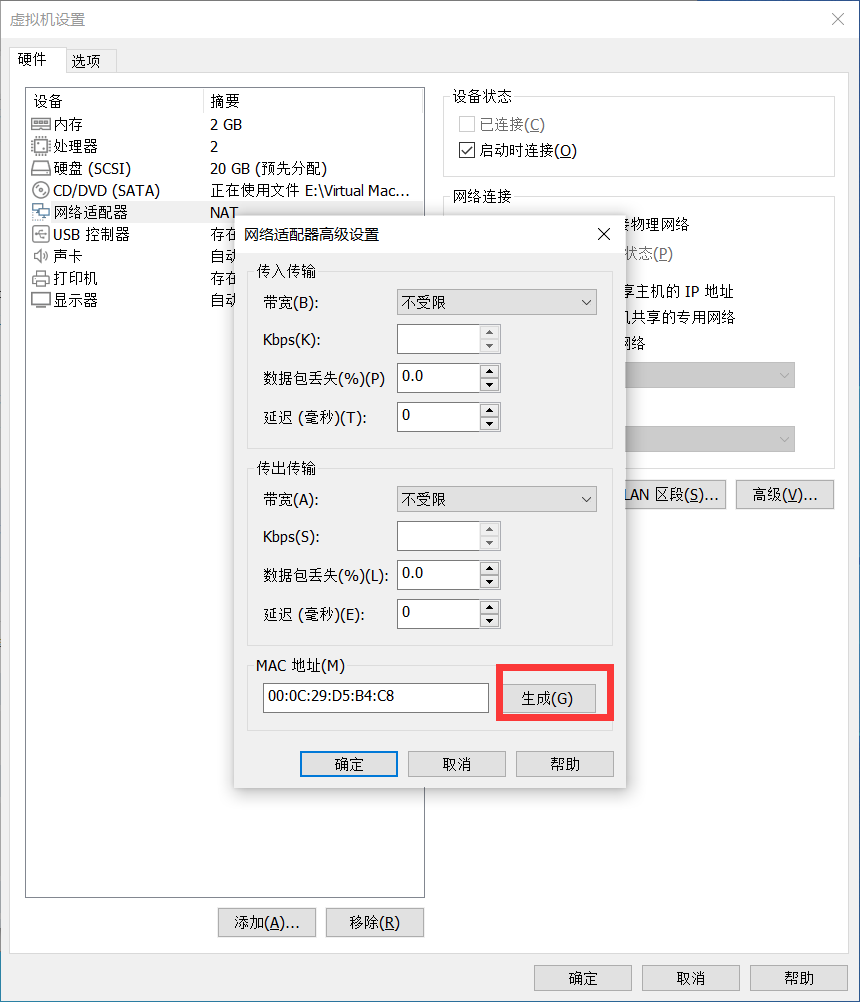
配置MAC地址
Slave1和Slave2都是从Master克隆过来的,他们的MAC地址都一样,所以需要让Slave1和Slave2重新生成MAC地址,生成方式如下:
生成新的MAC地址

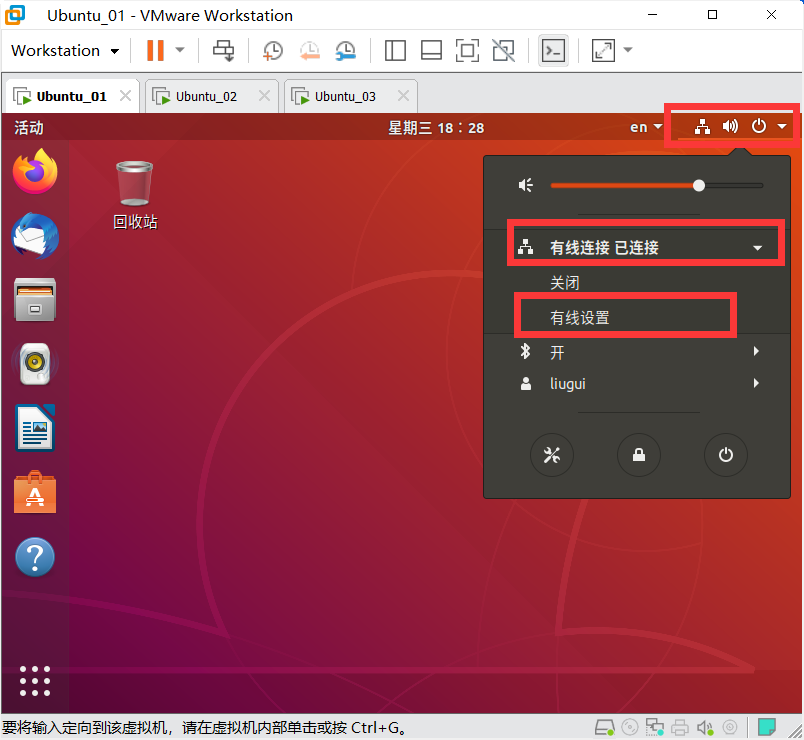
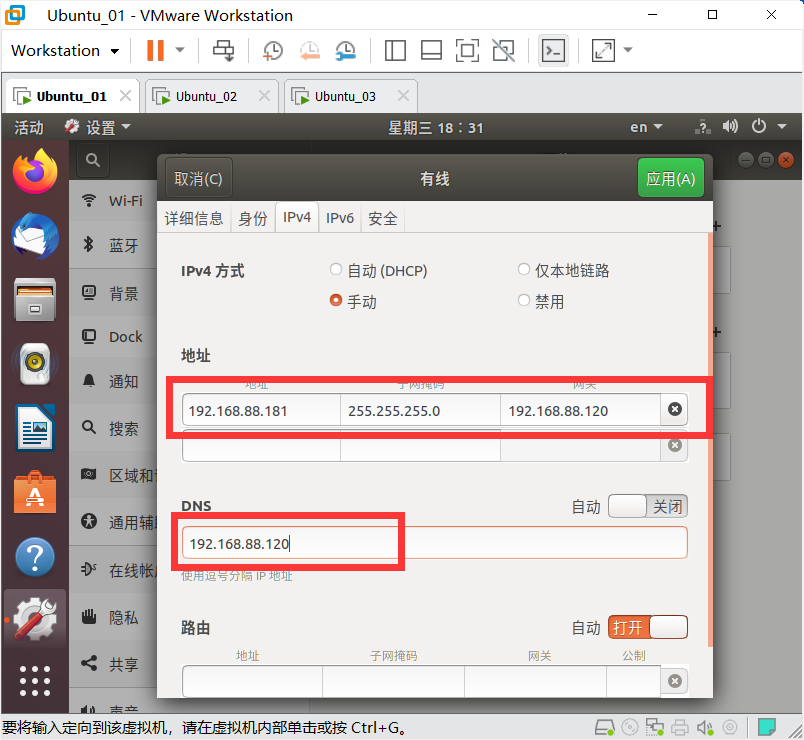
配置IP地址
设置静态网络
Master,IP地址为192.168.88.181
Slave1,IP地址为192.168.88.182
Slave2,IP地址为192.168.88.183

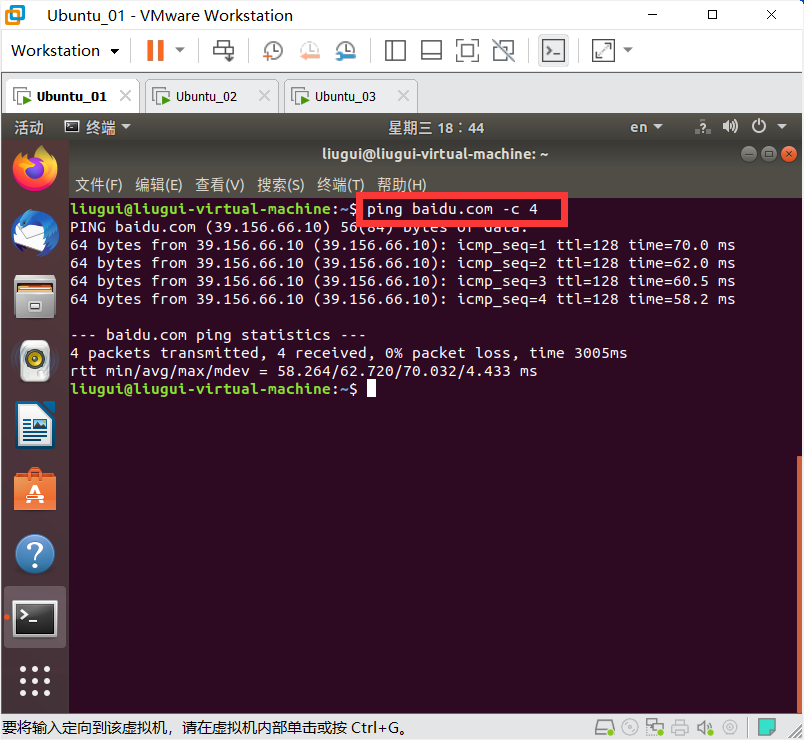
测试网络
ping baidu.com -c 4
原文地址:http://www.cnblogs.com/yuangyaa/p/16803626.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性