
cat userlist
任务
-
1.Linux文件系统的三层抽象是什么?
-
2.写出Cat userlist的过程,要详述目录文件,i-node.数据块,要画图示意。假设块大小为4k, userlist的大小不小于10k,自己假设大小。
1.Linux文件系统的三层抽象是什么
Linux文件系统的设计目的:就是用来存储文件和管理文件。Linux文件系统的文件是数据的集合,文件系统不仅包含着文件中的数据,而且还有文件系统的结构,Linux用户和应用程序看到的文件、目录、软连接及文件保护信息等都存储在其中。注意:操作系统是用来管理硬件和应用程序及其文件系统的,别弄混这个概念。接下来我们概略地说一下Linux文件系统的三层抽象。
第一层抽象——从磁盘到分区
- 分区可以看作磁盘,2个512G的磁盘与1T磁盘的两个分区在逻辑上等价。
第二层抽象——从磁盘到块序列
- 块数组与字节数组
第三层抽象——块数组到三个区域的划分
-
超级块:含文件系统信息。比如,超级块记录了每个区域的大小,超级块也存放未被使用的磁盘块的信息。
-
i-node:超级块的下一个部分。包含文件或目录的属性信息,每个文件都有一个i-node,i-node又固定的大小,构成一个i-node表。
i-node内容:
文件字节数
文件类型
文件权限
文件的User ID
文件的Group ID
文件在磁盘中的位置
文件的节点号
文件链接数
文件最后修改的时间
文件最后使用(读取或执行)的时间
文点自身最后改变的时间,如设置权限。
- 数据区:文件系统的第3个部分。包含文件内容和目录数据。文件的内容保存在这个区域。磁盘上所有块的大小都一样。如果文件包含了超过一个块的内容,则文件内容会存放在多个磁盘块中。
2.写出Cat userlist的过程,要详述目录文件,i-node.数据块,要画图示意。假设块大小为4k, userlist的大小不小于10k,自己假设大小
- linux中,文件查找不是通过文件名称来查找的。实际上是通过i节点来实现文件的查找定位的。我们可以形象的将i节点看做是一个指针fip。当文件存储到磁盘上去的时候,文件肯定会存放到一个磁盘位置上,可以这样想象,既然文件数据是存放在磁盘上的,如果我们知道这个文件数据的地址,当我们想要读写文件的时候,我们是不是直接使用这个地址去找到文件就可以了呢?是的,linux下,i节点其实就是可以这么认为,把i节点看作是一个指向磁盘上该文件存储区的地址。只不过这个地址我们一般是没办法直接使用的,而是通过文件名来间接使用的。事实上,i节点不仅包含了文件数据存储区的地址,还包含了很多信息,比如数据大小,等等文件信息。但是i节点是不保存文件名的。文件名是保存在一个目录项中。每一个目录项中都包含了文件名和i节点。
- 可以用下图表示这个过程:
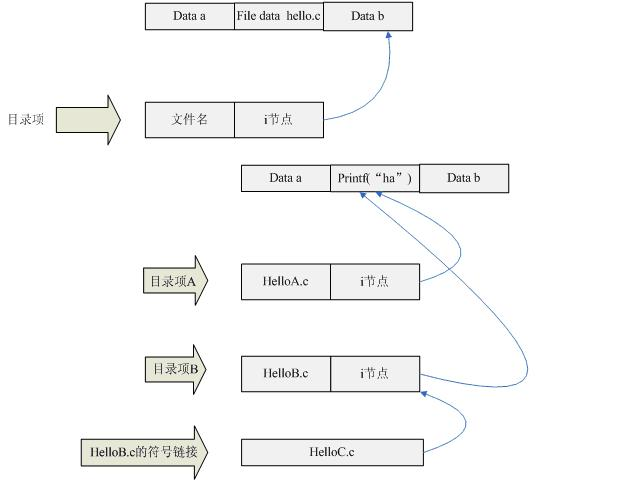
1.Cat userlist的过程
1. 打开,从目录找到userlist
2. 从dentry结构体读出innod
3. 从inode结构体读出i_block[]
4. 按顺序组织i_block[]中的内容,输出到终端
2.示意图

原文地址:http://www.cnblogs.com/wdys12138/p/16809021.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性