
爬虫 post请求:
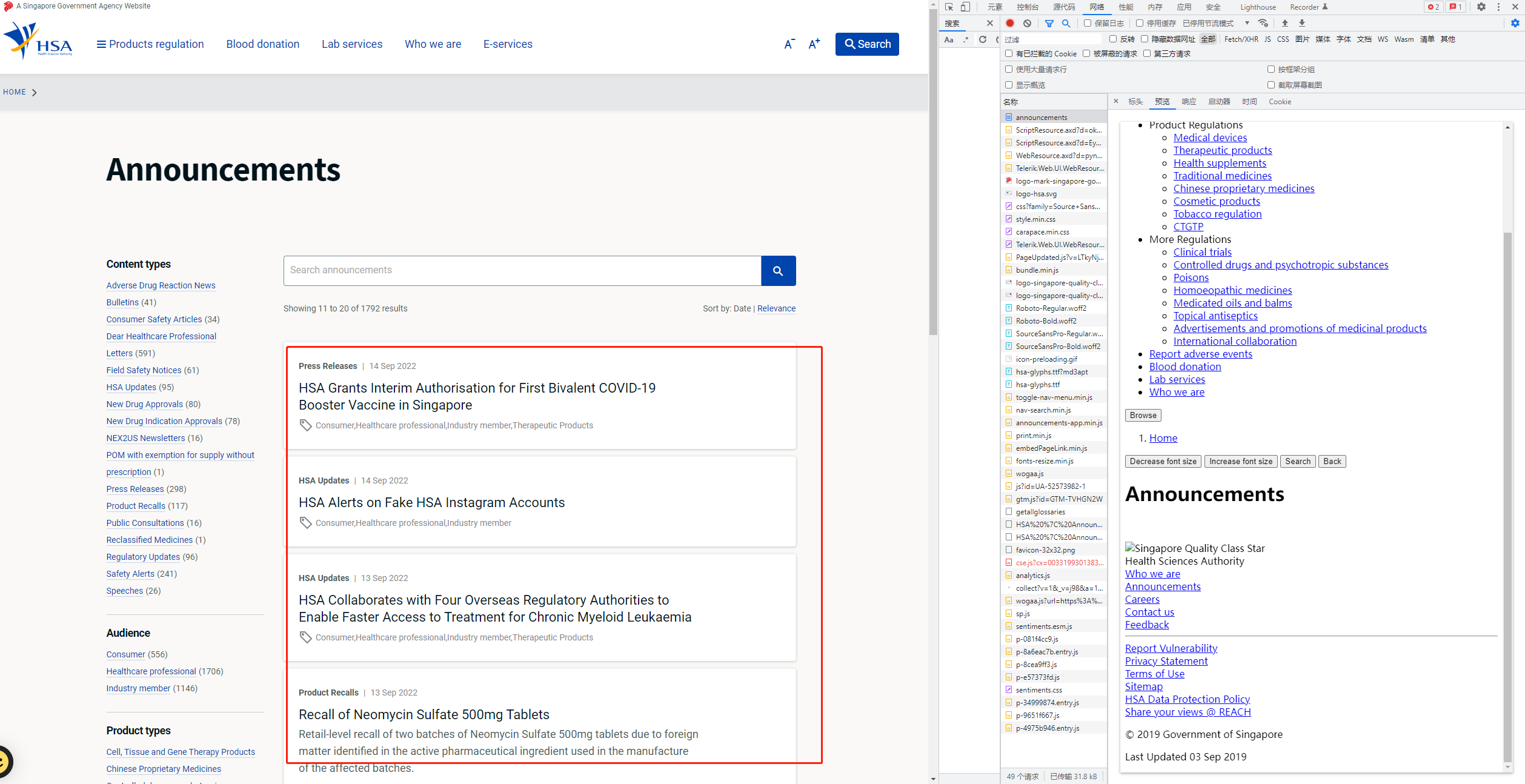
示例网站:如下图 ,要爬的资源不在html文件中,不可用xpath直接取
、
先把网络下面的信息清空,再点击页码 出现一下文件
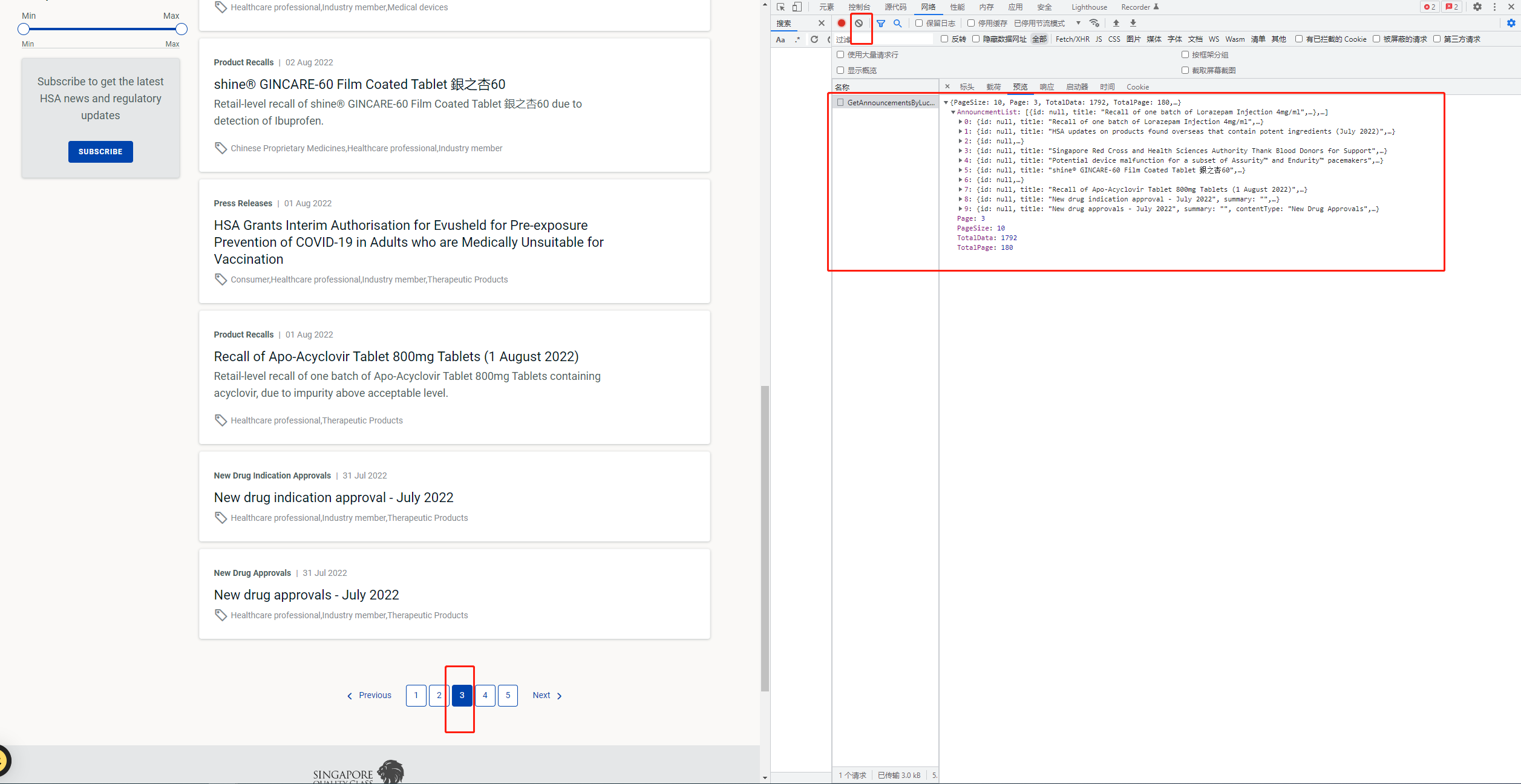
但是翻页过程中发现请求头的请求网址是不变的 ,请求方法是post
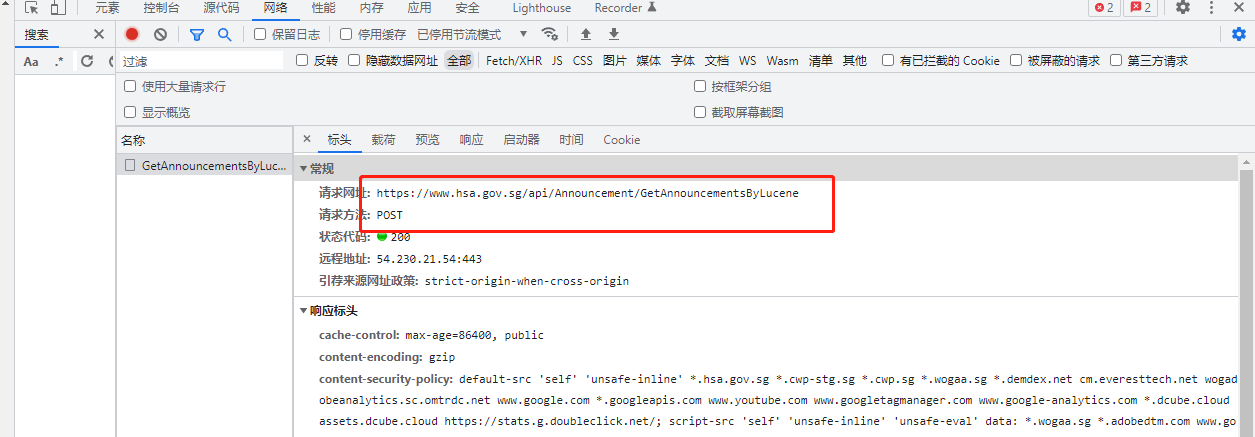
这时候就需要在post请求的data参数加上载荷,可以发现载荷里面有page这个参数,并且与我们翻页对应
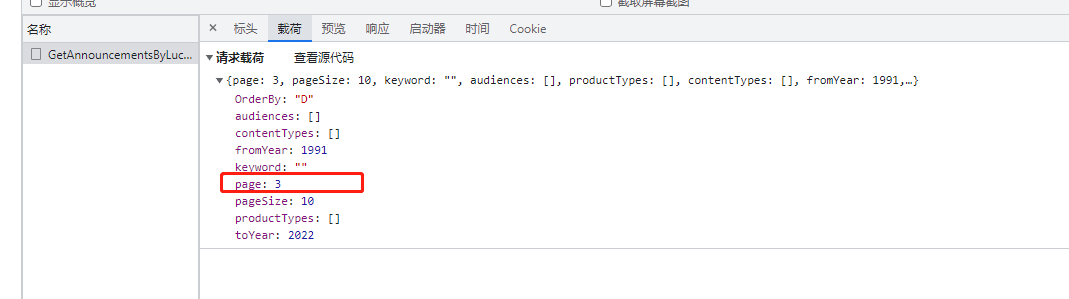
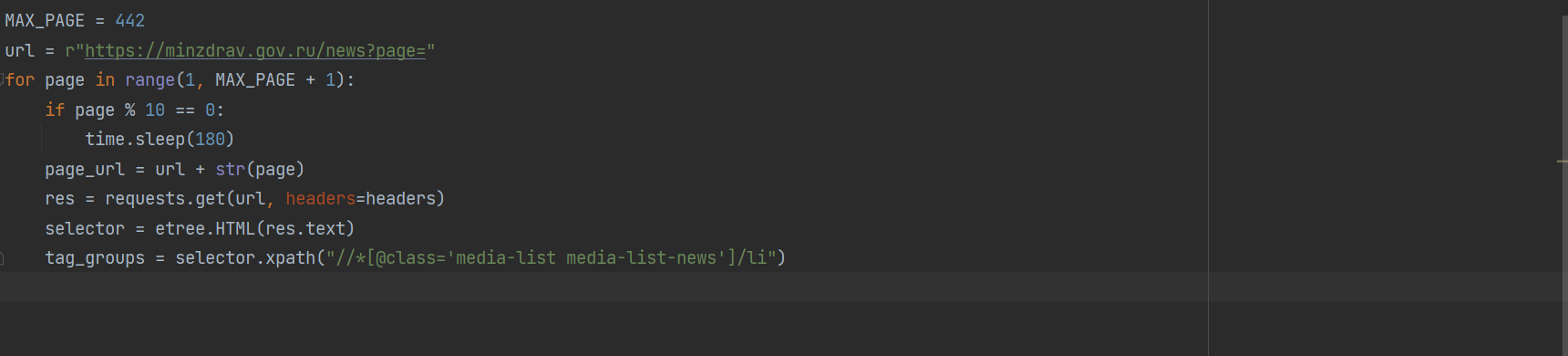
所以可通过如下脚本拿到响应信息,代码如下:
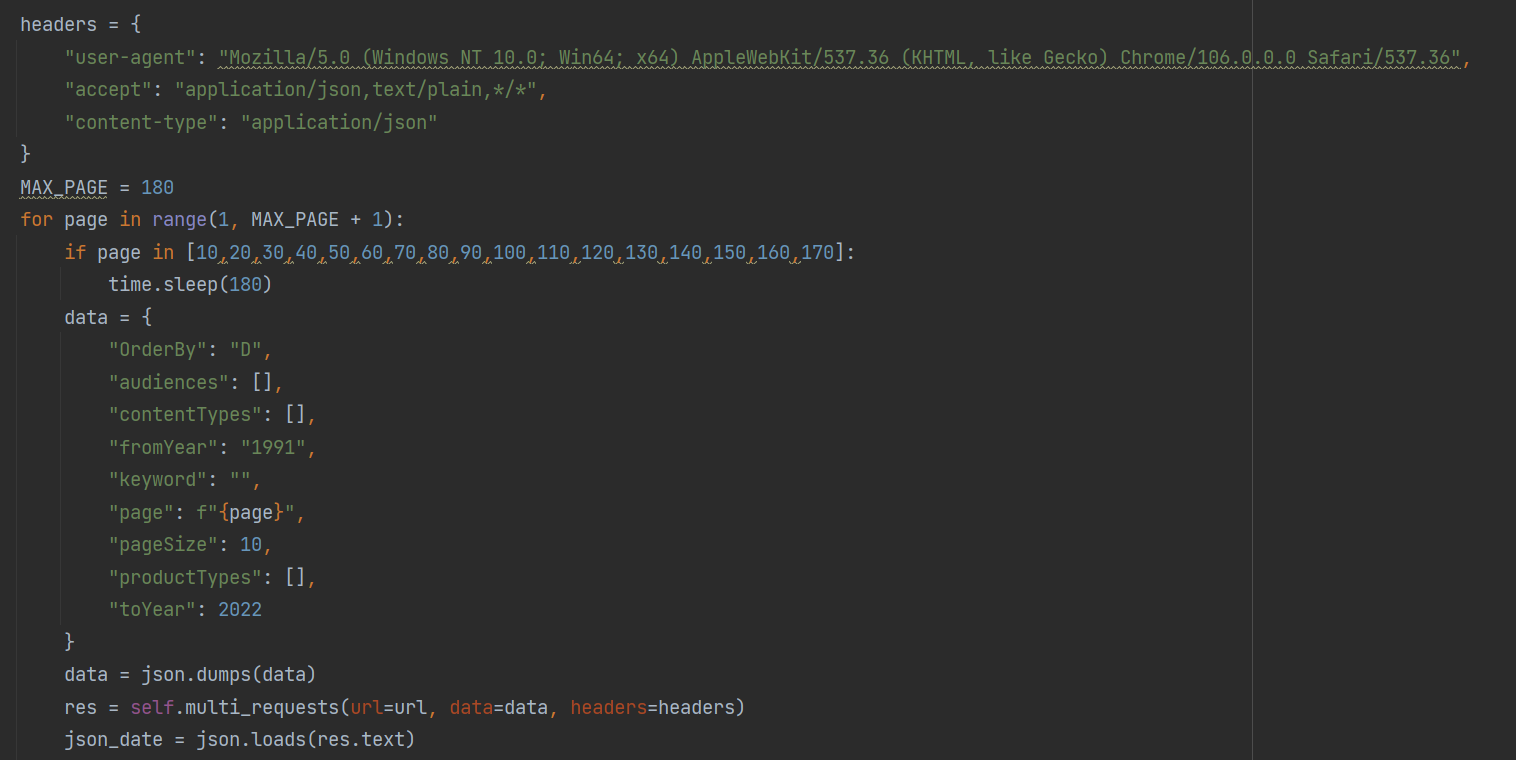
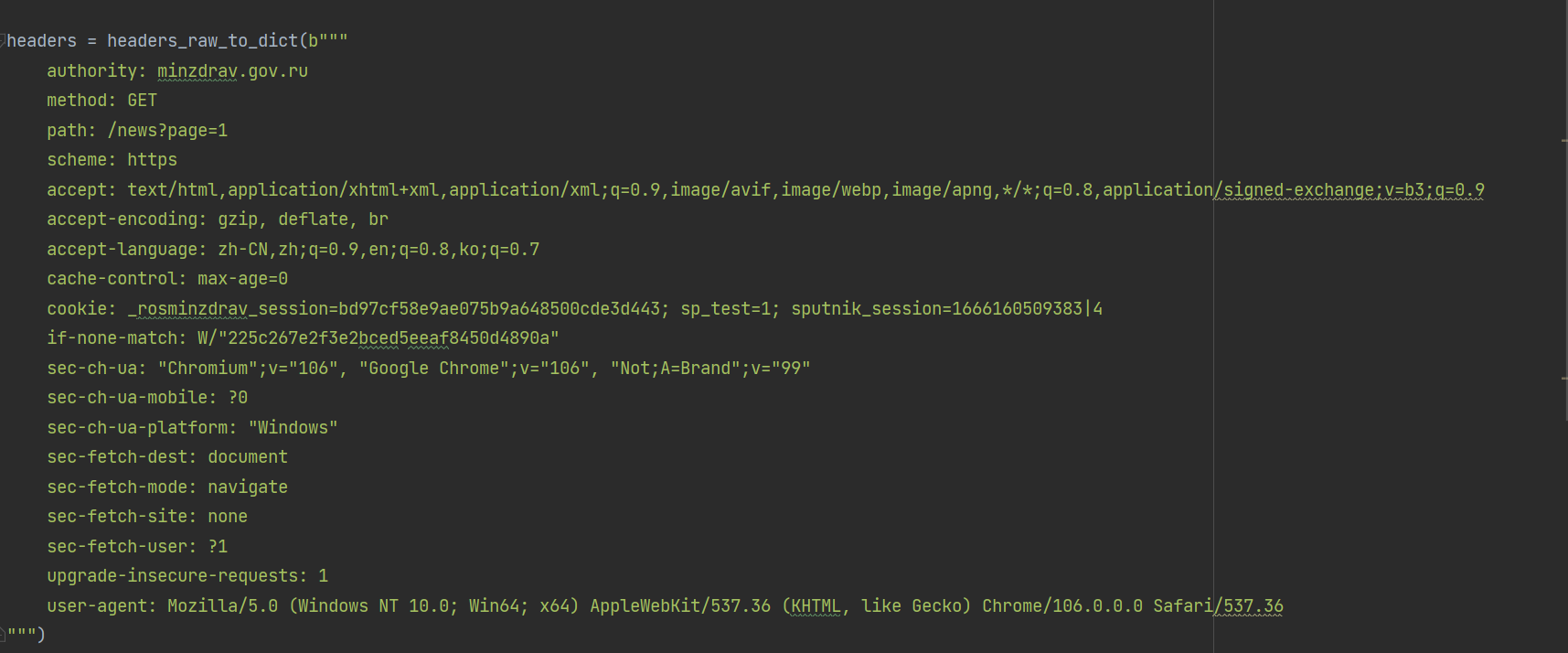
request请求添加headers的简单方法:
直接将浏览器的请求标头复制到引号之间
b"""
"""

原文地址:http://www.cnblogs.com/avivi/p/16809299.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性