
背景:
- 主要是研究在复杂的时间和空间扩展下的社会困境问题。现有的基于经济的无状态模型以及多智能体的强化学习都无法产生一个像人类一样在社会困境中合作的智能体,因此本文提及在这样的情况下促进将人类个体的对不公平厌恶特性应用于矩阵博弈社会困境问题中,并将其延伸至马尔科夫博弈问题中。
解决的问题:
* 在社会困境问题中,人类面对目前的短期利益的诱惑和集体合作的长期利益必须做出取舍,现有的基于理论的人会选择最有利选择的预测模型是不符合常理的,因为人有个体差异。但是在人类发展历程可以验证的是,人类一直能找到合适的取舍,因此需要为此提出一个合适的模型来解释这样的矛盾现象。现有的一些例如博弈论模型(仅适用矩阵博弈即两个玩家二元决策)或者说多智能体强化学习产生的合作都具有其局限性(在玩家多于2个时表现并不好)。
问题解决:
-
将不公平厌恶模型推广到马尔科夫博弈中,并通过实验证明其解决了跨期的社会困境问题。
-
区分不利的不公平厌恶(相对于其他人表现不佳的人获得的消极奖励)和有利的不公平厌恶(表现好的人或者可以说因为既得利益的背叛者获得的消极奖励)。两种不公平厌恶对应于间接和直接两种机制调整合作策略,直接机制中背叛者经历有利的不公平厌恶,间接机制中其他人对不公平的不利厌恶时就会惩罚背叛者。
-
同时文中提到不公平厌恶也改善了时间信用分配问题,由于短期行为和长期利益之间的联系是很难预见的,过程易出错。不公平厌恶相当于跨期社会困境中的”预警系统“,通过直接和间接两种机制缩短了长期信贷分配的需求。(大概意思是一个调和的过程,让大家尽量的产生合作为社会整体的长期利益服务)
论文主要工作
- 介绍了部分可观察马尔科夫博弈,智能体采用A3C算法进行训练,其中奖励分为了外在奖励即环境奖励反馈和内在奖励即不公平厌恶产生的回报。主要是清理游戏和收成游戏,并对其是跨期社会困境问题进行了验证。

-
后续问题将社会困境问题分为两大类:公共产品困境(需要付出成为公共资源)和公地困境对应上面的清理游戏和收成游戏
-
实验对比
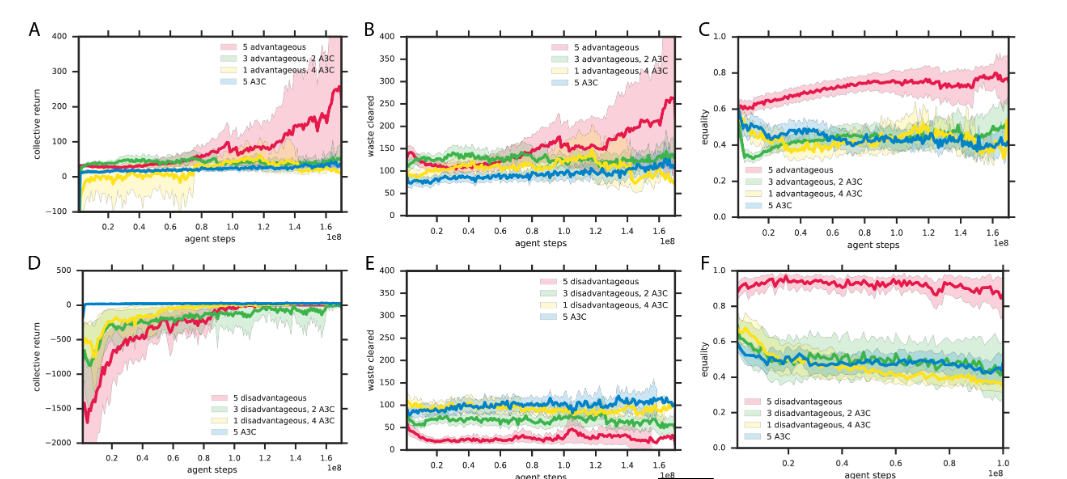
-
应用不公平厌恶的马尔科夫博弈模型
智能体的效用值可以表示为:

r代表的环境收益,后面的分别是不利的不公平厌恶负收益和有利的不公平厌恶收益
此模型下的延时回报的两个游戏收益实验结果
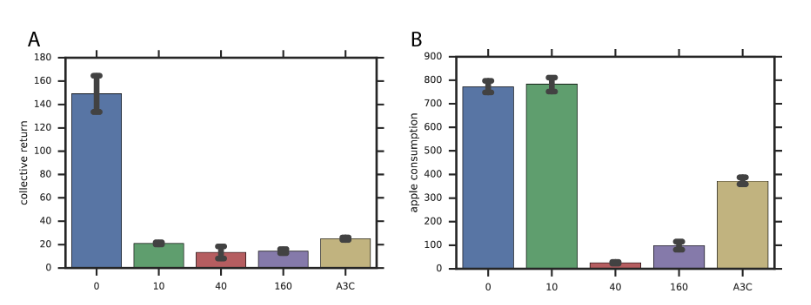
有状态的马尔科夫博弈模型应用不公平厌恶
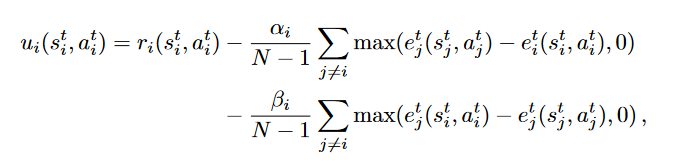
- 模型缺点:不公平厌恶应用是有局限性的,其中有利的不公平厌恶需要人群中大量存在这样的人。而不利的不公平厌恶则没有这种限制,因此更适用公地困境,但是有罪的代理人可能会被利用。基于此,人口的异质性是一个超参数导致模型不适用性。
原文地址:http://www.cnblogs.com/e557/p/16809463.html
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,请务用于商业用途!
3. 如果你也有好源码或者教程,可以到用户中心发布,分享有积分奖励和额外收入!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
7. 如遇到加密压缩包,默认解压密码为"gltf",如遇到无法解压的请联系管理员!
8. 因为资源和程序源码均为可复制品,所以不支持任何理由的退款兑现,请斟酌后支付下载
声明:如果标题没有注明"已测试"或者"测试可用"等字样的资源源码均未经过站长测试.特别注意没有标注的源码不保证任何可用性