
https://blog.csdn.net/weixin_40340586/article/details/119457955
记录一下自己的爬虫踩过的坑,上一次倒是写了一些,但是写得不够清楚,这次,写清楚爬取的过程。
这个网站是某省的志愿服务网。
就是它了。
我向爬取一些组织开展过的活动,比如这一个组织,
这个组织的页面找打它不存在什么问题,组织的网址只需要拼接就可以了。
看似很容易。
基础网址是:https://sd.zhiyuanyun.com/app/org/view.php?id=(*****)
前面是一堆,后面只需要把id后面的组织的ID放进去就可以,组织的ID也很好找。就是直接从首页一页页爬也行。这个网站的首页也不复杂。
但是现在我要得到这个组织开展的活动列表。
比如这个组织。
这个组织开展的活动蛮多的,看出来会有16页,最下面有标签,16.
难点是我怎么能知道最后一个页是16,就是最大的数, 有的组织只有1页,有的7,有的8.我得知道这个最末页的数,才能写一个循环。不能直接写一个while true 来一个break吧。
这时候,就需要研究一下这个网页的请求方式了。
这个网页请求使用的是post,而不是get。如果是get, 那么只能得到的页面是。
是这样一个页面,get请求的网址也是没错的。
https://sd.zhiyuanyun.com/app/org/view.php?id=TF86AlHTUWfd6
但是发起的项目这个部分,是看不到的。再仔细研究看看。其实在请求过程中,还有一个js请求。
刚开始我以为是xhr,即ajax,找了半天也没找到。
清空一下网络请求信息,点一下某一页的项目。就会看到一个post请求的
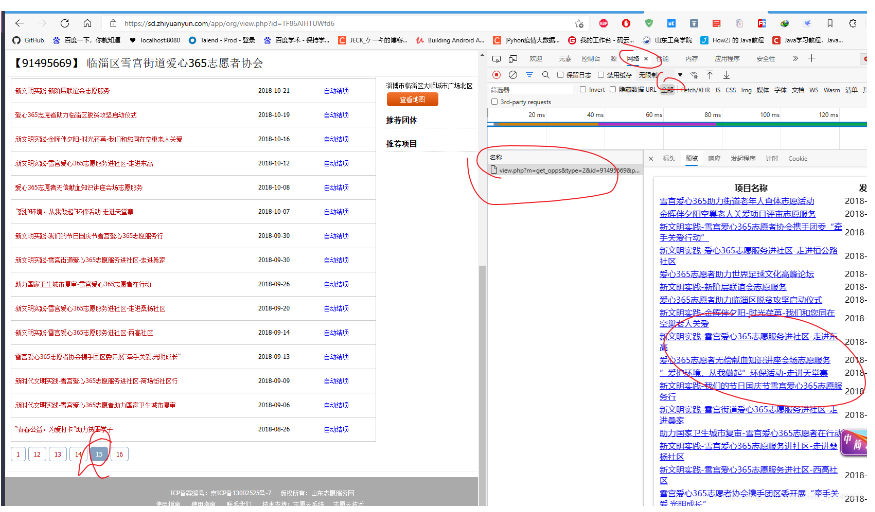
这个post请求,复制出来,注意是复制curl (bash)
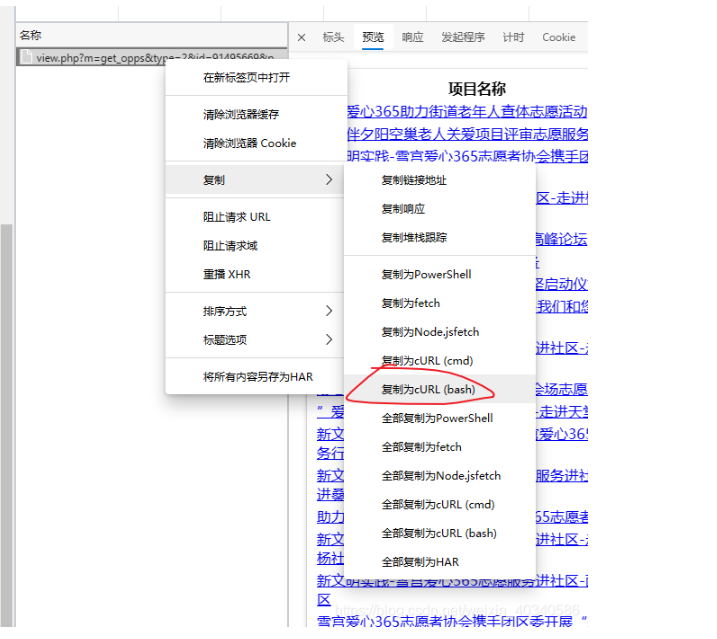
把这个贴进去 生成请求的网页,就可以得到python的请求代码。
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, and Rust code (trillworks.com)
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, and Rust code
https://curl.trillworks.com/
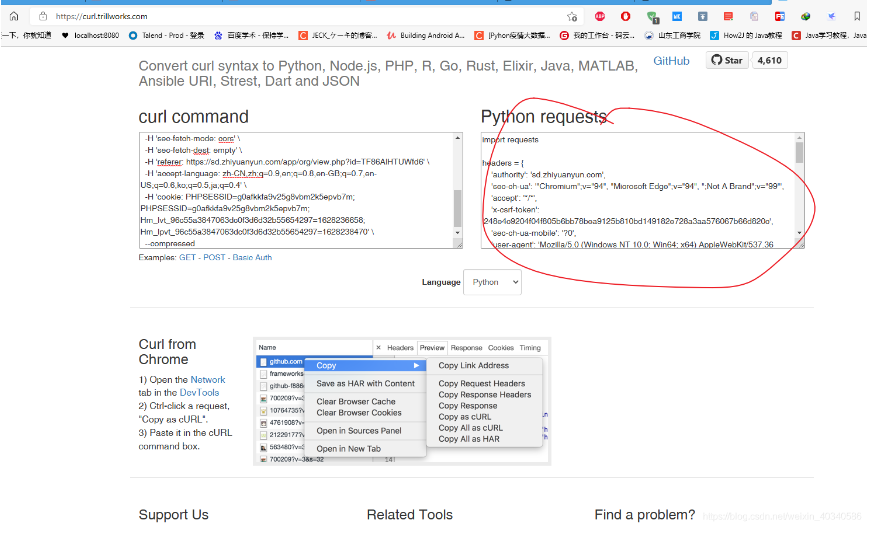
右侧的代码部分复制出来,放到pycharm里,
可以看到是这样的。
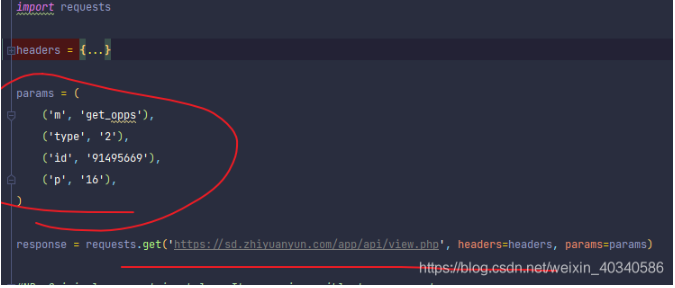
header部分省略了。重要是参数部分。
注意到这里的实际请求网址应该是这样的,每一个参数都是组合成 & 和= 号组合起来的。基础网址是横线上的。
https://sd.zhiyuanyun.com/app/api/view.php?m=get_opps&type=2&id=91495669&p=16
所以打开这个网址,就可以得到实际请求的网页。是这样的,一个简单的表单网页。结构很简单。
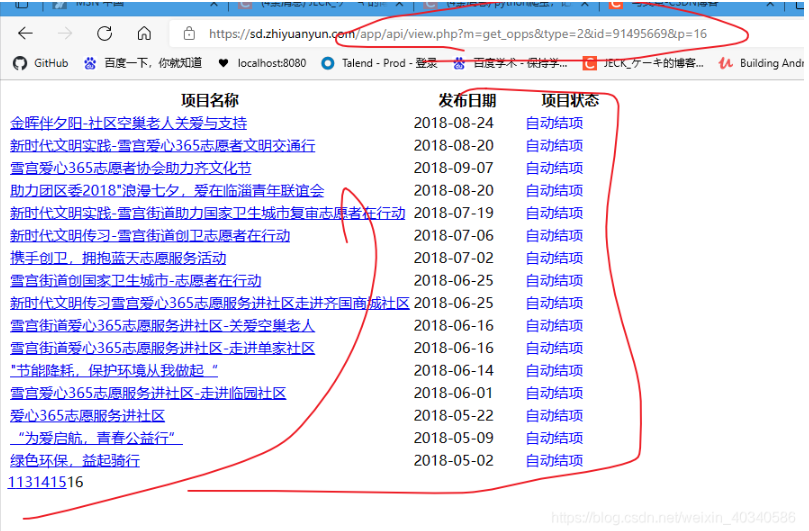
地址栏是我们拼接的网址,?后面是请求的参数,每一个参数的名和值用=链接,中间用&链接。
那么就得到了。
这是请求过程。
接下来是保存数据的过程。
对于这种表单,我一直觉得麻烦, 所以直接就是保存成列表,放入字典。
以后用的时候再拆开。
请求得到结果如图
得到的response实际上就是一个表单组成的网页。用selector解析一下。
from scrapy.selector import Selector
import requests
headers = {*********************}
params = (
(‘m’, ‘get_opps’),
(‘type’, ‘2’),
(‘id’, ‘91495669’),
(‘p’, ’16’),
)
response = requests.get(‘https://sd.zhiyuanyun.com/app/api/view.php’, headers=headers, params=params)
selector = Selector(response)
这时,我想要的就是表单里的信息,不想要表头,所以我用css选择器,选择从tr开始,tr里面,第一栏的tr是表头,所以不要表头,用
.table1 tr:nth-of-type(n+2)
这样的到下
tr = selector.css(“.table1 tr:nth-of-type(n+2)”)
for xi in tr:
a = xi.css(‘td a::text’).extract_first()
href = xi.css(‘td a::attr(href)’).extract_first()
print( a , href)
面的,然后再做一个遍历,就可以提取所有的项目名称和时间等信息。
这里我只想要的是 项目名和链接,打印出来可以看到,是这样的。
tr = selector.css(“.table1 tr:nth-of-type(n+2)”)
name_list = []
href_list = []
for xi in tr:
a = xi.css(‘td a::text’).extract_first()
href = xi.css(‘td a::attr(href)’).extract_first()
# print( a , href)
name_list.append(a)
href_list.append(href)
print(name_list, href_list)
dct_app = {}
dct_app.update(name = name_list, href = href_list)
dct_app
保存成字典,最后,就是把所有的组织都爬下来,这个是看愿意爬多少了。还有就是上面请求的参数部分,参数里的组织的链接是遗传字符,而请求组织的ID确实一串数字,这一串数字在每一个组织的名字前的方括号里,因此,这个信息也是必须的。
原文地址:http://www.cnblogs.com/chenwandong/p/16800649.html