
基于现在讲究即拿即用的快速迭代,得到商业价值的背景,提出了私有化部署的概念。用到现在主流的容器化部署。使用目前主流技术k8s,docker,minio,springboot,es,redis。
目的: 实现一键打包,移植即用,适用于各种中小型企业,节省公司资源与人力成本。
修订记录
|
5.10 |
初定版,书写大纲与部署基本信息 |
|
6.1 |
丰富细节(持续优化),请各位模块负责人审阅服务配置,后续若有修改,请自行申请权限编辑。 |
|
6.13 |
按照功能模块将组件的归属进行微调 |
一、产品介绍
PIE Engine AI平台针对数据、算法、算力问题,构建了一站式的遥感图像智能解译行业应用平台。提供从样本标注→模型训练→模型发布→解译应用→开放共享的一站式解决方案,专注为遥感领域提供生产工具链及服务,全面提升遥感的智能化服务能力。
二、适用人群
负责部署自主训练与智能解译平台的IT人员。
要求具有最基本的网络常识、Linux基本操作。
三、硬件配置
按照平台部署要求,准备一台win系统的电脑,作为部署操作的工作电脑,提供四台或者四台 以上的服务器,作为部署kubenetes集群部署的服务器,其中需要有gpu节点服务器,系统可以为centos等。
|
操作系统 |
数量 |
备注 |
|
windows |
1 |
工作台 |
|
CentOS 7.6 |
2 |
k8s部署服务器 |
|
CentOS 7.6 |
2 |
gpu调用节点,k8s部署服务器 |
服务器信息:
|
服务器IP |
hostname |
服务器配置 |
|
172.31.38.15 |
aimodel-node01 |
内存:64G,存储:100G+200TB的nfs |
|
172.31.1.105 |
aimodel-node02 |
内存:64G,存储:100G+200TB的nfs |
|
172.31.26.226 |
aimodel-gpu01 |
内存:16G,存储:250G+200TB的nfs,gpu:Tesla T4 |
|
172.31.25.140 |
aimodel-gpu02 |
内存:16G,存储:250G+200TB的nfs,gpu:Tesla T4 |
四、项目模块
分为以下9个板块进行处理,第9部分暂不涉及。
|
序号 |
服务 |
资料描述 |
负责人 |
|
1 |
基本环境搭建 |
centos、docker、k8s |
王锟 |
|
2 |
基础软件服务 |
harbor,minio,es,zookeeper,postgresql,redis |
王锟 |
|
3 |
基础管理服务 |
bpaas |
王锟 |
|
4 |
通用计算服务 |
提供消息队列,执行发起的调度任务 |
李佳燕 |
|
5 |
样本标注平台(西安部门暂未进行部署验证) |
用户上传样本,并进行审核。 |
李奋浩 |
|
6 |
算法相关镜像 |
深度学习镜像、后处理镜像 |
邓鹏 |
|
7 |
自主训练平台 |
用户根据现有的数据集,网络结构等进行训练,得到模型并保存到模型库。 |
赵风,王鑫晨,王拓 |
|
8 |
智能处理平台 |
利用现有的模型库对图片进行解译处理。 |
王鑫晨 |
|
9 |
模型发布平台(暂不涉及) |
现该服务仅提供给studio平台使用,客户无相关需求,暂不涉及该模块 |
五、部署步骤
1.基础环境搭建(所有机器)(王锟)
操作系统优化、k8s、docker环境搭建以及网关,用户中心等基础服务
1.1 系统优化
1.1.1 jdk11安装
1、删除之前开源的jdk
rpm -qa | grep java
rpm -e java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64 --nodeps
rpm -e java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64 --nodeps2、解压jdk的包
tar -xvf jdk-11.0.13_linux-x64_bin.tar.gz
mv jdk-11.0.13 /usr/local/.3、配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/local/jdk-11.0.13
export JRE_HOME=\$JAVA_HOME/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar4、验证
java -version1.1.2 关闭防火墙、SWAP、selinux(永久关闭)
1、防火墙永久关闭
systemctl stop firewalld
systemctl disable firewalld2、swap、selinux临时关闭,在系统分区的时候建议直接不为swap分区
swapoff -a
setenforce 03、selinux永久关闭
vim /etc/selinux/config
设置:SELINUX=disabled1.1.3 服务器命名以及更改hosts文件(根据现场环境实际情况)
hostnamectl set-hostname pie-1 服务器命名
vim /etc/hosts
192.168.30.181 pie-1
192.168.30.182 pie-2
192.168.30.183 pie-31.1.3 centos系统解除访问、打开文件限制
1、临时办法
ulimit -n 204800
2、永久办法
查看命令:
ulimit -n
ulimit -a
修改以下配置
vim /etc/security/limits.conf
* soft nofile 500000
* hard nofile 500000
* soft nproc 655350
* hard nproc unlimited
* soft memlock unlimited
* hard memlock unlimited
vim /etc/security/limits.d/20-nproc.conf
* soft nproc 655350
root soft nproc unlimited
vim /etc/security/limits.d/def.conf
* soft nofile 655350
* hard nofile 655350
重启系统后查看限制,若限制未放开,则继续一下步骤:
1. 确保 pam 生效
在 /etc/pam.d/login 中,存在:
session required pam_limits.so
2. 确保 ssh 使用 pam
在 /etc/pam.d/sshd 中,存在:
session required pam_limits.so
在 /etc/ssh/sshd_config 中, 存在:
UsePAM yes
再次重启系统后查看
1.2 docker
版本:18.09.9
镜像
操作步骤:
1.2.1 安装docker(在线)
1、前置插件安装
yum install -y yum-utils device-mapper-persistent-data lvm2
2、添加docker源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum makecache fast
yum list docker-ce --showduplicates #查看docker-ce的版本
3、安装docker18.09
yum install docker-ce-18.09.9 -y
systemctl start docker
systemctl enable docker1.2.2、安装docker(离线)
1、把docker-19.03的离线包导入到服务器
cd docker/.
2、安装
rpm -Uvh *.rpm --nodeps --force
systemctl start docker
systemctl enable docker1.2.3、修改docker配置(镜像仓库地址根据实际情况)
修改docker配置(镜像仓库"insecure-registries"地址根据harbor镜像仓库IP地址填写)
vim /etc/docker/daemon.json
{
"registry-mirrors": ["http://docker.mirrors.ustc.edu.cn","https://tnxkcso1.mirror.aliyuncs.com"],
"insecure-registries": ["172.31.1.105:8866"],
"log-driver":"json-file",
"log-opts":{ "max-size" :"50m","max-file":"1"}
}
systemctl daemon-reload
systemctl restart docker1.3 harbor
版本:v1.9.4_2
镜像
操作步骤:
1、docker-compose安装
1、在线安装
curl -L https://github.com/docker/compose/releases/download/1.26.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod a+x /usr/local/bin/docker-compose
2、离线安装
mv docker-compose /usr/local/bin/docker-compose
chmod a+x /usr/local/bin/docker-compose2、上传harbor安装包到node节点并解压
tar -xvf harbor-offline-installer-v1.9.4_2.tgz3、修改harbor.yml文件
hostname: 192.168.30.181 #更改主机名称
harbor_admin_password: 12345 #更改登录密码
data_volume: /data/pie_data/wuhan_pie_ai/data/harbor_data #仓库数据存放路径4、安装
安装
./prepare
./install.sh
docker-compose ps 查看运行状态
docker-compose restart 重启
docker-compose start 开启
docker-compose stop 停止
docker-compose up 更新
1.4 k8s集群安装
版本 1.19.10
镜像
操作步骤:
- 免密钥登录,master免密钥登录到其他虚拟机(master)
ssh-keygen #生成密钥
ssh-copy-id pie-2 #发送密钥
ssh-copy-id pie-3
ssh-copy-id pie-5
- 打开路由转发和桥接功能(所有机器)
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
echo net.ipv4.ip_forward = 1 >> /etc/sysctl.conf
sysctl -p /etc/sysctl.d/k8s.conf
sysctl -p
- 安装k8s-1.19.10(所有机器)
一、在线安装k8s-1.19.10
1、指定yum安装kubernetes的yum源(所有机器)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#发送到其他机器上面
scp kubernetes.repo pie-2:/etc/yum.repos.d/.
scp kubernetes.repo pie-3:/etc/yum.repos.d/.
scp kubernetes.repo pie-5:/etc/yum.repos.d/.
2、安装依赖包
yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp
3、安装k8s
yum -y install kubeadm-1.19.10 kubelet-1.19.10 kubectl-1.19.10
二、离线安装
cd k8s-1.19.10
rpm -Uvh *.rpm --nodeps --force
三、重置iptables(所有机器)
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat && iptables -P FORWARD ACCEPT
- kubectl 命令补全(所有机器)
echo "source <(kubectl completion bash)" >> ~/.bash_profile
source ~/.bash_profile
systemctl enable kubelet && systemctl start kubelet
systemctl daemon-reload
systemctl restart kubelet- k8s镜像导入(所有机器)
编辑下载脚本并运行
1、在线安装是通过编辑脚本下载镜像
vim image.sh
url=registry.aliyuncs.com/google_containers
version=v1.19.10
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
docker tag $url/$imagename k8s.gcr.io/$imagename
docker rmi -f $url/$imagename
done
chmod 775 image.sh
sh image.sh #运行脚本
docker images |grep k8s #查看镜像是否全部下载,共计7个,若差镜像,需要反复运行脚本
2、离线安装可以直接导入镜像
cd /k8s-images
#批量导入镜像
ll |awk '{print $NF}'|sed -r 's#(.*)#docker load -i \1#' |bash
- 初始化master(master安装)
mkdir -p /var/lib/kubelet/
cat > /var/lib/kubelet/config.yaml <<EOF
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
EOF
systemctl restart kubelet
#初始化安装
kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=v1.19.10
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
配置master认证
echo 'export KUBECONFIG=/etc/kubernetes/admin.conf' >> /etc/profile
source /etc/profile- 安装flannel网络(master安装)
cat >> /etc/hosts << EOF
151.101.108.133 raw.githubusercontent.com
EOF
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml
离线安装直接复制进去
kubectl apply -f kube-flannel.yml- node节点加入集群(在node上面操作)
master初始化后会提示加入节点信息,直接复制到node节点运行即刻,如下模板:
kubeadm join 192.168.30.181:6443 --token egly4n.0dhsxdmcvr4yl6o0 \
--discovery-token-ca-cert-hash sha256:714b6b7fa078a1fa9365dc36b5b7d892e0fa08e3a98d2d5bbb50405f47dae5ea- 添加Node标签
kubectl label node aimodel-node02 node-role.kubernetes.io/worker=worker
kubectl label node aimodel-gpu01 node-role.kubernetes.io/worker=worker
kubectl label node aimodel-gpu02 node-role.kubernetes.io/worker=worker
kubectl label nodes aimodel-node01 bpaas=true engine.node.ai=true
kubectl label nodes aimodel-node02 type=web bpaas=true engine.node.ai=true
kubectl label nodes aimodel-gpu01 engine.node.ai-gpu=true
kubectl label nodes aimodel-gpu02 engine.node.ai-gpu=true- kubectl get cs报错处处理以及优化
vim /etc/kubernetes/manifests/kube-scheduler.yaml
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
- --port=0
这行注释掉
systemctl restart kubelet.service
放开端口限制
vim /etc/kubernetes/manifests/kube-apiserver.yaml
找到这一行参数改为:1-65535,如果没有这一行直接新增这一行:
- --service-node-port-range=1-65535
kubectl delete pods -n kube-system kube-apiserver-pie-1
kubectl get pods -n kube-system- 新增node节点步骤(新建K8S集群24小时后,新的node 加入集群按以下步骤进行操作)
新建令牌(pie-1)
kubeadm token create
//t
获取 --discovery-token-ca-cert-hash 的值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
加入命令
kubeadm join 192.168.1.181:6443 --token gwwebb.0rj15um3f3v0w56h \
--discovery-token-ca-cert-hash sha256:714b6b7fa078a1fa9365dc36b5b7d892e0fa08e3a98d2d5bbb50405f47dae5ea- node节点使kubectl 命令修复
把master主机上面的adim.conf文件复制到node上面
scp /etc/kubernetes/admin.conf pie-2:/root/Downloads/.
scp /etc/kubernetes/admin.conf pie-3:/root/Downloads/.
scp /etc/kubernetes/admin.conf pie-5:/root/Downloads/.
scp /etc/kubernetes/admin.conf pie-6:/root/Downloads/.
在node上面
mkdir -p $HOME/.kube
cp -i /root/Downloads/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config- 将k8s集群使用授权延期到10年(默认是1年)
在master节点上将脚本update_cert_10year.sh、update-kubeadm-cert.sh导入到/root/Downloads下,直接运行sh update_cert_10year.sh。- 其他配置项
master当node使用
kubectl taint node --all node-role.kubernetes.io/master-
取消
kubectl taint node --all node-role.kubernetes.io/master="":NoSchedule
清楚之前的flannel
sudo rm -rf /var/lib/cni/flannel/* && sudo rm -rf /var/lib/cni/networks/cbr0/* && sudo ip link delete cni0
sudo rm -rf /var/lib/cni/networks/cni0/*
清理服务器所有docker 缓存
docker system prune -a
1.5.k8s调用gpu
- 前置条件
节点需要使用 NVIDIA 的 GPU 资源的话,需要先安装 k8s-device-plugin 这个插件,并且需要事先满足下面的条件:
1.Kubernetes 的节点必须预先安装了 NVIDIA 驱动
2.Kubernetes 的节点必须预先安装 nvidia-docker2.0
3.Docker 的默认运行时必须设置为 nvidia-container-runtime,而不是 runc
4.NVIDIA 驱动版本大于或者等于 384.81 版本
- 安装英伟达驱动和cuda
[ec2-user@aimodel-gpu01 ~]$ lspci -nn | grep NV
00:1e.0 3D controller [0302]: NVIDIA Corporation TU104GL [Tesla T4] [10de:1eb8] (rev a1)
00:1f.0 Non-Volatile memory controller [0108]: Amazon.com, Inc. NVMe SSD Controller [1d0f:cd01]
本gpu节点已安装英伟达驱动和cuda
[ec2-user@aimodel-gpu01 ~]$ nvidia-smi
Tue May 24 06:20:26 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 |
| N/A 37C P8 15W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
英伟达驱动在线和离线安装(以centos7.6为例)
#NVIDIA驱动需要GCC等C/C++开发环境,首先检测GCC是否已经安装
gcc –v
# 如果系统显示没有找到GCC指令,或没有显示GCC版本信息,则需要安装C/C++环境
yum -y install gcc gcc-c++ kernel-devel kernel-headers //安装gcc、c++编译器以及内核文件(在线)
rpm -ivn *.rpm --force --nodeps //提前把gcc等rpm包下载好放到统一的一个文件夹中,运行命令(离线)
# 查看kernel-devel版本
rpm -qa | grep kernel-devel下载英伟达驱动安装包
#先查出英伟达显卡型号
[ec2-user@aimodel-gpu01 ~]$ lspci -nn | grep NV
00:1e.0 3D controller [0302]: NVIDIA Corporation TU104GL [Tesla T4] [10de:1eb8] (rev a1)
00:1f.0 Non-Volatile memory controller [0108]: Amazon.com, Inc. NVMe SSD Controller [1d0f:cd01]根据显卡型号去官网进行下载
https://www.nvidia.cn/Download/index.aspx?lang=cn#
禁用Nouveau驱动
sudo vim /usr/lib/modprobe.d/dist-blacklist.conf
# 添加下列两行
blacklist nouveau
options nouveau modeset=0
# 重新生成 kernel initramfs
dracut --force
# 重启,启动后执行
lsmod |grep nouveauGPU驱动需要在命令行下安装:
#进入命令行模式:
systemctl set-default multi-user.target
#重启
reboot
# 重启后验证驱动是否被禁用 如果无结果显示则表明成功禁用
lsmod | grep nouveau
安装下载的英伟达驱动
# 将下好的驱动放入U盘中
NVIDIA-Linux-x86_64-390.87.run
# 利用moun挂载到根下的media下
mount /dev/sdb4 /media
# 给所有人加上可执行权限
chmod a+x NVIDIA-Linux-x86_64-390.87.run
# 执行命令 -no-opengl-files:表示只安装驱动文件,不安装OpenGL文件,这个参数不可省略否则会导致登录界面死循环
./NVIDIA-Linux-x86_64-390.87.run -no-opengl-files提示是否安装32位驱动选NO
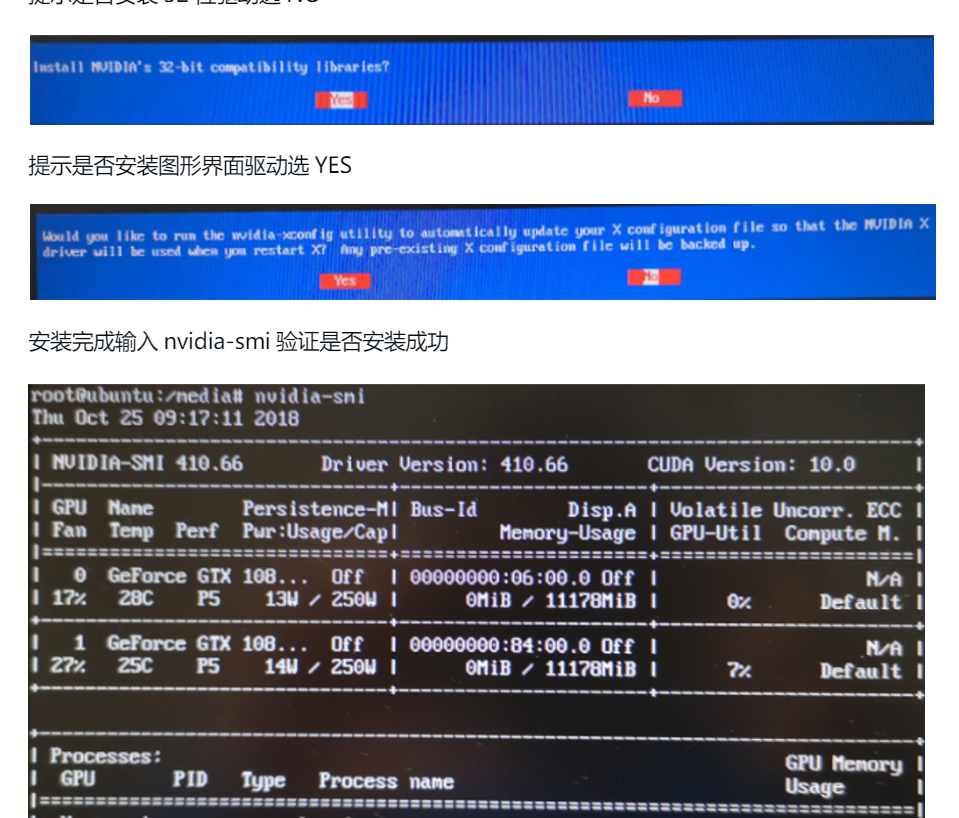
再次使用命令切换回图形界面
systemctl set-default graphical.target
- nvidia-docker2.0(在线和离线)
官网安装指导https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
Docker >= 19.03(建议,但某些发行版可能包含 Docker 的较旧版本。支持的最低版本为 1.12)
#设置存储库和 GPG 密钥:(在线)
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
#要访问experimental功能和访问候选版本,您可能需要将experimental分支添加到存储库列表中:(在线)
yum-config-manager --enable libnvidia-container-experimental
#更新包列表后安装nvidia-docker2包(和依赖项)(在线)
sudo yum clean expire-cache
sudo yum install -y nvidia-docker2
#使用rpm命令安装预先下载好的nvidia-docker2的rpm包(离线)
rpm -ivn *.rpm --force --nodeps
修改docker的运行配置
vim /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
修改完成后reload配置文件
sudo systemctl daemon-reload
设置默认运行时后重启 Docker 守护进程完成安装
sudo systemctl restart docker
- 在K8S中安装 k8s-device-plugin插件
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.10.0/nvidia-device-plugin.yml- 安装成功检查gpu节点具体信息
查看节点具体信息 能看到gpu资源已经加入到节点
[ec2-user@aimodel-gpu02 ~]$ kubectl describe nodes aimodel-gpu02
Addresses:
InternalIP: 172.31.25.140
Hostname: aimodel-gpu02
Capacity:
cpu: 4
ephemeral-storage: 157274092Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 16122196Ki
nvidia.com/gpu: 1
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 144943802948
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 16019796Ki
nvidia.com/gpu: 1
pods: 110
2.基础软件服务
依赖的运行的基本配置
2.1 minio
版本 latest
镜像 minio/minio:latest
操作步骤:
vim minio.sh
docker run -di -p 9000:9000 -p 9001:9001 --name minio-ai \
--restart=always \
-e "MINIO_ACCESS_KEY=admin" \
-e "MINIO_SECRET_KEY=Piesat123" \
-v /data/pie_data/wuhan_pie_ai/data/minio/data:/data \
-v /data/pie_data/wuhan_pie_ai/data/minio/config:/root/.minio \
-v /etc/localtime:/etc/localtime \
minio/minio:latest server /data --console-address ":9001"
sh mini.sh部署成功后,在minio上新建桶pie-engine-ai(权限:默认为PUBLIC),将devel文件夹所有内容拷贝到该桶下。
devel文件中的信息为网络结构与模型存储。
拷贝成功后展示如下:
2.2 zookeeper
版本 3.8.0-debian-10-r37
镜像 bitnami/zookeeper:3.8.0-debian-10-r37
操作步骤
一、在线安装(不建议使用,除非在其他方式均无法部署成功的情况下)
安装helm工具
wget https://get.helm.sh/helm-v3.8.0-linux-amd64.tar.gz
tar -xvf helm-v3.8.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
创建共享存储
helm repo add stable https://charts.helm.sh/stable
helm repo update
helm install nfs-client-zk --set nfs.server=172.31.38.15 --set nfs.path=/home/ec2-user/opt/data/pv/zk01 stable/nfs-client-provisioner
安装zookeeper
#添加仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo add ali-incubator https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/
helm repo update
#拉取镜像
helm pull bitnami/zookeeper
#安装ZK
helm install zookeeper -n tools --set replicaCount=3 --set auth.enabled=false --set allowAnonymousLogin=true /home/ec2-user/opt/tools/zookeeper/zk03/zookeeper
二、离线安装
1、准备好zookeeper镜像zookeeper:3.4.10和yaml文件
2、确定pv挂载的方式,nfs或者hostPath(如果有共享存储建议用hostPath,挂到共享存储上;没有共享存储,建议自己搭建nfs,用nfs的方式)
cd zookeeper
kubectl create -f .
2.3 postsql
post与gis合成的镜像(post数据库与gis插件的组合)
docker pull postgis/postgis:12-3.2
版本:
镜像
操作步骤:
1、新建启动脚本
vim postgres_run.sh
docker run --name postgres-ai \
-e ALLOW_IP_RANGE=0.0.0.0/0 \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=12345 \
-p 54321:5432 \
-v /data/pie_data/wuhan_pie_ai/data/pggissql:/var/lib/postgresql/data \
--restart=always \
-d postgis/postgis:12-3.2
2、运行脚本
sh postgres_run.sh
3、恢复数据库
docker cp sql postgres-ai:/tmp/.
docker exec -it postgres-ai /bin/bash
#恢复数据
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/create_table_shp.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/create_tables_public.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_dev_dataset_mix.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_dev_dict.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_dev_framework.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_dev_model.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_dev_network.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_dev_product.sql
psql -h 127.0.0.1 -U postgres -d pie-engine-ai < /tmp/sql/init_post_process_tools.sql
验证结果:
新建数据库,pie-engine-ai,在当前数据库下进行gis插件的安装。
create extension postgis;
select postgis_full_version();

说明:
1.创建表:create_tables_public.sql, create_table_shp.sql建表的脚本
2.初始化数据:init_dev_dict为字典表,init_dev_network,init_dev_product无需修改,前提需拷贝网络结构到相应的minio存储对象中。桶为pie-engine-ai。
3.初始化数据:init_dev_framework,init_post_process_tools ,并修改image私有镜像仓库Harbor的url
4.init_dev_datsset_mix,init_dev_model为测试验证的数据。根据实际情况修改。
例
注意事项:
当镜像都上传到harhor上的后,才能修改dev_framework,post_process_tools ,镜像字段为私有镜像仓库地址为Harbor的url。
2.4 es
版本 7.7.0
镜像 elasticsearch:7.7.0
操作步骤
一、docker下部署
编辑启动脚本 vim es.sh
#启动镜像
docker run --name elasticsearch -d -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e "discovery.type=single-node" --restart=always -p 9200:9200 -p 9300:9300 elasticsearch:7.7.0
#--name表示镜像启动后的容器名称
#-d: 后台运行容器,并返回容器ID;
#-e: 指定容器内的环境变量
#-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
sh es.sh
二、k8s下部署
1、准备好es镜像和yaml文件
2、确定pv挂载的方式,nfs或者hostPath(如果有共享存储建议用hostPath,挂到共享存储上;没有共享存储,建议自己搭建nfs,用nfs的方式)
cd es
kubectl create -f .
2.5 redis
版本 5.0.7
镜像 172.31.38.15:886/tools/redis:5.0.7
操作步骤
将redis-configmaps.yaml、redis-deploy.yaml、statefulset-redis.yaml文件放入到redis目录中
cd redis
kubectl create -f .2.6 nfs(选装)
前提:取决于客户是否已有存储服务器
1、准备好nfs安装rpm文件
cd nfs
rpm -Uvh *.rpm --nodeps --force
2、开启服务
systemctl start nfs rpcbind
systemctl enable nfs rpcbind
3、server端设置共享目录
vim /etc/exports
/data/Product *(insecure,rw,sync,no_root_squash)
systemctl restart nfs rpcbind
4、查看共享目录
showmount -e
3 bpaas
版本
镜像
操作步骤
1、准备中间依赖
(1)Redis-5.0.7
(2)Zookeeper-3.4.14
(3)MySQL-5.7.19
2、mysql安装
docker run -d -p 3306:3306 -v /var/local/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345 --restart=always --name mysql mysql:5.7.19
3、创建NameSpace
命令:kubectl label node {node} bpaas=true
4、导入基础镜像
docker load < jre1.8-go-font.tar
docker load < jre1.8-go.tar
更改镜像名称并上传至镜像仓库
docker tag
docker push 172.31.1.105:886/base/jre1.8-go:latest
5、导入数据库
先创建数据库再导入数据库
6、在每个功能文件夹的配置文件中更换zk、redis、mysql的地址
配置文件均在config 目录下
7、更换所有install.sh、Dockerfile、yaml文件的镜像仓库地址
*批量更换IP地址可以用批量更换的命令如下:
sed -i "s/192.168.30.181/172.31.38.15/g" `grep 192.168.30.181 -rl pie-engine-bpaas`
sed -i "s/172.31.38.15:886/172.31.1.105:886/g" `grep 172.31.38.15:886 -rl pie-engine-bpaas`
8、运行脚本开启服务
pie-engine-bpaas目录下自定义了2个脚本分别是:01restart_all.sh、02install_all.sh
01restart_all.sh #重启所有
02install_all.sh #重新安装
9、前端文件要放在配置文件指定的目录
IP:30801 网关
IP:30810 网关访问地址
IP:30830 sso地址
10、前端文件更改
sso目录和sso/sso目录下的app-config.js 中的"domain"和"rootUrl" 要改为当前的网关IP地址
janus-console目录下的index.html中的"domain"和"gatewayurl"要改为当前的网关IP地址
3.1数据库备份文件-供网关使用-验证完成之后统一备份脚本文件
注:可以研究是否按照服务分表进行存储-王健波
4.计算服务
描述:计算任务服务部署说明
4.1 版本信息
- Kubernetes(v1.19)
- Etcd(3.4.3)
- RabbitMQ(3.7)
4.2 初始化
4.2.1 命名空间
默认服务部署命名空间:pie-engine-computing
默认任务调度命名空间:pie-engine-job
kubectl create ns pie-engine-computing
kubectl create ns pie-engine-job4.2.2 节点标签
etcd节点标签
kubectl label nodes NodeNamecomputing.piesat.cn/system.kvstore=
rabbtimq节点标签
kubectl label nodes NodeName computing.piesat.cn/system.messagebus=
compute-hub服务节点标签
kubectl label nodes NodeNamecomputing.piesat.cn/service=
任务调度节点标签
kubectl label nodes NodeName computing.piesat.cn/jobs=
GPU节点标签
kubectl label nodes NodeName gpu_name=NVIDIA-T4-Tensor-Core-GPU
4.2.3 部署服务步骤与命令
Etcd
|-- 10-storage-class.yaml
|-- 20-storage-volume.yaml // 可按需修改etcd数据存放路径,path: /home/data/etcd_data/data-1
|-- 30-etcd-statefulset.yaml
|-- 40-etcd-service.yaml
|-- etcd_amd64_3.4.3.tar.gz // x64 镜像文件
执行命令:
cd etcd
docker load -i etcd_amd64_3.4.3.tar.gz
kubectl apply -f RabbitMQ
|-- 10-rabbitmq_rbac.yaml
|-- 20-rabbitmq_statefulsets.yaml
|-- 30-rabbitmq_service.yaml
|-- rabbitmq_3.7_amd64.tar.gz // x64 镜像文件
执行命令:
cd rabbitmq
docker load -i rabbitmq_3.7_amd64.tar.gz
kubectl apply -f .kube-watcher(监听状态发送给消息队列)
|-- kube-watcher.yaml
|-- kube_watcher_1.2_amd64.tar.gz // x64 镜像文件
执行命令:
cd service/kube-watcher
docker load -i kube_watcher_1.2_amd64.tar.gz
kubectl apply -f .kube-watcher启动参数说明:
- -namespace : 监听命名空间,默认是pie-engine-job
- -rabbitmq-url :rabbitmq服务地址,默认是 amqp://guest:guest@computing-messagebus.pie-engine-computing:5672/
compute-hub(计算服务,调度执行的job)
前提:修改hub_config.yaml中的minio连接信息,且endpoint 为ip:port形式,不需要添加协议。region不需要指定。
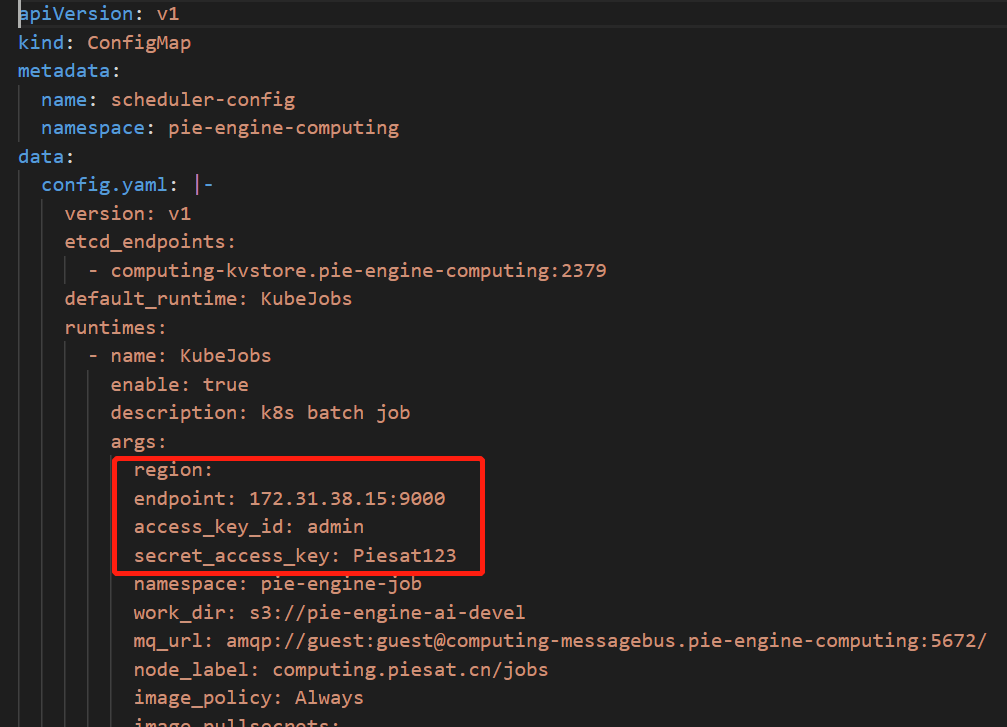
|-- compute-hub.yaml // deployment
|-- hub_config.yaml // configmap,修改configmap中region、endpoint、access_key_id、secret_access_key
|-- compute_hub_3.0_amd64.tar.gz // 镜像文件
执行命令:
cd service/compute-hub
docker load -i compute_hub_3.0_amd64.tar.gz
kubectl apply -f .ConfigMap配置说明:
- etcd_endpoints : etcd连接地址,默认是 computing-kvstore.pie-engine-computing:2379
- KubeJobs运行时配置:
namespace : 任务调度命名空间,默认 pie-engine-job
mq_url : rabbitmq服务地址,默认amqp://guest:guest@computing-messagebus.pie-engine-computing:5672/
node_label : 任务调度节点标签,默认computing.piesat.cn/jobs
5. 样本标注
样本标注平台的说明文档
5.1 k8s管理
命名空间创建:pie-engine-ai
节点标签:engine.node.ai=true
镜像地址模板:仓库地址/pie-engine-ai/业务镜像:版本号
节点共享临时文件路径:/data/resources/engine-application/ai-label/temporary/
5.2 数据库创建
1. 需要提前创建两个数据库:ai-labeling,labeling-vector
2. 在创建的数据中手动执行以下命令
# 需要初始化 CREATE SCHEMA topology; CREATE EXTENSION IF NOT EXISTS postgis WITH SCHEMA public; CREATE EXTENSION IF NOT EXISTS postgis_topology WITH SCHEMA topology;

5.4 project:工程服务
1.修改配置
1.修改 app.yaml中注释的配置 2.修改DockerFile中的基础镜像仓库地址 3.修改install.sh 中的镜像仓库地址2.启动
1. sh install.sh 2.kubectl apply -f service.yaml5.5 sampleset:样本集服务
1.修改配置
1. 修改app.yaml中注释的配置 2. 修改DockerFile中的基础镜像仓库地址 3. 修改install.sh 中的镜像仓库地址2.启动
1. sh install.sh 2.kubectl apply -f service.yaml5.6 samplebase:样本库服务
1.修改配置
1. 修改app.yaml中注释的配置 2. 修改DockerFile中的基础镜像仓库地址 3. 修改install.sh 中的镜像仓库地址2.启动
1. sh install.sh 2.kubectl apply -f service.yaml5.7sampletask:样本任务服务
1.修改配置
1. 修改app.yaml中注释的配置 2. 修改DockerFile中的基础镜像仓库地址 3. 修改install.sh 中的镜像仓库地址2.启动
1. sh install.sh 2.kubectl apply -f service.yaml
5.8 sampletile:样本瓦片服务
1.修改配置
1. 修改app.yaml中注释的配置 2. 修改DockerFile中的基础镜像仓库地址 3. 修改install.sh 中的镜像仓库地址2.启动
1. sh install.sh 2.kubectl apply -f service.yaml
5.9 sectiontile:样本切片服务
1.修改配置
1. 导入基础镜像:tile-section.tar 2. 修改DockerFile中上一步构建的基础镜像地址 3. 修改conf.json中的es和aws的链接信息 4. 给sectiontile文件夹下两个文件执行权限:chmod +x pieEngineAiGridLambda/chmod +x executor 5. 修改并执行install.sh脚本,构建镜像5.10 vectordynamic:矢量动态加载服务
1.修改配置
1. 修改app.yaml中注释的配置 2. 修改DockerFile中的基础镜像仓库地址 3. 修改install.sh 中的镜像仓库地址2.启动
1. sh install.sh 2.kubectl apply -f service.yaml6.算法镜像
python运行的基础镜像,训练解释模块使用的镜像,后处理镜像。
6.1基础镜像列表
harbor的镜像地址:
172.31.1.105:886/pie-engine-ai/pytorch-devel:1.2
172.31.1.105:886/pie-engine-ai/pytorch-devel:1.7.1
172.31.1.105:886/pie-engine-ai/tensorflow-devel:1.13.1
172.31.1.105:886/pie-engine-ai/tensorflow-devel:2.0.0
172.31.1.105:886/pie-engine-ai/tensorflow-devel:2.6.0
172.31.1.105:886/pie-engine-ai/paddlepaddle-devel:2.1.3
172.31.1.105:886/pie-engine-ai/paddlepaddle-devel:2.2.2
172.31.1.105:886/pie-engine-ai/jittor-devel:1.2.2.62
172.31.1.105:886/pie-engine-ai/mindspore-devel:1.5.0
6.3 后处理镜像
为了模型进行解译之后,对结果进行后处理的操作。
- 建筑物规则化:regularization_0_0_8.tar
- 消除小图斑:removespeckles_0_0_1.tar
- geojson转矢量:basic-geojson2vector_1_0_0.tar
- 栅格转矢量:basic-raster2vector_1_1_0.tar
- 矢量入库:vector_postprocessing_private.tar
将镜像docker load -i xx.tar后,设置为harbor上的镜像地址,然后分别修改数据库表中记录。
post_process_tools 中的tool_images 为harbor的ip或者域名/namespace/镜像名称
例:swr.cn-north-4.myhuaweicloud.com/pie-engine-ai-dev/basic-raster2vector:1.1.0修改为
172.31.38.15:886/pie-engine-ai/basic-raster2vector:1.1.0 说明:harobor地址/namespace/imagename
矢量入库操作不同,需添加额外的环境变量,后台启动镜像时添加**datasetParam**参数 矢量入库 参数示例 docker run -it -e AI_DATASET="http://161.189.202.63:30094/pie_training_dataset/" -e datasetParam='{"username":"pieengineai","password":"bGXozqGaJ8kqeefO","url":"121.36.60.187","port":"30052","dname":"pie-engine-ai"}' -e paramJson='{"inputFile":"s3://pie-engine-ai/devel/Zr8Arkjd9Ag7c5SFJzhYL/postProcess/8cc798e7-9279-4231-bd4a-19530a259ae8/output/1_100_pred.shp","task_result_id":"234234234:444","type":1}' 4a519191085a /bin/bash6.4 网络结构与模型库(待补充位置与样式todo)
将网络结构与模型库分别拷贝至对象存储上的相应位置。
7.自主训练平台
功能描述:根据不同类型的数据集,网络结构训练出来的模型,将训练好的模型进行入库。
namespace为pie-engine-ai.
7.1前端服务
前端服务,文件中的服务名称分别是:
- training-nginx,是模型自主训练平台的前端
配置说明
配置先配置后台服务,确保后台服务都启动之后,再启动前端服务。(前端服务代理了后台服务,如果后台服务未启动,可能导致前端服务启动失败)
7.1.2 前端服务
前端,需要配置文件有两个,一个是 preference.json文件,一个是 nginx.conf文件,都在yaml的config.map中。
注:前端访问地址中的子路径不可修改
- 模型自主训练平台: /ai/autolearning
7.1.2.1 preference.json
此文件,每个前端都是需要的。配置内容及解释如下:
{ "sso": "https://sso.piesat.cn", "gateway": "https://janus.piesat.cn", "gwPath": "/gateway/api", "wss": "wss://janus.piesat.cn/websocket", "filePre": "https://pie-engine-ai-obs.piesat.cn" }
- sso: 单点登录域名
- gateway: bpass 网关域名
- gwPath: bpass 网关的默认路径,一般不会修改
- wss: websocket 地址,需要修改域名部分
- filePre: 对象文件的服务域名,此服务指的是存储的文件,以http协议访问时的域名
7.1.2.2 nginx.conf
nginx.conf文件里分两种配置,一种是前端文件所在目录,一种是代理的服务地址。此配置文件绝大部分情况下是不需修改的。
注:preference.json,nginx.conf每个前端的公共配置,根据实际情情况进行配置。
7.1.2.2.1 training-nginx 模型自主训练平台前端
- 其中需要注意的是mapService。 mapService是影像文件预览服务,对应的是image-server这个服务。
worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; client_max_body_size 20000m; sendfile on; keepalive_timeout 65; gzip on; gzip_disable "msie6"; gzip_vary on; gzip_proxied any; gzip_comp_level 6; gzip_buffers 16 8k; gzip_http_version 1.1; gzip_min_length 256; gzip_types application/javascript text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/vnd.ms-fontobject application/x-font-ttf font/opentype image/svg+xml image/x-icon; underscores_in_headers on; server { listen 80; location / { root /data/web/dist/ai/autolearning; index index.html index.htm; } location /mapService { proxy_pass http://image-server.pie-engine-ai:8083/v1; } } }镜像信息
目前提供的存储镜像文件已经导出为tar文件,文件路径为正式环境堡垒机下:/data/ai/tar/*.tar,其中\*代表服务名称
服务名称 | 镜像地址
training-nginx | swr.cn-north-4.myhuaweicloud.com/pie-engine-ai/training-nginx:1.0.4.1
predict-nginx | swr.cn-north-4.myhuaweicloud.com/pie-engine-ai/predict-nginx:1.0.4
deploy-nginx | swr.cn-north-4.myhuaweicloud.com/pie-engine-ai/deploy-nginx:1.0.4
注:镜像地址为harbor的ip或者域名/namespace/镜像名称。
7.2后台服务
7.2.1 jupyter-deploy 部署
服务功能
该服务实现了查询、创建、开始、停止jupyterlab服务的api,供java后端调用。
依赖服务说明
jupyter-deploy服务所需依赖服务较多,包含如下服务,本文档各章节依次对各服务的部署方法进行说明:
- ingress-nginx服务:nginx-jupyter会将请求转发给该服务。用于动态定义访问jupyterlab的转发规则,model-scheduler服务也使用该ingress动态定义调用AI模型的转发规则
- nginx-jupyter服务:接收来自gateway关于jupyter路径的请求,并转发给ingress-nginx服务,调用AI模型也复用该nginx的转发规则
- ai-kvstore服务:AI产品的etcd服务,notebook相关的信息会存储到该etcd中,model-scheduler服务也使用该etcd服务存储模型发布信息
- ai-messagebus服务:AI产品的rabbitmq服务,notebook部署状态变化时会发消息给该mq,java后端training-notebook服务会消费该消息,并更新数据库中相应notebook的状态。model-scheduler服务也使用该rabbitmq服务,通知java后端deploy-model服务更新数据库中相应模型的发布状态。
7.2.1.1 ingress-nginx
1.ingress-nginx镜像上传Harbor
1)解压ai-ingress-nginx.tar.gz镜像压缩包
2)docker load -i 安装解压后的tar文件
3)修改该镜像的tag信息为Harbor的url
4)推送该镜像到Harbor
2.修改YAML配置
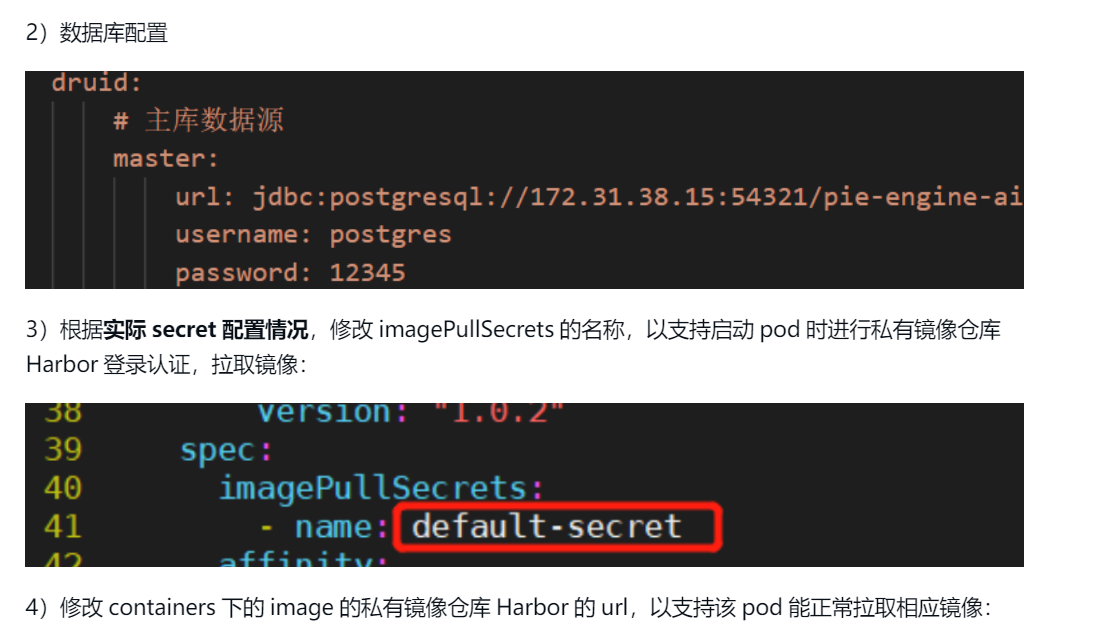
打开image-reader.yaml配置文件,根据私有化部署需求,修改如下配置:
1)根据实际secret配置情况,修改330行imagePullSecrets的名称,以支持启动pod时进行私有镜像仓库Harbor登录认证,拉取镜像:
2)修改333行image的私有镜像仓库Harbor的url,以支持该pod能正常拉取相应镜像:
3.重启服务
执行restart.sh,即可重启该服务,完成服务部署,部署成功查询其状态,在ingress-nginx命名空间下,ingress-nginx-controller的Pod成功运行,如下图所示:
7.2.1.2 nginx-jupyter
1.nginx镜像上传Harbor
1)解压ai-nginx.tar.gz镜像压缩包
2)docker load -i 安装解压后的tar文件
3)修改该镜像的tag信息为Harbor的url
4)推送该镜像到Harbor
2.修改YAML配置
打开nginx.yaml配置文件,根据私有化部署需求,修改如下配置:
1)根据实际secret配置情况,修改19行imagePullSecrets的名称,以支持启动pod时进行私有镜像仓库Harbor登录认证,拉取镜像:
2)修改22行image的私有镜像仓库Harbor的url,以支持该pod能正常拉取相应镜像:
3)配置服务端口以支持访问:
3.重启服务
执行restart.sh,即可重启该服务,完成服务部署,部署成功查询其状态,在pie-engine-ai命名空间下,nginx-jupyter的Pod成功运行,如下图所示:
7.2.1.3 ai-kvstore
1.ai-etcd镜像上传Harbor
1)解压ai-etcd.tar.gz镜像压缩包
2)docker load -i 安装解压后的tar文件
3)修改该镜像的tag信息为Harbor的url
4)推送该镜像到Harbor
2.修改YAML配置
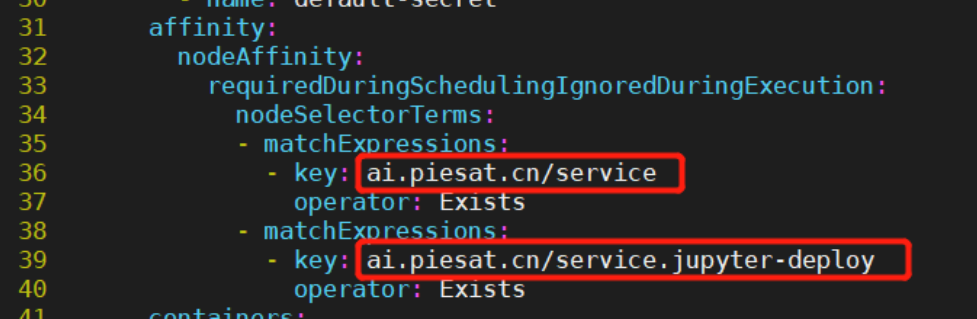
打开20-storage-volume.yaml配置文件,根据私有化部署需求,修改如下配置:
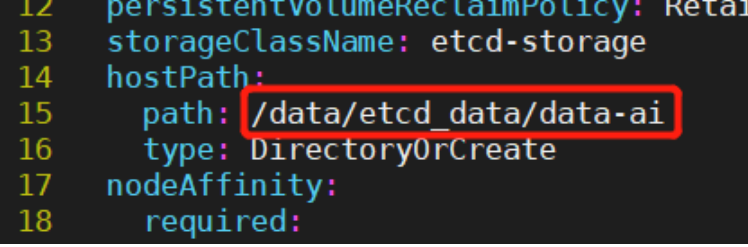
1)根据实际需要存储etcd数据库的路径,修改15行hostPath的path,指定PV在宿主机的存储路径:
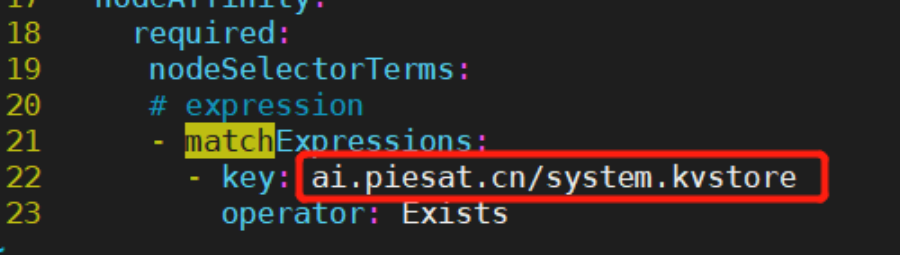
2)根据实际节点标签配置情况,修改22行nodeAffinity相关匹配规则,以支持该PV能正常被调度到指定节点:
打开30-etcd-statefulset.yaml配置文件,根据私有化部署需求,修改如下配置:
3)修改156行image的私有镜像仓库Harbor的url,以支持该pod能正常拉取相应镜像:
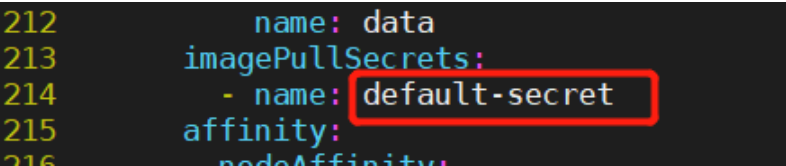
4)根据实际secret配置情况,修改214行imagePullSecrets的名称,以支持启动pod时进行私有镜像仓库Harbor登录认证,拉取镜像:
5)根据实际节点标签配置情况,修改221行nodeAffinity相关匹配规则,以支持该pod能正常被调度到指定节点
3.重启服务
执行restart.sh,即可重启该服务,完成服务部署,部署成功查询其状态,在pie-engine-ai命名空间下,ai-kvstore的Pod成功运行,如下图所示:
7.2.1.4 ai-messagebus
1.ai-rabbitmq镜像上传Harbor:
1)解压ai-rabbitmq.tar.gz镜像压缩包
2)docker load -i 安装解压后的tar文件
3)修改该镜像的tag信息为Harbor的url
4)推送该镜像到Harbor
2.修改YAML配置:
打开20-rabbitmq_statefulsets.yaml配置文件,根据私有化部署需求,修改如下配置:
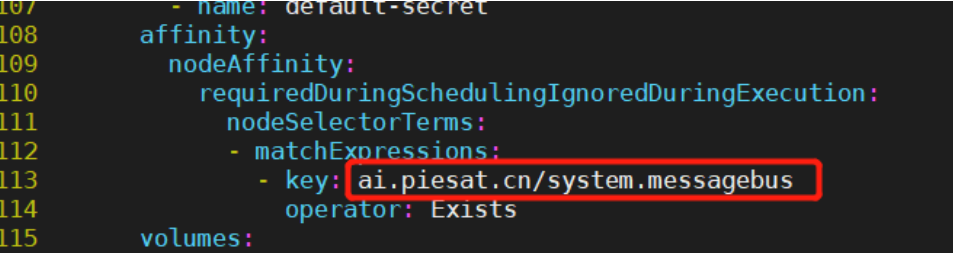
1)修改67行image的私有镜像仓库Harbor的url,以支持该pod能正常拉取相应镜像:









3.重启服务:
执行restart.sh,即可重启该服务,完成服务部署,部署成功查询其状态,在pie-engine-ai命名空间下,ai-messagebus的Pod成功运行,如下

7.2.1.5 jupyter-deploy
1.相关镜像上传Harbor
1)解压jupyter-deploy-v2.tar.gz镜像压缩包
2)docker load -i 安装解压后的tar文件
3)修改该镜像的tag信息为Harbor的url
4)推送该镜像到Harbor
5)jupyter-lab-cpu-v2、jupyter-lab:gpu-v2、jupyter-sync-v1.0.1镜像压缩包解压并load后,直接推送到Harbor
6)jupyter-sync-v1.0.1镜像重编译,目的在于修改原jupyter-sync镜像中的minio配置。
解压jupyter-sync重编译.tar,首先修改rclone.conf,将13-16行修改为对应的minio配置信息,然后修改Dockerfile及build-sync.sh中的镜像tag,运行build-sync.sh即可
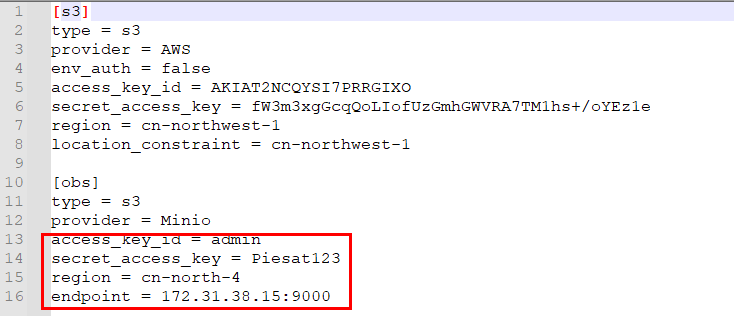
2.修改YAML配置
打开jupyter-deploy.yaml配置文件,根据私有化部署需求,修改如下配置:
1)修改43行image的私有镜像仓库Harbor的url,以支持该pod能正常拉取相应镜像:


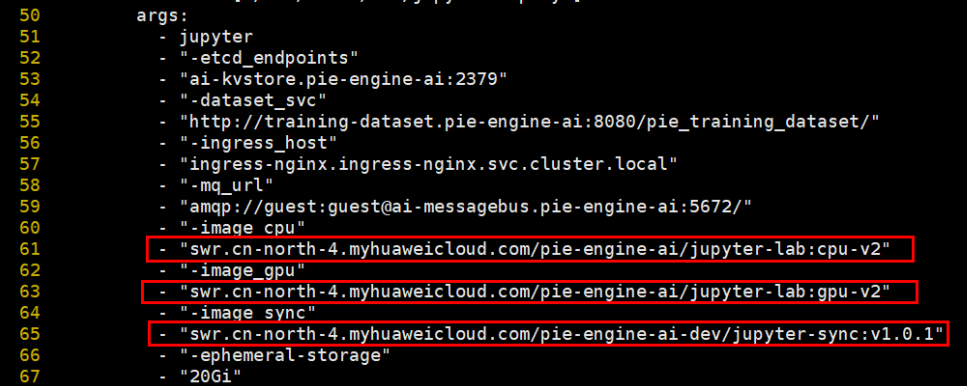

3.重启服务
执行restart.sh,即可重启该服务,完成服务部署,部署成功查询其状态,在pie-engine-ai命名空间下,jupyter-deploy的Pod成功运行,如下图所示:

7.2.2 业务服务板块
7.2.2.1 部署通用步骤
1.镜像上传私有镜像仓库Harbor:
1) 解压对应组件的镜像压缩包
2) docker load -i 安装解压后的tar文件
3) 修改该镜像的tag信息为Harbor的url
4) 推送该镜像到Harbor
5) 新建挂载目录,与业务组件平级,便于后续组件涉及挂载统一管理。部署人员可以根据实际情况设置。
在共享文件存储/data/pie_data/wuhan_pie_ai/data下面新加/ai/mounts/
/data/pie_data/wuhan_pie_ai/data/ai/mounts/
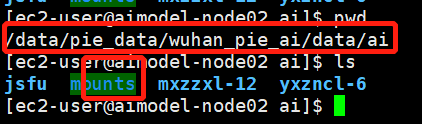
2.修改YAML配置
打开响应组件的yaml配置文件,根据私有化部署的要求,修改如下配置:
2.1通用的配置修改
1)minio对象存储服务的连接配置信息,region可以不用输入。例:region:
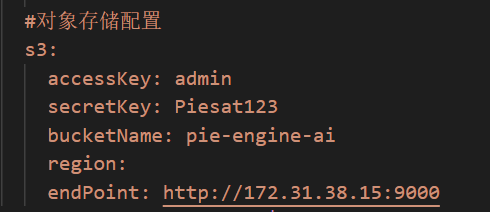

7.2.2.2服务组件相关的配置
7.2.2.2.1 resouce-usage(用户资源)
仅保留资源信息的当前使用资源查询,存储和流量信息查询。
参照6.2.4.1中通用的配置即可。
7.2.2.2.2 S3-utils文件上传与下载
前提需要加载镜像obejct-delete和uploadzip(引用的jar包),将tar加载为镜像,在重启启动s3-util的服务
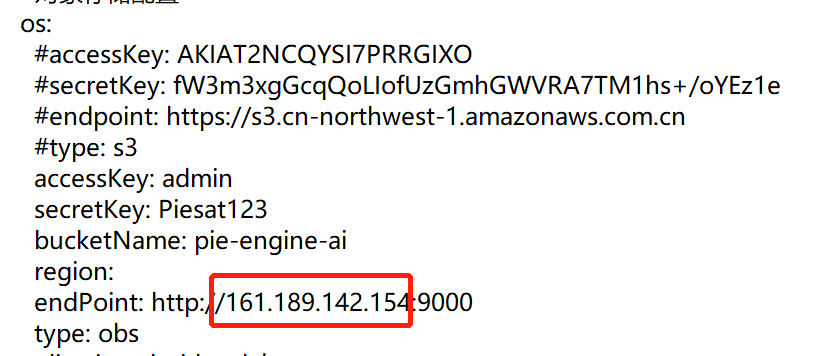
1)S3中的minio需要配置为外网ip:
原因:S3Util的那个服务的minio地址配成外网的,逻辑是后台返回一个链接给前端,前端去上传,所以必须是外网才可以访问的。

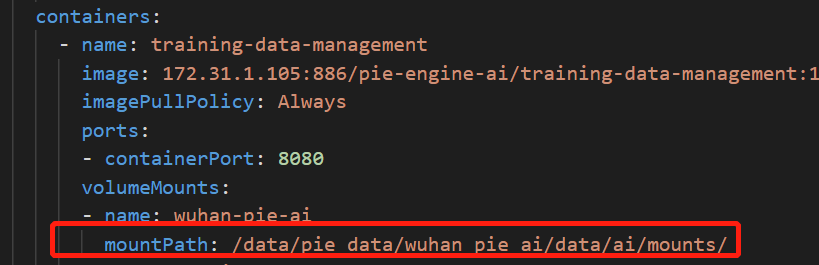
7.2.2.2.3 training-data-management训练数据集
1)批量删除镜像,修改为harbor地址

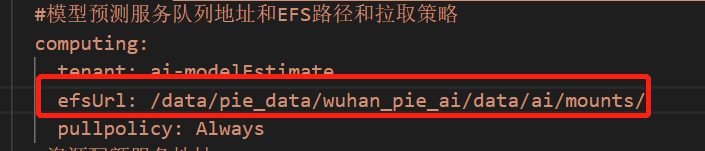
7.2.2.2.4 training-model 训练模型
1)挂载地址
7.2.2.2.5 training-network 网络结构
参照7.2.3.1部署通用步骤配置即可
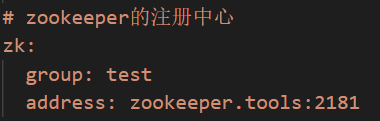
7.2.2.2.6 training-news 消息
前提需提前构建accout-ai,服务,提供dubbo接口,供动态服务平台获取用户账号信息信息。
1)修改zookeeper
7.2.2.2.7 training-notebook
1) 部署节点
私有化部署的时候,创建notebook的时候前端传值的deployType不能设置为1,直接使用私有部署服务器中剩余的资源节点来创建资源运行notebook。
2)配置jupyter访问路径
修改54行配置的url,url为6.2.2.2 nginx-jupyter的访问url
7.2.2.2.8 training-project
参照6.2.4.1中通用的配置即可。
7.2.2.2.9 training-sample
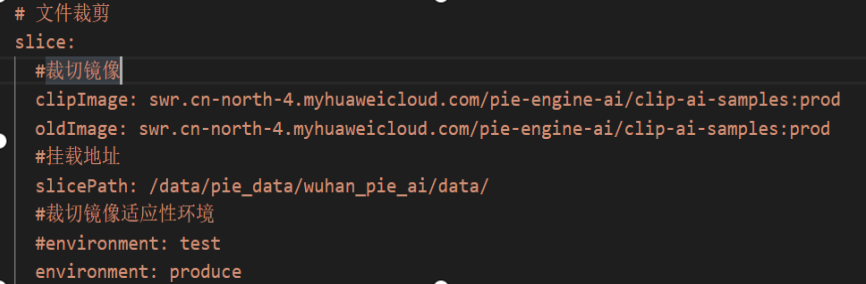
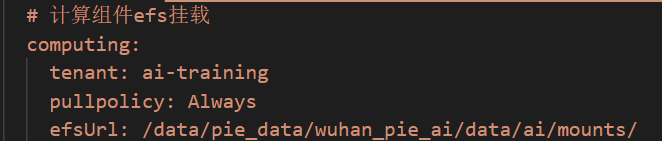
1)文件剪裁的镜像
截图为样例,具体镜像名称根据实际情况来写


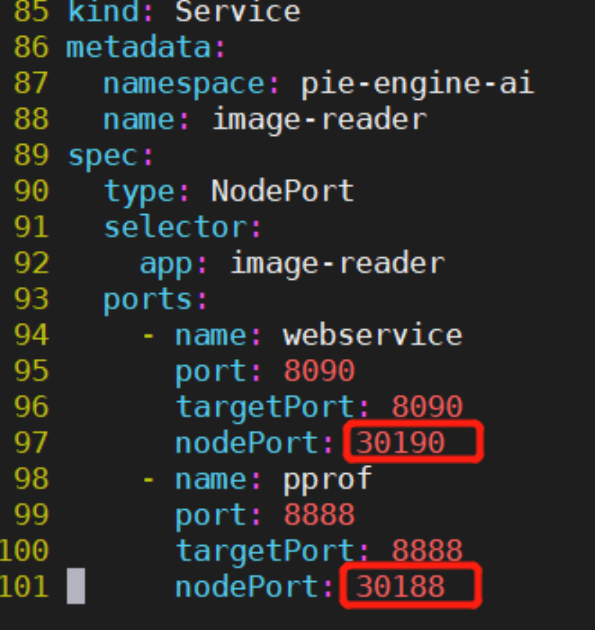
7.2.2.1.11 image-reader 样本切片浏览服务
服务功能
该服务实现了对s3/minio上遥感影像进行处理的功能。并提供一个api接口,接收相关输入参数,返回处理后的图片二进制流给客户端。
部署文件
- k8s部署yaml文件:定义了服务的configmap、deployment及service的配置信息
- 包含镜像tar.gz文件:包含了相应服务的镜像压缩包
- restart.sh文件:重启该服务的脚本,会先停掉当前deployment,再重新启动
部署流程
1.镜像上传私有镜像仓库Harbor
1)解压image-reader镜像压缩包
2)docker load -i 安装解压后的tar文件
3)修改该镜像的tag信息为Harbor的url
4)推送该镜像到Harbor
2.修改YAML配置
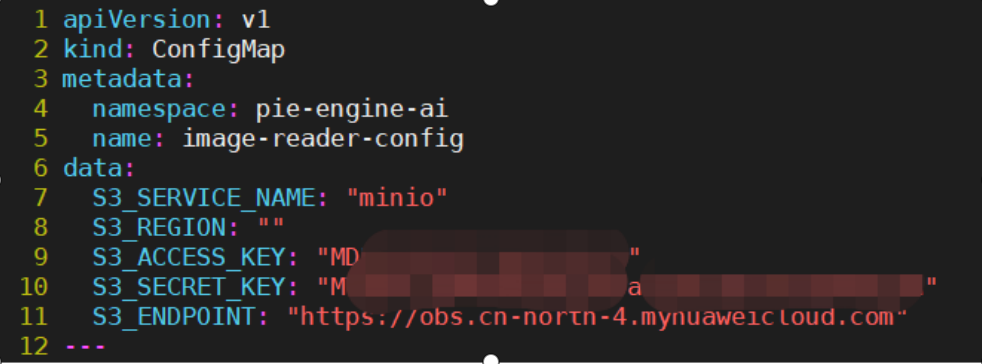
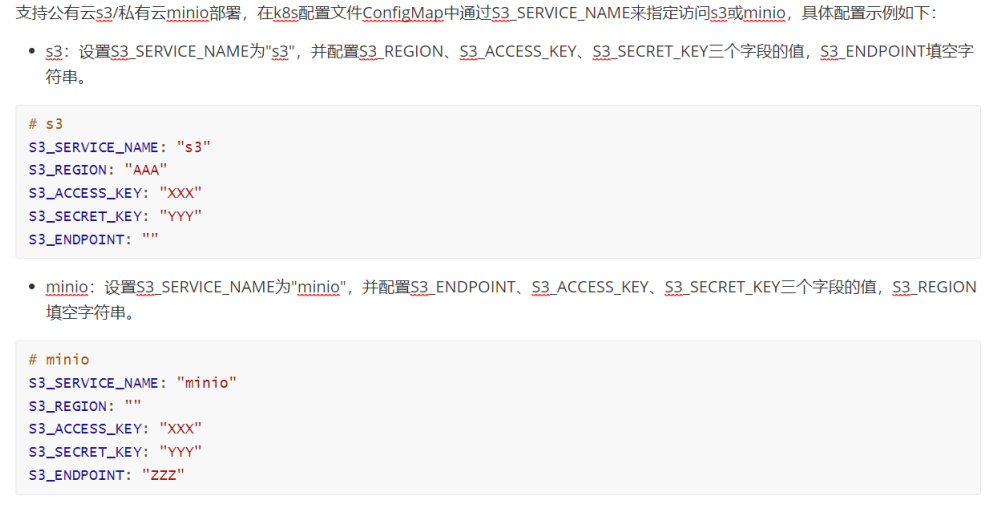
打开image-reader.yaml配置文件,根据私有化部署需求,修改如下配置:
1)修改7到11行ConfigMap中对象存储服务的连接配置信息,以支持image-reader服务访问对应对象存储服务上的图片:


8. 智能处理平台
8.1前端服务
公共的配置文件preference.json,nginx.json见7.1前端服务处。
再根据实际情况修改如下配置
注:前端访问地址中的子路径不可修改
- 影像智能处理平台: /ai/modelpredict
8.1.1 predict-nginx 影像智能处理平台前端
其中需要注意的是mapService,shpService,queryService。
- – mapService是影像文件预览服务,对应的是image-server这个服务。
- – shpService是shp矢量预览服务,对应vector-service中的view
- – queryService是shp矢量查询服务,对应vector-service中的query
- – querylog是影像文件预览服务,用来查看数据集相关任务信息的,暂时不用管。
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
client_max_body_size 20000m;
sendfile on;
keepalive_timeout 65;
gzip on;
gzip_disable "msie6";
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_min_length 256;
gzip_types application/javascript text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/vnd.ms-fontobject application/x-font-ttf font/opentype image/svg+xml image/x-icon;
underscores_in_headers on;
server {
listen 80;
location / {
root /data/web/dist;
index index.html index.htm;
try_files $uri $uri/ /;
}
location /mapService {
proxy_pass http://image-server.pie-engine-ai:8083/v1;
}
location /shpService {
proxy_pass http://vector-view.pie-engine-ai:8081/pie-engine/vector/dynamic/tiles;
}
location /queryService {
proxy_pass http://vector-query.pie-engine-ai:8081/api/v1/vector/feature/records;
}
#location /querylog {
# proxy_pass http://s3-utils.pie-engine-ai:8080/s3/method/getV3infolog;
# proxy_cookie_path /getV3infolog /querylog;
#}
}
}8.2后台服务
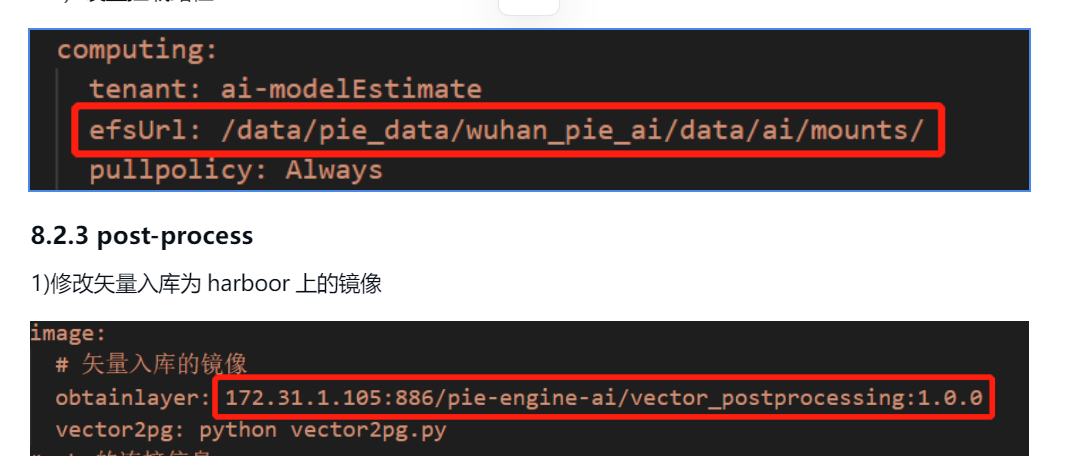
8.2.1 model-estimate模型解译
1)设置挂载路径
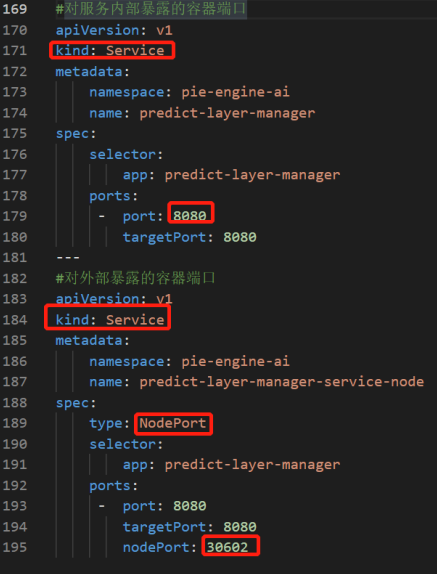
8.2.3 predict-layer-manager
修改6.2.4.1中的通用配置即可。
8.2.4 image-server,vector-service
- 后台服务三个,分为两类:
- image-server 为影像文件预览服务
- vector-service 是shp矢量相关服务
- query 为 shp 矢量查询服务
- view 为 shp 矢量预览服务
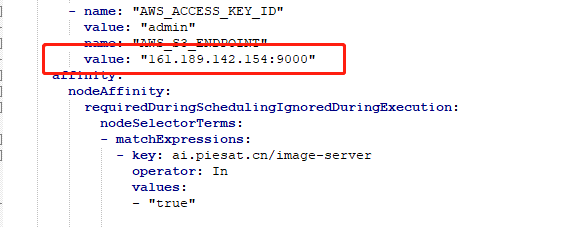
后台服务一般有两个yaml,其中一个是deployment的yaml,另一个是service服务的yaml,因前端代理了这些服务,为避免重启的影响,把service和deployment拆分开。8.2.4.1 image-server
影像文件预览服务,需要配置对象存储相关信息,具体位置在deployment的yaml中env附近。
注:image-server.yaml 不能有http,只能直接配置minio的ip:port
env:
- name: "AWS_REGION"
value: "******"
- name: "AWS_SECRET_ACCESS_KEY"
value: "******"
- name: "AWS_ACCESS_KEY_ID"
value: ""******""
- name: "AWS_S3_ENDPOINT"
value: ""******""
8.2.4.2 vector-service
shp矢量预览和查询服务,只需要修改数据库连接的相关信息,其他配置不可修改,具体位置在deployment的yaml中。
- query服务中的vector-query.yaml
spring.datasource.url=jdbc:postgresql://*ip:port*/pie-engine-ai?useSSL=false
spring.datasource.username=*username*
spring.datasource.password=*password*- view服务中的vector-view.yaml
#设置数据库连接信息
spring.datasource.url=jdbc:postgresql://*ip:port*/pie-engine-ai
spring.sql.init.platform=postgres
spring.datasource.username=*username*
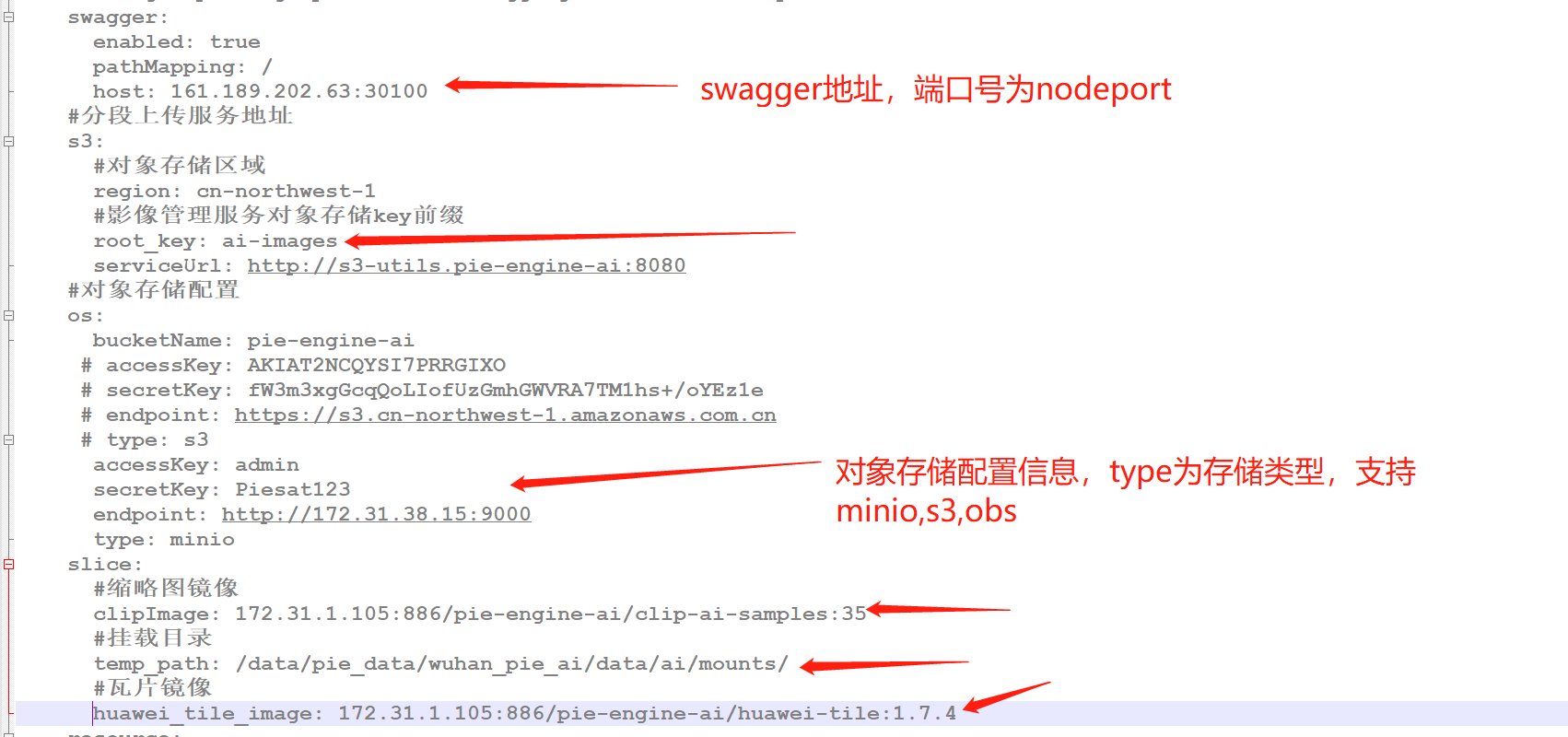
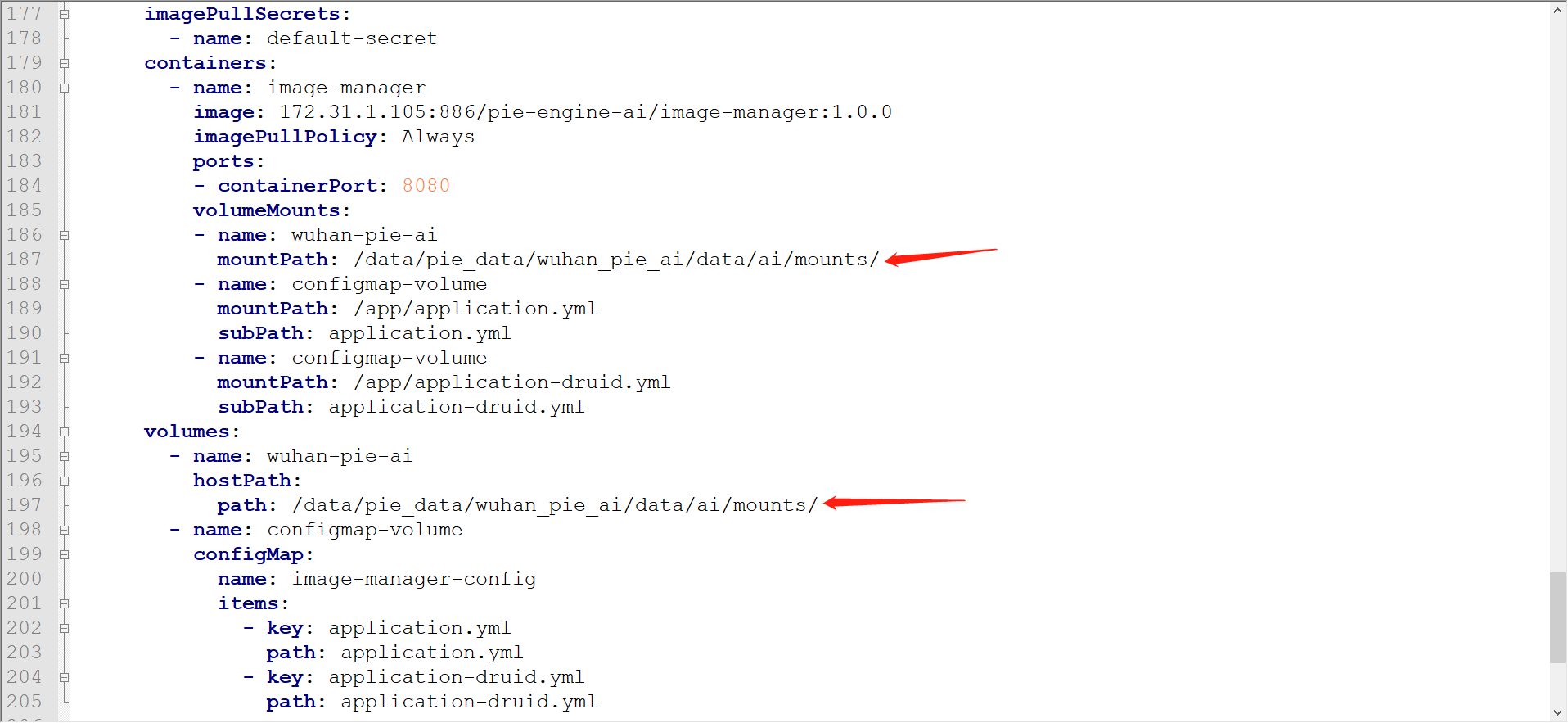
spring.datasource.password=*password*8.2.5 image-manager(影像管理与目录)
1)镜像以及基础配置

9.模型部署平台(暂不涉及)
9.1前端服务
注:前端访问地址中的子路径不可修改
- 模型部署平台: /ai/modeldeploy
- 样本协同标注平台: /ai/samplelabel 此服务不在此处管理
公共的配置文件preference.json,nginx.json见7.1前端服务处。
再根据实际情况修改如下配置
9.1.1 deploy-nginx 模型部署发布平台前端(暂不涉及)
不需要修改
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
client_max_body_size 20000m;
sendfile on;
keepalive_timeout 65;
gzip on;
gzip_disable "msie6";
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_min_length 256;
gzip_types application/javascript text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/vnd.ms-fontobject application/x-font-ttf font/opentype image/svg+xml image/x-icon;
underscores_in_headers on;
server {
listen 80;
location / {
root /data/web/dist;
index index.html index.htm;
try_files $uri $uri/ /;
}
}
} 9.2后台服务
六、部署验证
输入:pie_ai/123456 ,登录成功并且功能可用则部署成功。
七、遇到的问题与困难
7.1minio部署
docker搭建minio集群环境_小马驹爱草原的博客-CSDN博客_docker minio 集群
s3:
accessKey: admin #yaml文件中enviroment中的minio_access_key
secretKey: Piesat123 #yaml中的minio_secret_key
bucketName: pie-engine-ai #桶信息
region: #不填或随便
endPoint: http://172.31.38.15:9000 #内网/外网的ip:port (server的端口) 计算服务不能书写http协议
原文地址:http://www.cnblogs.com/xiaozgang/p/16813257.html