
资源:b站
本系列课程主要是启发为主,不会介绍很多很多的算法,适合初学者。
一、学习资源
书籍:

国际会议:
International Conference on Data Mining
International Conference on Data Engineering
International Conference on Machine Learning
International Joint Conference on Artificial Intelligence
Pacific-Asia Conference on Knowledge Discovery and Data Mining
ACM SIGKDD Conference on Knowledge Discovery and Data Mining
期刊:

学术领头人举例:

搜索引擎和软件:
不要闭门造车,闷头看书,要时常到外面看一看,你做的一些东西可能有人以前早就做过。
二、怎么学好这门课程
上课思考讨论,课后【动手】练习,找一些数据做一下比单纯听课有用。
三、数据寻找


四、从数据到智能
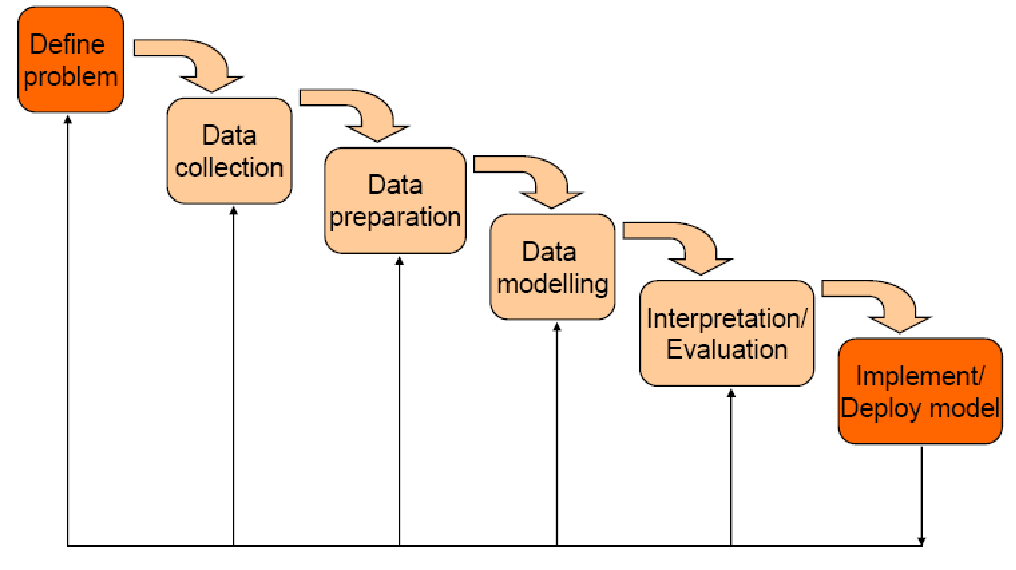
数据是最底层的东西,数据通过处理成为信息,信息处理后成为知识,知识加工后成为decision support
通常数据存放在不同的数据源中,所有数据进行融合(ETL),装在数据仓库中,再去做分析。
从抽象层面看,流程如图所示:
五、分类问题
1、Given a training set: {(x1, y1), …, (xn, yn)}, produce a classifier (function) that maps any unknown object xi to its class label yi.(给一些训练集训练模型,再来一些未知的数据集可以做预测)
2、分类问题包括的一些算法:决策树、KNN、神经网络、支持向量机,以后慢慢介绍
3、classification说白了就是一个分界面问题,把n维空间中的一个点划分到不同的空间
4、做分类的时候数据要分成两部分,一部分是training set用来生成训练模型,另一部分是test set用来检测,检测结果不好要重新训练。training set和test set不能完全重合的
5、混淆矩阵confusion matrix
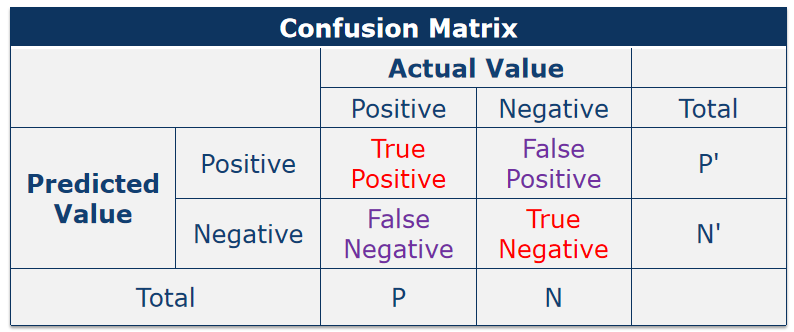
假设两分类问题,一类是正类positive,另一类是negative
TP指的是样本本身是positive,预测为positive
FP指的是样本本身是negative,预测为positive
FN指的是样本本身是positive,预测为negative
TN指的是样本本身是negative,预测为negative
模型的准确率accuracy=(TP+TN)/(P+N)
TPR=TP/(TP+FN)
TNR=TN/(TN+FP)
6、ROC曲线
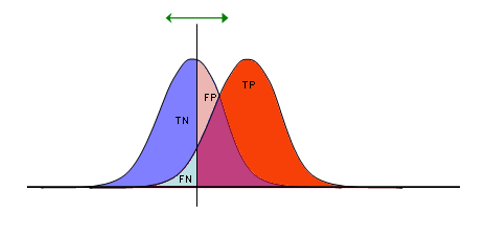
这个图可以解释为男人、女人和身高
横坐标是身高,两个高斯代表男人和女人,通常来讲男人比女人高,但是这不是绝对的,中间这条线就是阈值。
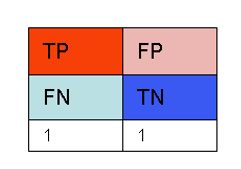
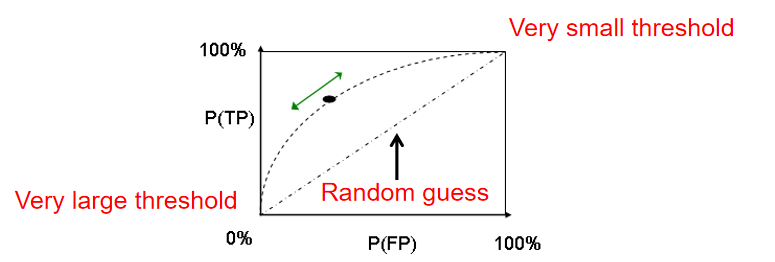
如果说阈值设置的特别小,比如设置为一米,宏观上所有男人身高都会超过一米,所以所有男人都会被预测为男人,即TP为100%,但是所有女人也会被预测为男人,即FN为100%,对应右上角那个点;
如果说阈值设置的特别大,比如设置为三米,宏观上所有女人身高都不超过三米,所以所有女人都会被预测为女人,即FP为100%,但是所有男人也会被预测为女人,即TN为100%,对应左下角那个点。
阈值在最大和最小之间滑动的时候对应的就是曲线,理论上曲线越高越好,怎么衡量这条曲线好?人们定义了一个AUC,就是曲线下方的面积,AUC越高越好。
7、在混淆矩阵中有两种错误:FP和FN,把男人判定为女人和把女人判定为男人,但是在实际应用中,两种错误造成的危害可能不一样,比如把有病的人判定为没病,把没病的人判定为有病等等。所以在实际应用中,所有问题都是带权重的。
六、聚类及其他数据挖掘问题
1、Clustering is the assignment of a set of observations into subsets (called clusters) so that observations in the same cluster are similar in some sense.(分成一组一组的)
2、聚类和分类的区别?聚类中是没有标签的,这是跟分类的区别,分类是监督学习,聚类是无监督学习
3、怎么样衡量两个点远近,相似不相似之类的东西?要靠距离度量,比如,欧式距离,曼哈顿距离,马氏距离
4、算法比如,K-Means ,Sequential Leader, Affinity Propagation
七、关联规则
商店购物,买了某种物品的有可能会买另一种东西
八、回归
线性回归中线性是指参数和变量之间是线性的(x和y是线性的),不是指拟合出来的线是线性的。(不一定拟合出来是直线,也可以是曲线等等)
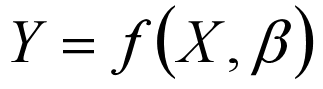
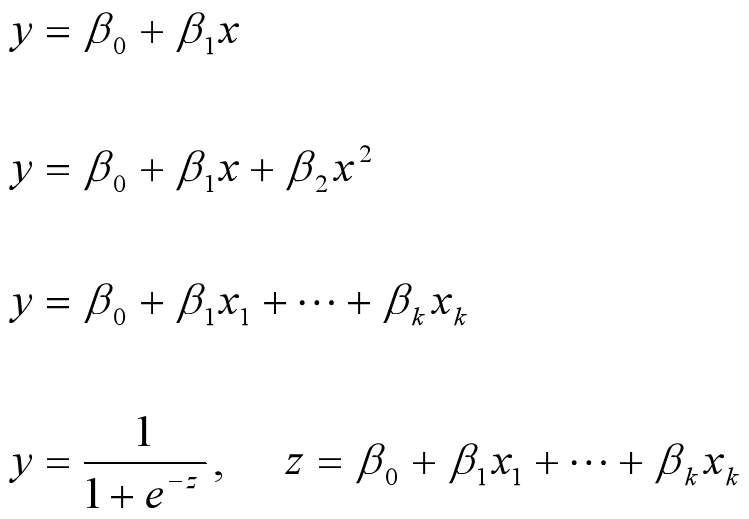

九、数据预处理
实际数据挖掘过程中,最麻烦的就是数据预处理步骤
问题:Missing Attribute Values,Different Coding/Naming Schemes,Infeasible Values,Inconsistent Data,Outliers
操作:后面介绍
原文地址:http://www.cnblogs.com/jiezstudy/p/16925902.html